Baixar para ler offline


![#NoSQLMistakes @leomrlima @otaviojava
About the Speakers
Leonardo Lima
• Computer engineer, server & embedded sw developer
• From São Paulo, Brasil, currently in Austin, TX
• CTO at V2COM
• Spec Lead – JSR363 – Units of Measurement
• Representative at JCP Executive Committee & Eclipse IoT
[about.me/leomrlima]](https://image.slidesharecdn.com/top9mistakestoavoidwhendevelopingwithnosqltogo-180720181849/85/Top-9-mistakes-to-avoid-when-developing-with-NoSQL-2-320.jpg)
![#NoSQLMistakes @leomrlima @otaviojava
Otávio Santana
• Software engineer, Tomitribe
• Java & Oracle Dev Champion, SouJava JUG Leader
• Apache, Eclipse and OpenJDK Committer
• Expert Group member in many JSRs
• Representative at JCP EC for SouJava
About the Speakers
[about.me/otaviojava]](https://image.slidesharecdn.com/top9mistakestoavoidwhendevelopingwithnosqltogo-180720181849/85/Top-9-mistakes-to-avoid-when-developing-with-NoSQL-3-320.jpg)




![#NoSQLMistakes @leomrlima @otaviojava
#2: Documentos NoSQL não são PDFs!
“Preciso guardar [INSIRA TIPO DE DADO AQUI], vou utilizar
MongoDB!”
“Já recebemos os dados como JSON, só guardar na base!”
“Qual é o problema de guardar CLOB na base?”](https://image.slidesharecdn.com/top9mistakestoavoidwhendevelopingwithnosqltogo-180720181849/85/Top-9-mistakes-to-avoid-when-developing-with-NoSQL-8-320.jpg)











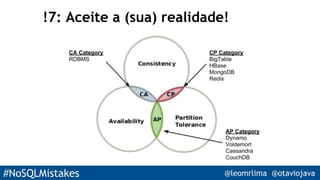
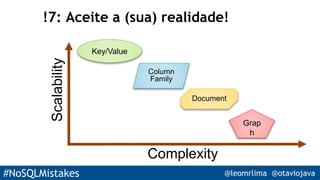








O documento apresenta 9 erros comuns ao desenvolver com bancos de dados NoSQL. São eles: 1) escolher NoSQL sem entender suas características; 2) tratar documentos como PDFs ao invés de entender seus conceitos; 3) indexar todas as colunas como em bancos SQL; 4) fazer queries como em SQL; 5) não separar modelos de leitura e escrita; 6) acreditar cegamente em benchmarks; 7) não considerar os trade-offs de consistência vs escalabilidade; 8) usar ORM sem entendê-lo; 9) se encantar pela


![JavaOne 2017 - Collections.compare:JDK, Eclipse, Guava, Apache... [CON1754]](https://cdn.slidesharecdn.com/ss_thumbnails/j12017collectionscomparecon1754-171005182614-thumbnail.jpg?width=640&height=640&fit=bounds)





![The First IoT JSR: Units of Measurement JSR-363 [BOF5981]](https://cdn.slidesharecdn.com/ss_thumbnails/j1-2016-bof5981-jsr363-160927112830-thumbnail.jpg?width=640&height=640&fit=bounds)
![Using Java and Standards for Fast IoT Development [CON5513]](https://cdn.slidesharecdn.com/ss_thumbnails/j1-2016-con5513-fast-iot-160927112622-thumbnail.jpg?width=640&height=640&fit=bounds)
![IoT Security: Cases and Methods [CON5446]](https://cdn.slidesharecdn.com/ss_thumbnails/j1-2016-con5446-security-160927112335-thumbnail.jpg?width=640&height=640&fit=bounds)
![Secure IoT with Blockchain: Fad or Reality? [BOF5490]](https://cdn.slidesharecdn.com/ss_thumbnails/j1-2016-bof5490-iot-blockchain-160927112314-thumbnail.jpg?width=640&height=640&fit=bounds)
![Building a Reliable Remote Communication Device with Java ME8 [CON2285]](https://cdn.slidesharecdn.com/ss_thumbnails/buildingareliableremotecommunicationdevicewithjavame8con2285-141010075916-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
