Transferir como PDF, PPTX















![DS/ML/DL over a Lakehouse
§ ML frameworks already support reading Parquet, ORC, etc.
§ New declarative interfaces for I/O enable further optimization
§ Example: Spark DataFrame API
compiles to relational algebra
...
model.fit(train_set)
Lazily evaluated queryplan
Optimized execution using
cache, statistics, index, etc
users
SELECT(kind = “buyer”)
PROJECT(date, zip, …)
PROJECT(NULL → 0)
users = spark.table(“users”)
buyers = users[users.kind == “buyer”]
train_set = buyers[“date”, “zip”, “price”]
.fillna(0)
User program
client library](https://image.slidesharecdn.com/futureofdatascienceml-210210181632/75/The-Future-of-Data-Science-and-Machine-Learning-at-Scale-A-Look-at-MLflow-Delta-Lake-and-Emerging-Tools-25-2048.jpg)










The document discusses the evolution and future of data management, focusing on the 'lakehouse' paradigm, which integrates benefits of data lakes and warehouses to simplify data architecture. It highlights challenges faced by data professionals regarding data quality, timeliness, and scalability, alongside solutions provided by technologies like Delta Lake and MLflow for enhanced analytics. The content emphasizes the importance of centralized model management in machine learning development and the role of MLflow in facilitating this process.
Overview of the future of Data Science/ML with Lakehouse, Delta Lake, and MLflow at Databricks.
Outline of the presentation covering data problems, Lakehouse paradigm, Delta Lake, and MLflow.
Databricks is a cloud platform for analytics, processing exabytes of data daily with over 7000 customers.
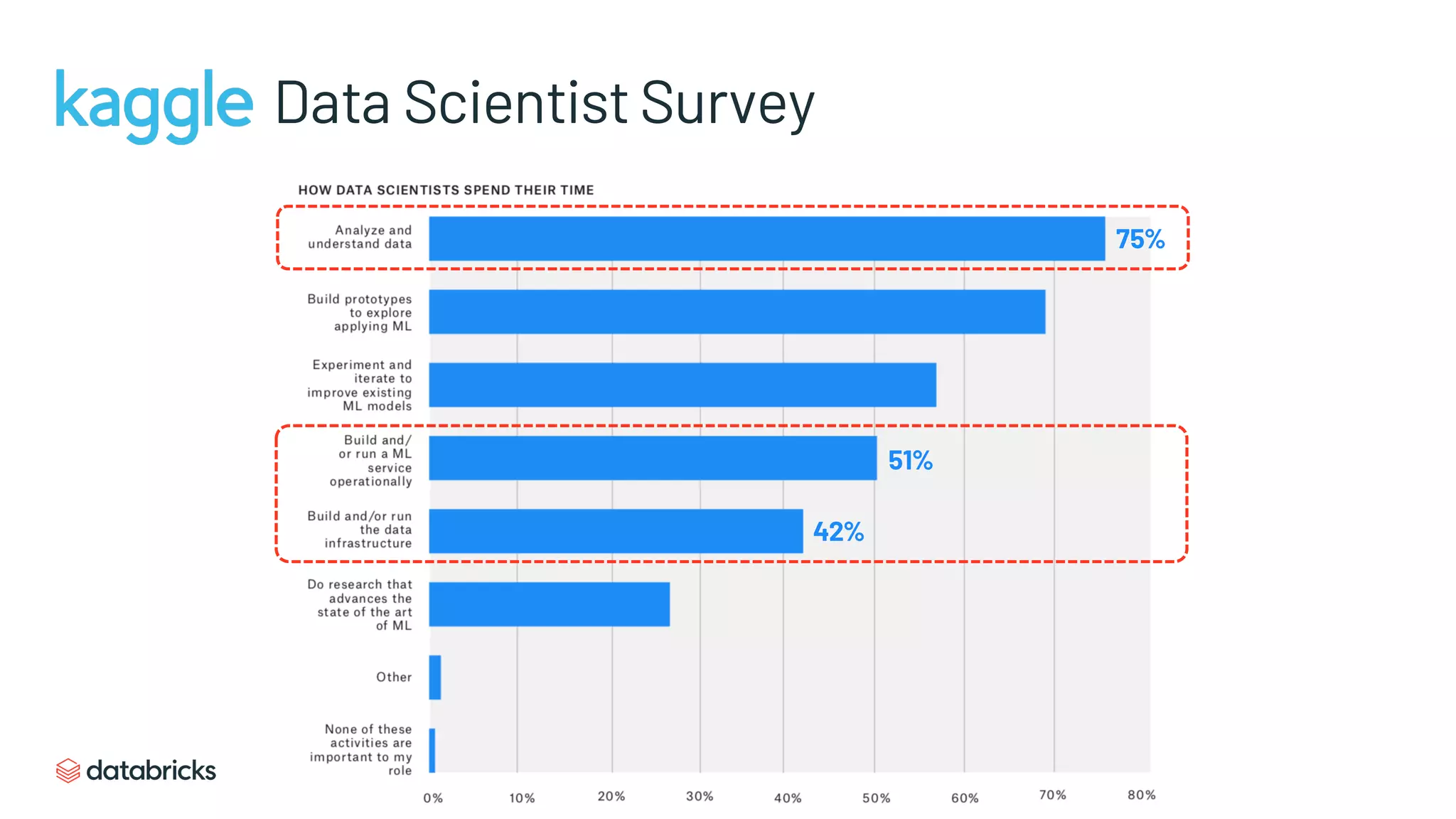
Key data challenges include quality, staleness, volume, and scale, affecting analytics post-2020.
Survey reveals 60% of analysts face data quality issues; 86% use stale data, with 90% citing unreliable sources.
Data Science survey results focusing on challenges and importance of data quality.
Obtaining timely, high-quality data is complex and requires addressing internal issues.
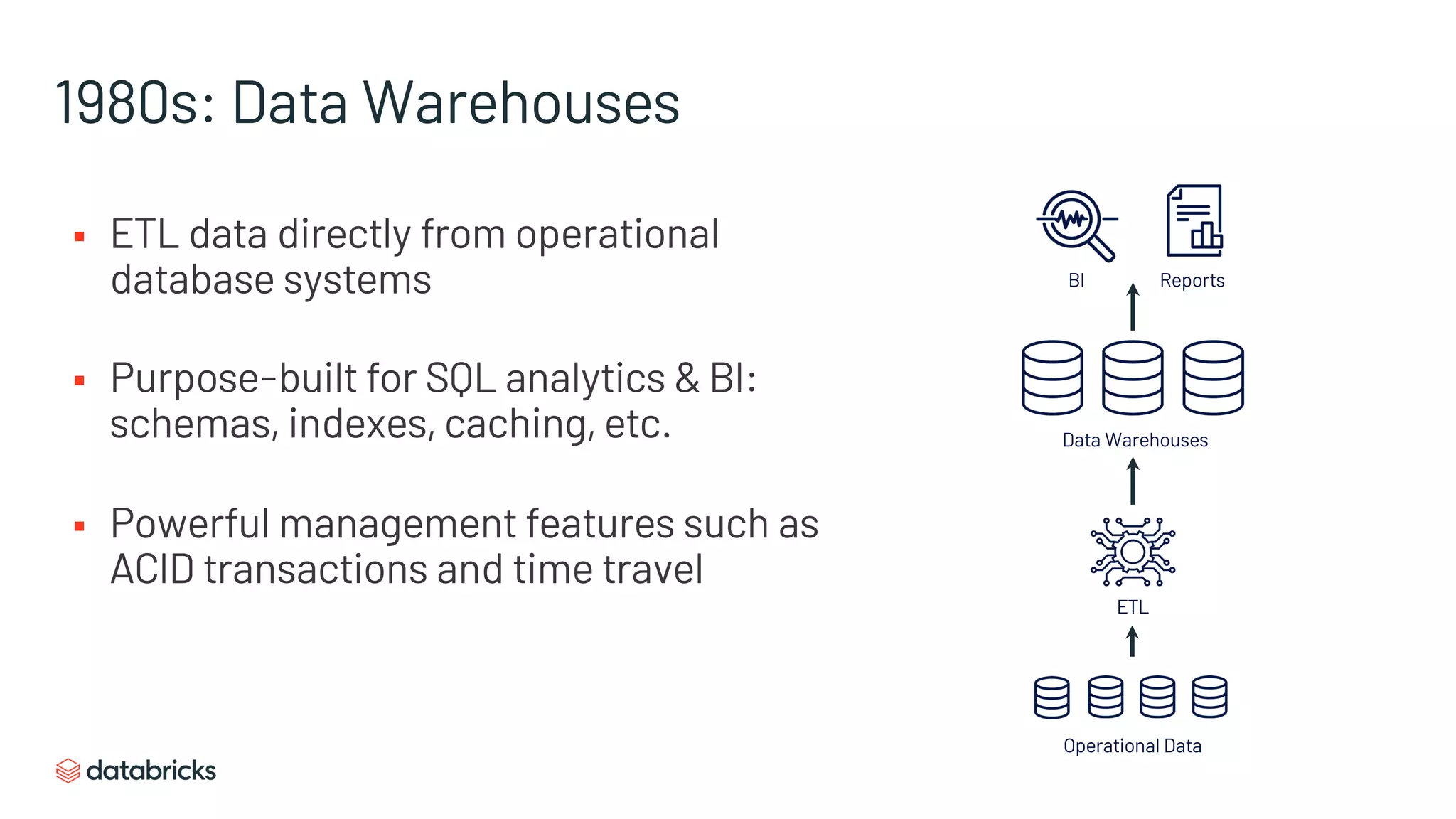
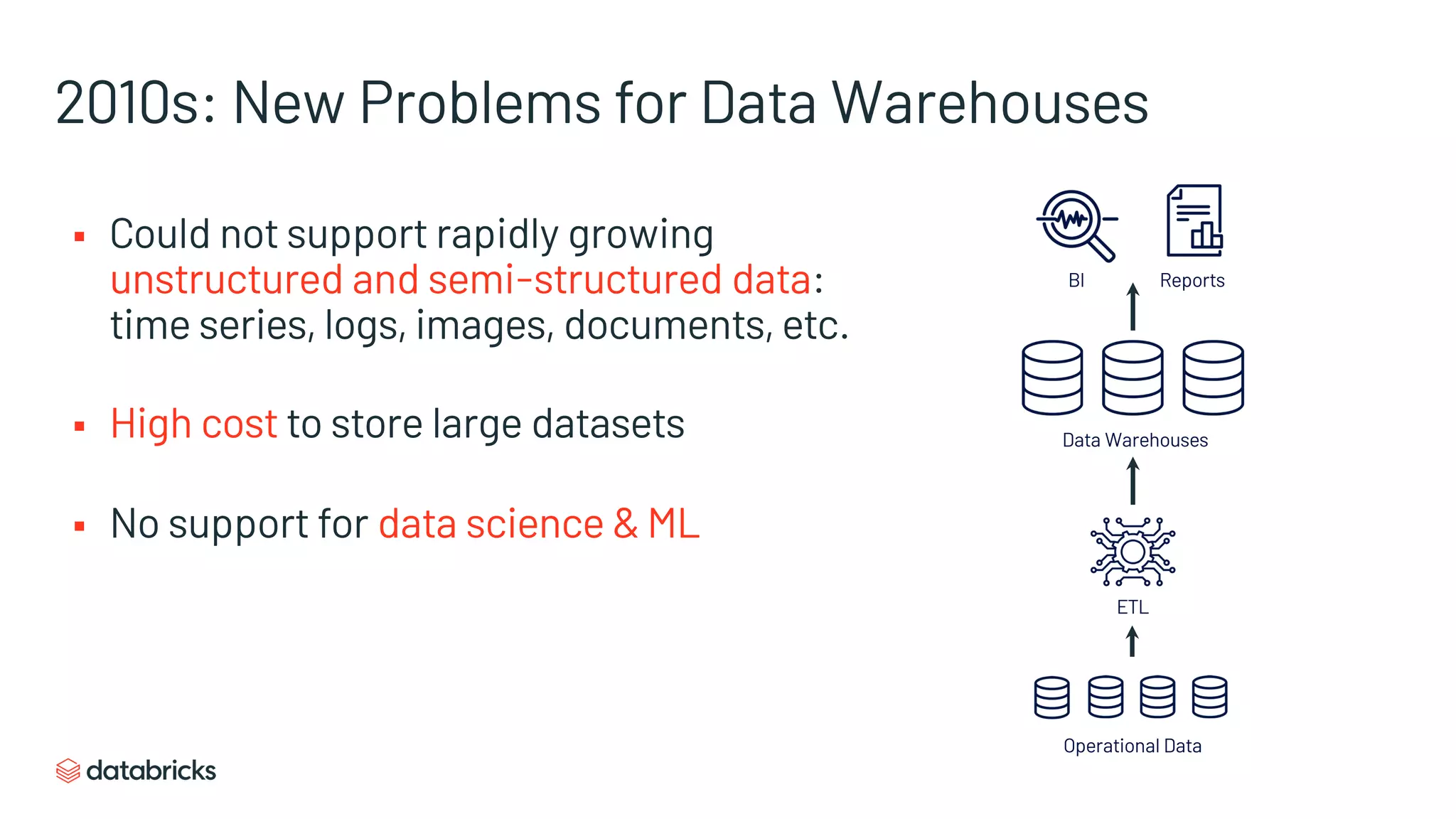
Historical context and transition from traditional data warehouses to modern data architectures.
ETL practices, structure, and features of data warehouses designed for SQL analytics and BI.
Challenges of data warehouses in the 2010s, including high costs and inability to handle unstructured data.
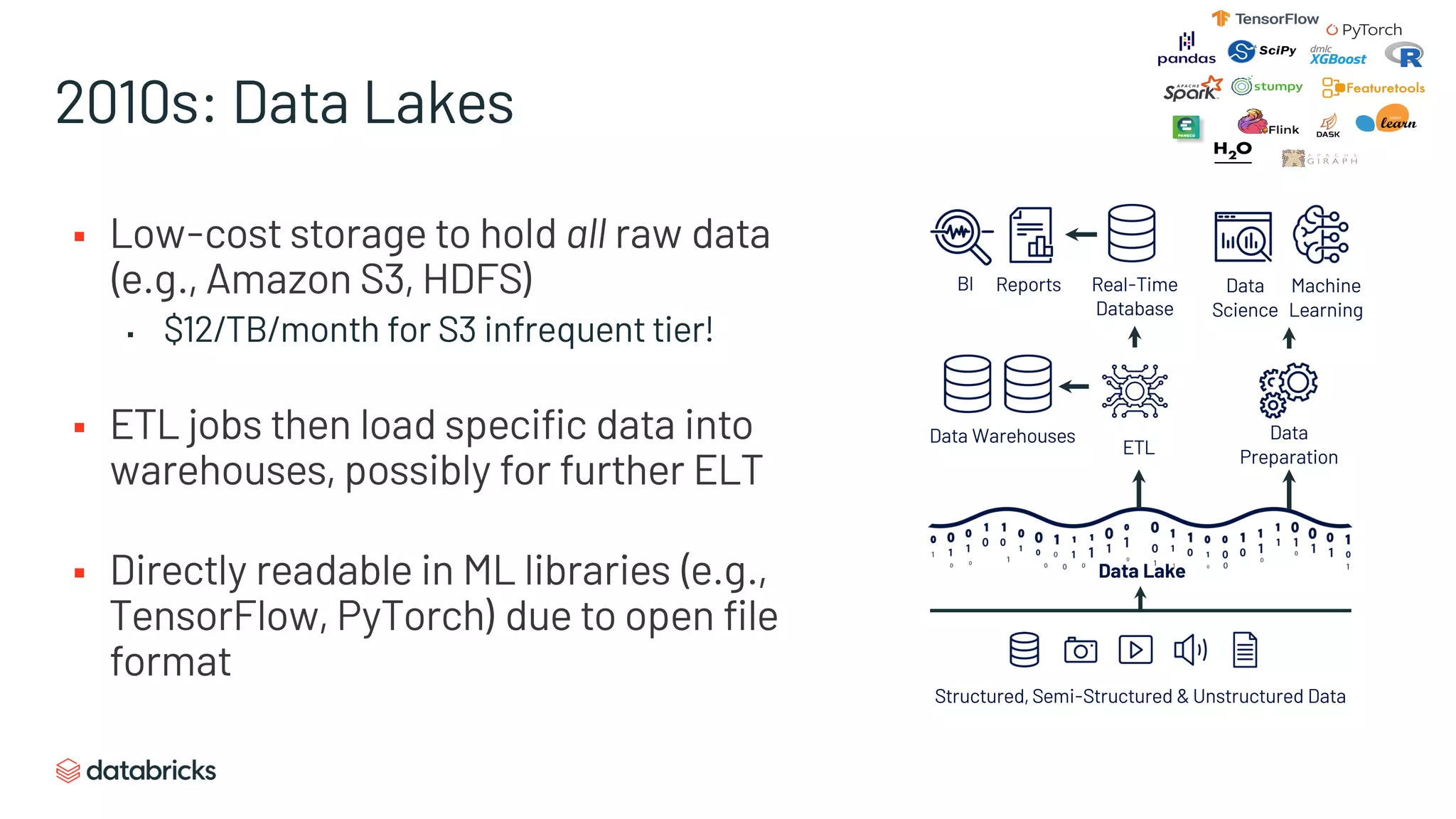
Low-cost solutions for storing raw data, making it accessible for data science and ML analytics.
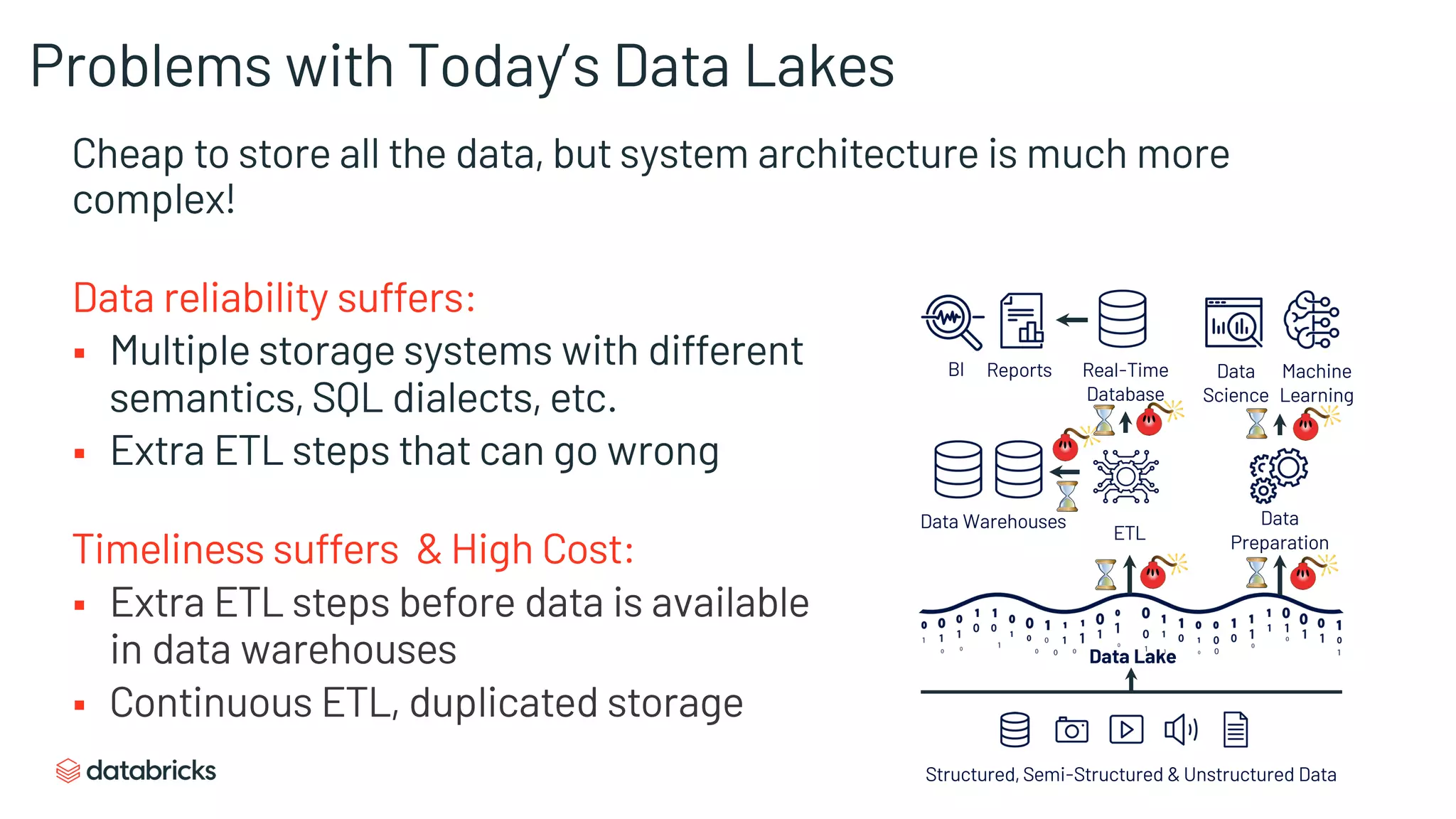
Exposes complexities and reliability issues of data lakes due to multiple storage systems and ETL processes.
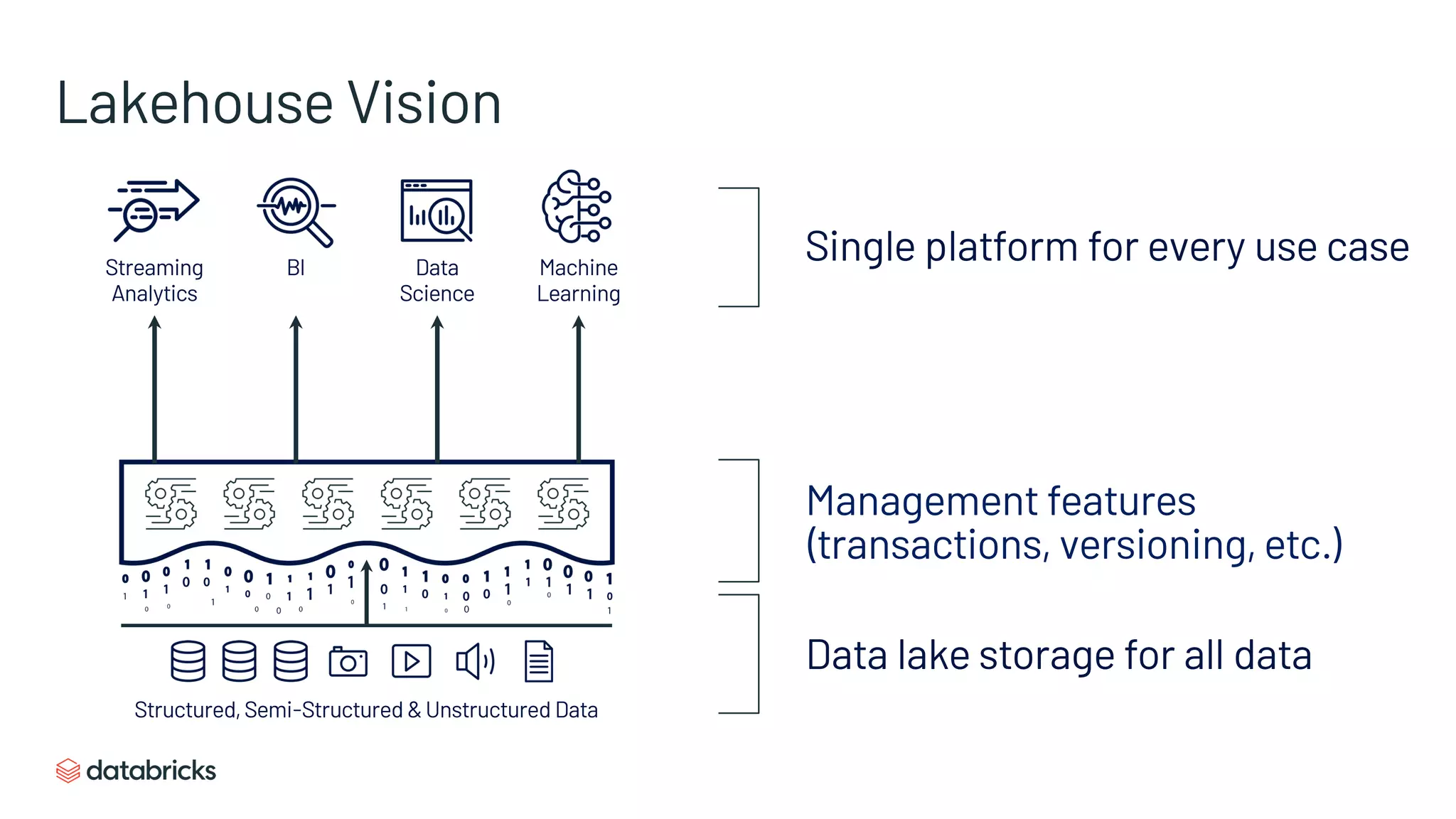
A unified architecture utilizing data lake storage, catering to multiple use cases with management features.
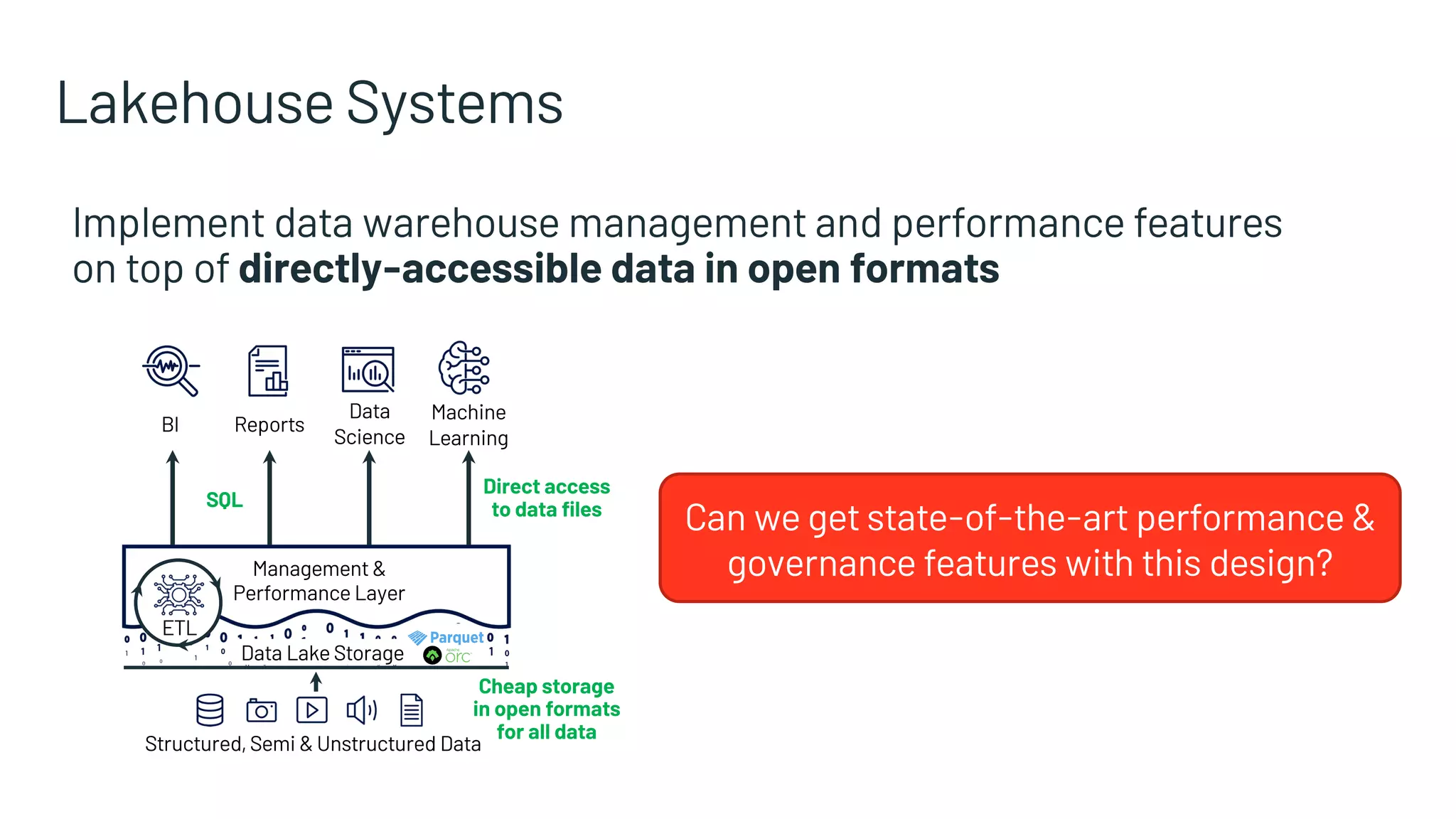
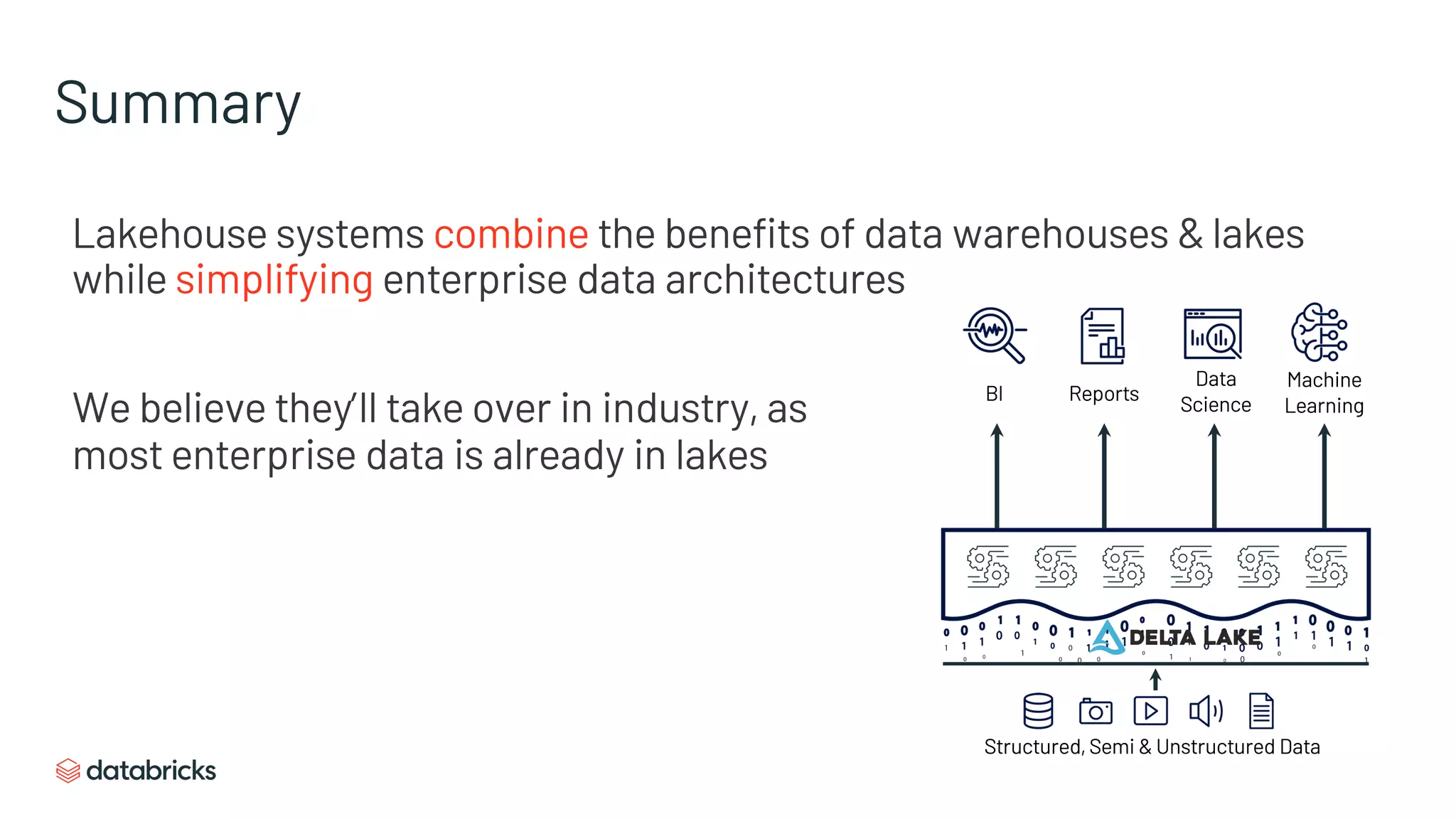
Combines data warehouse features with data lake advantages, focusing on performance and governance.
Technologies such as metadata layers, new query engines, and declarative access supporting lakehouse architecture.
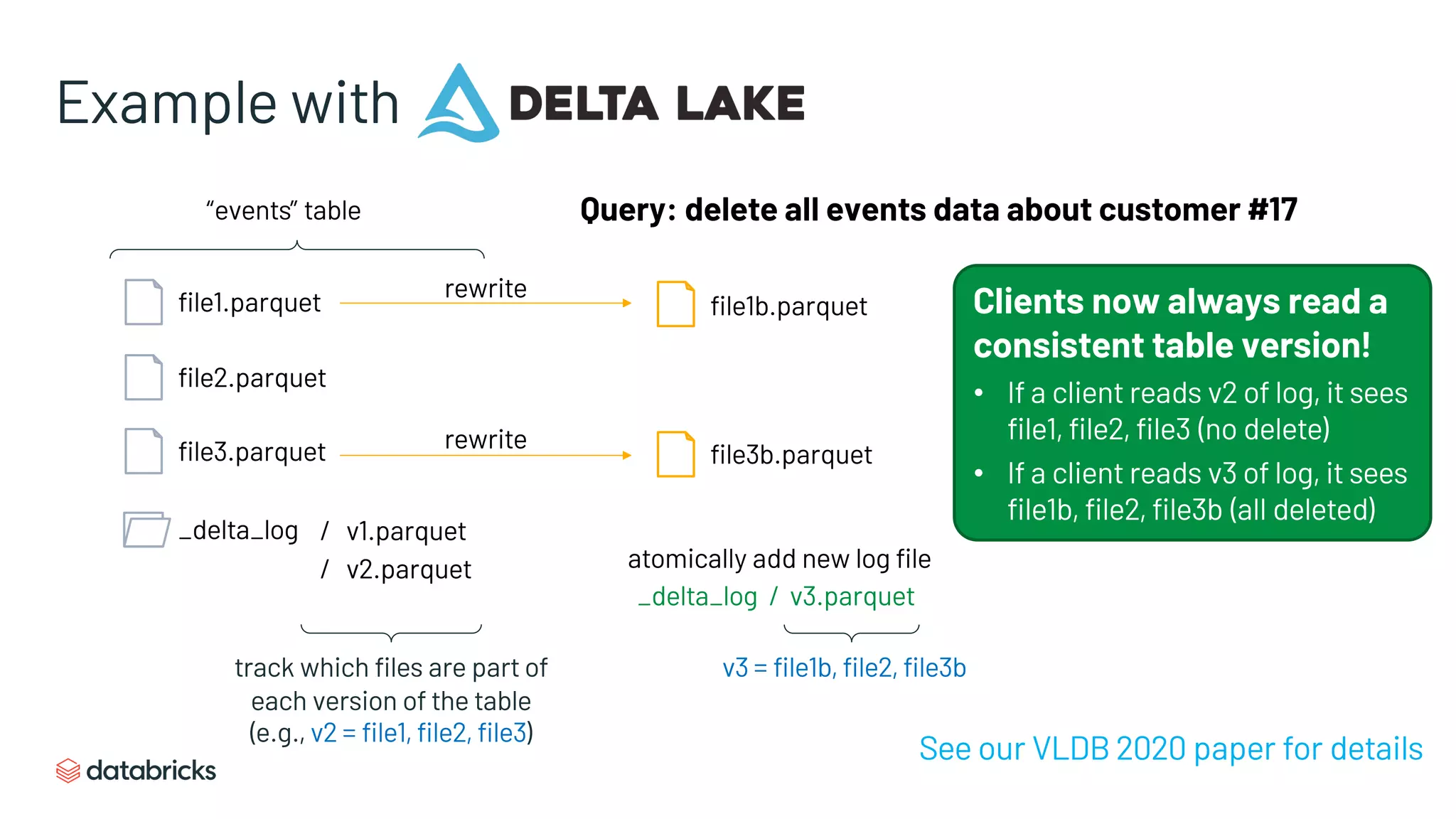
Enhancements from metadata layers providing transactional integrity and high-speed access.
Management features like streaming I/O, time travel, and schema evolution enhancing data lake performance.
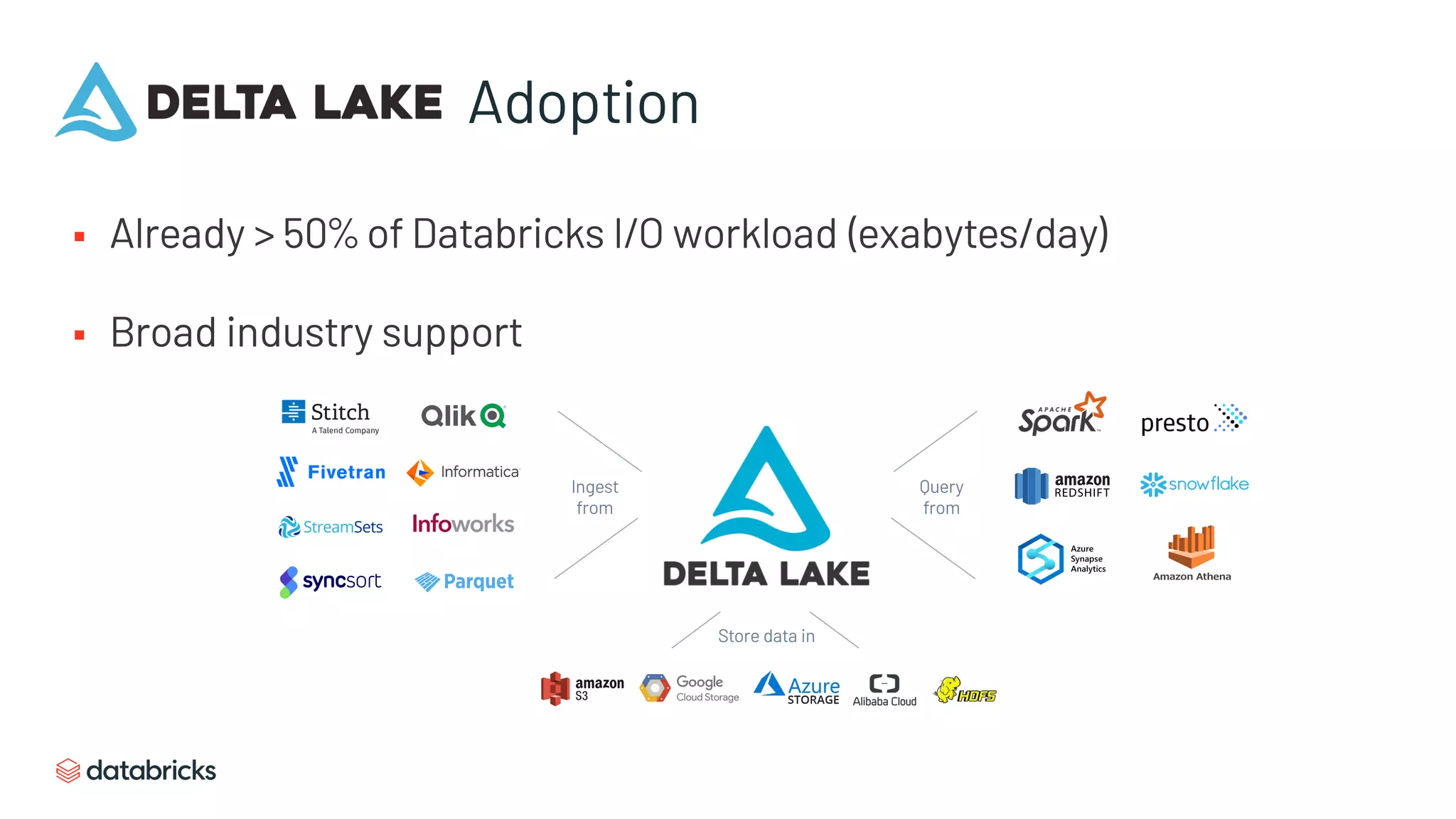
Rapid adoption with over 50% of Databricks I/O workload utilizing lakehouse architecture.
Technological optimizations improving performance in lakehouses, focusing on efficient data access.
Performance testing of Delta Engine showcasing efficient query execution times compared to traditional warehouses.
Combines strengths of data warehouses and lakes, aiding in reliability and data freshness.
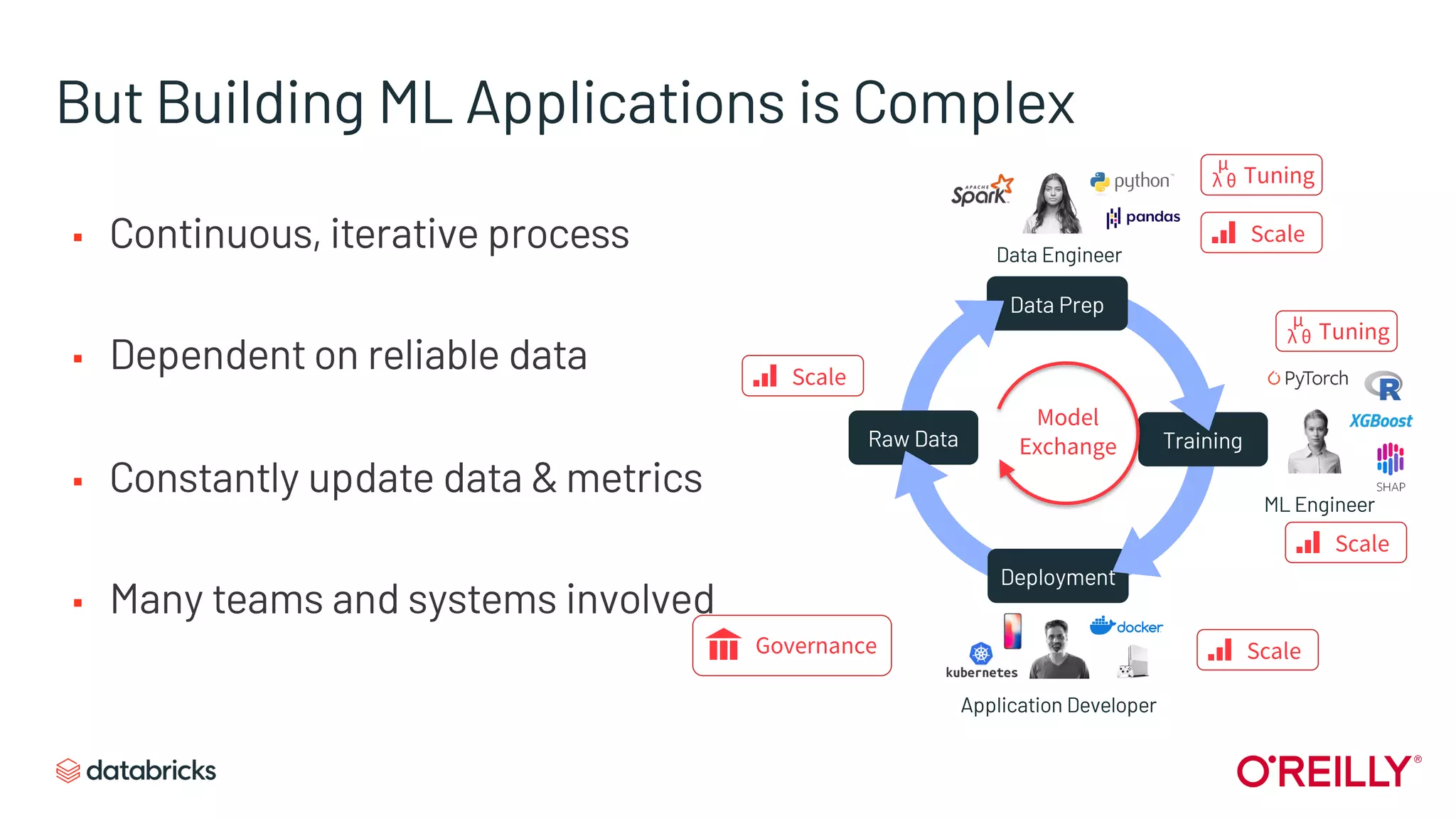
Highlights the inherent complexities in developing machine learning applications compared to traditional software.
Contrasts goals and quality assurance in traditional software development versus machine learning.
Identifies the iterative and collaborative nature of ML projects involving multiple roles and data dependencies.
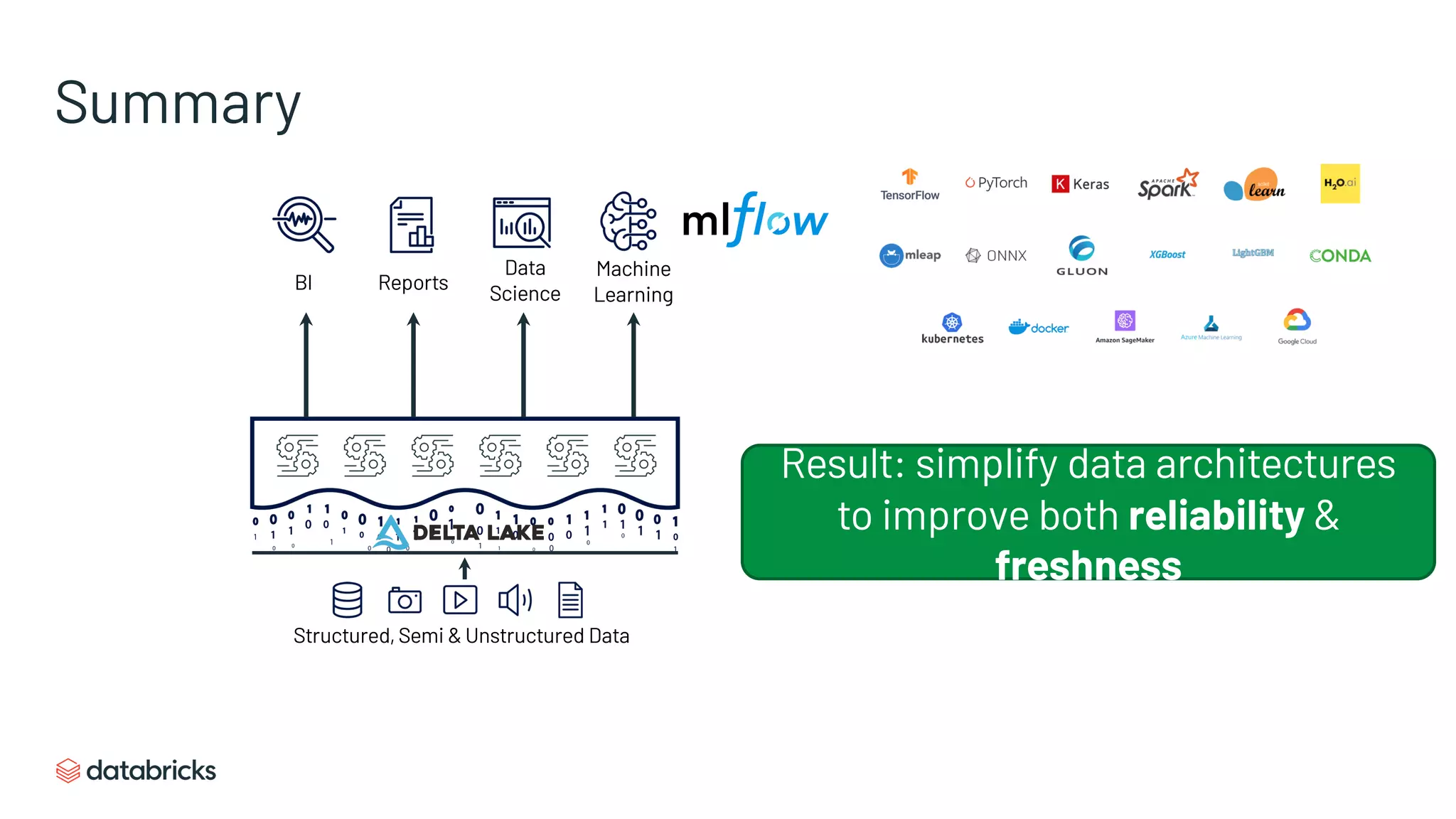
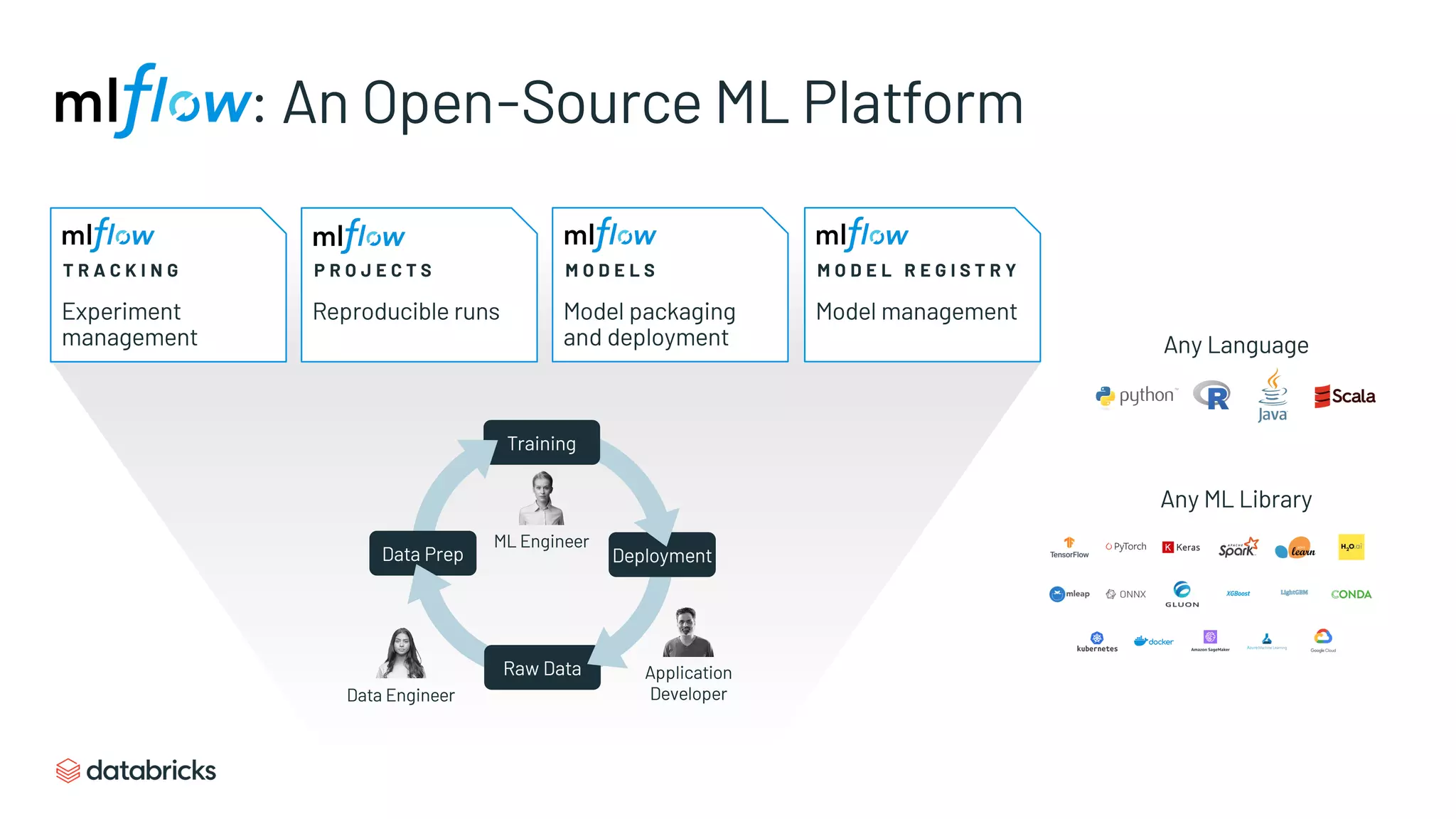
Overview of MLflow as an open-source platform for managing machine learning workflows.
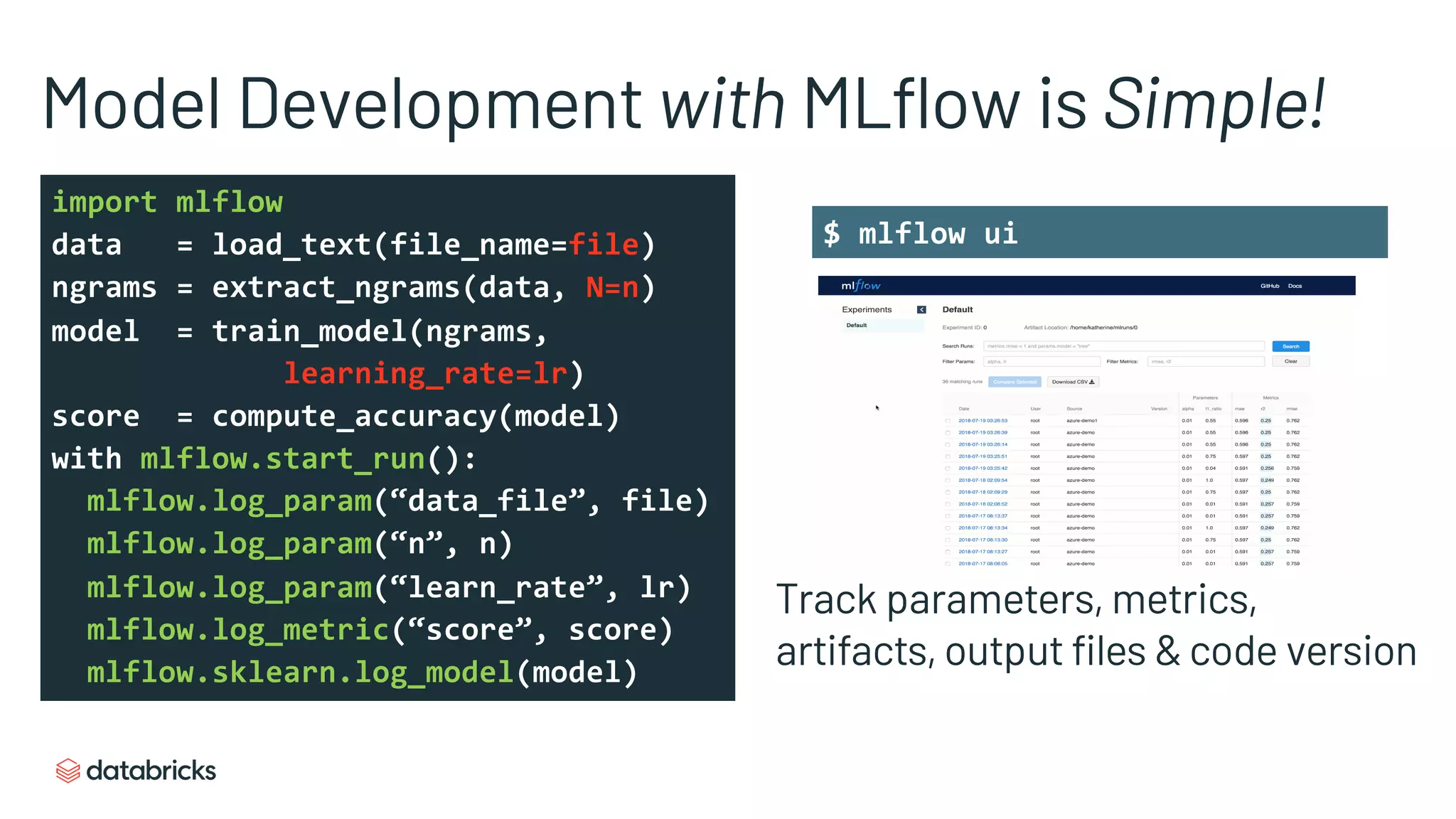
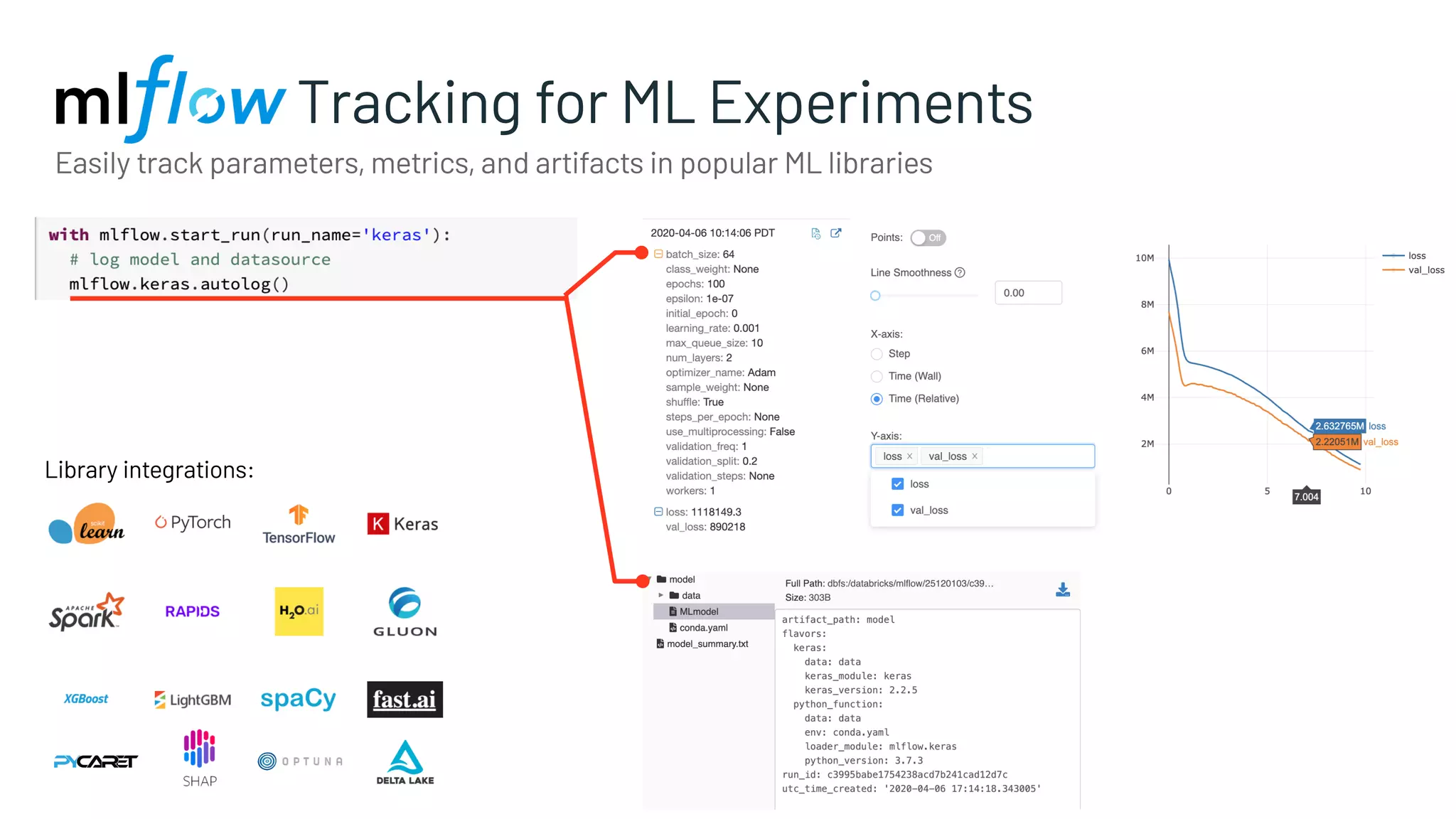
Description of MLflow's tracking capabilities, focusing on parameters, metrics, and artifacts.
Demonstrates how MLflow simplifies tracking model parameters and metrics during development.
Facilitates the integration and tracking of parameters and metrics across popular ML libraries.
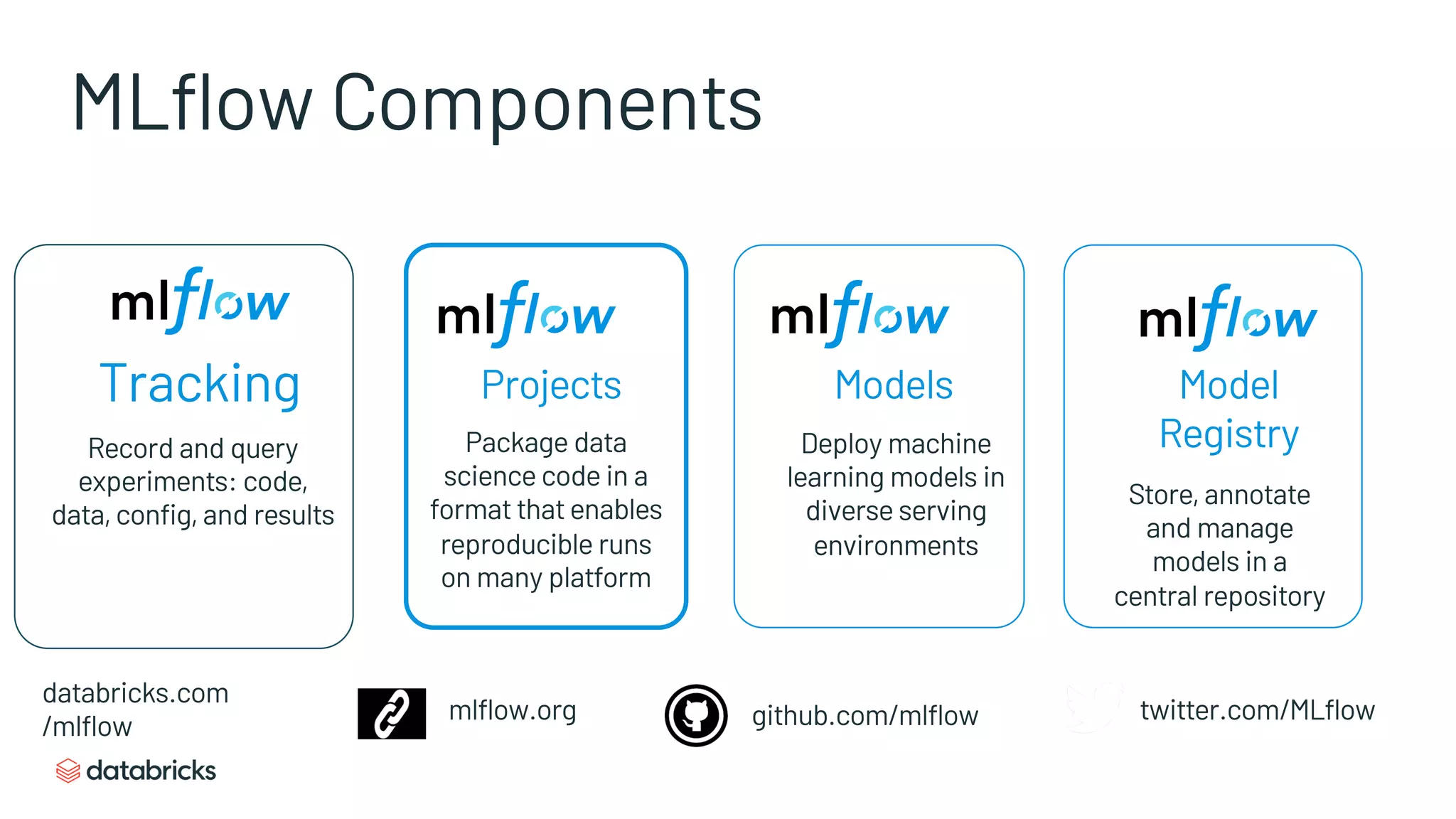
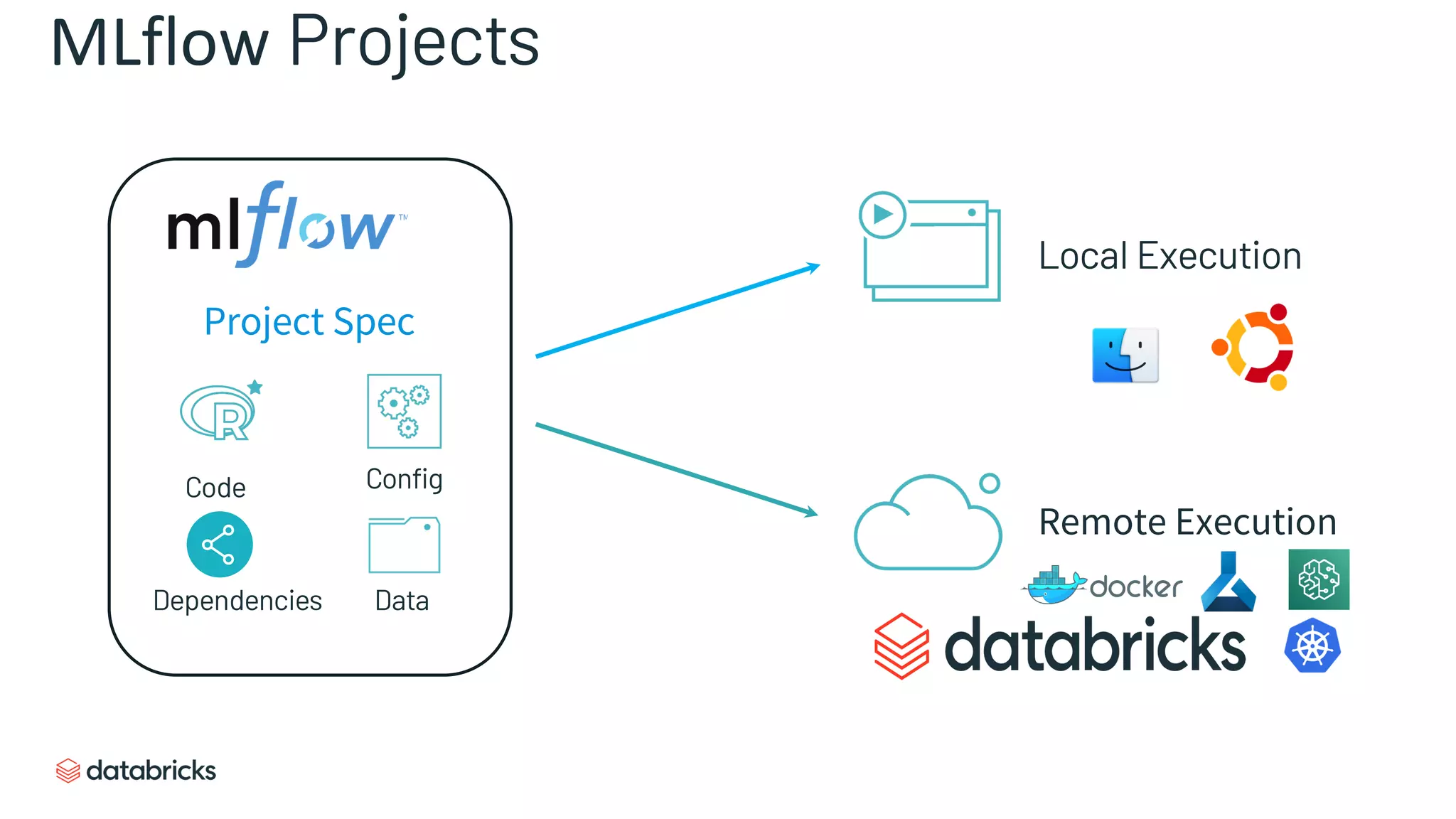
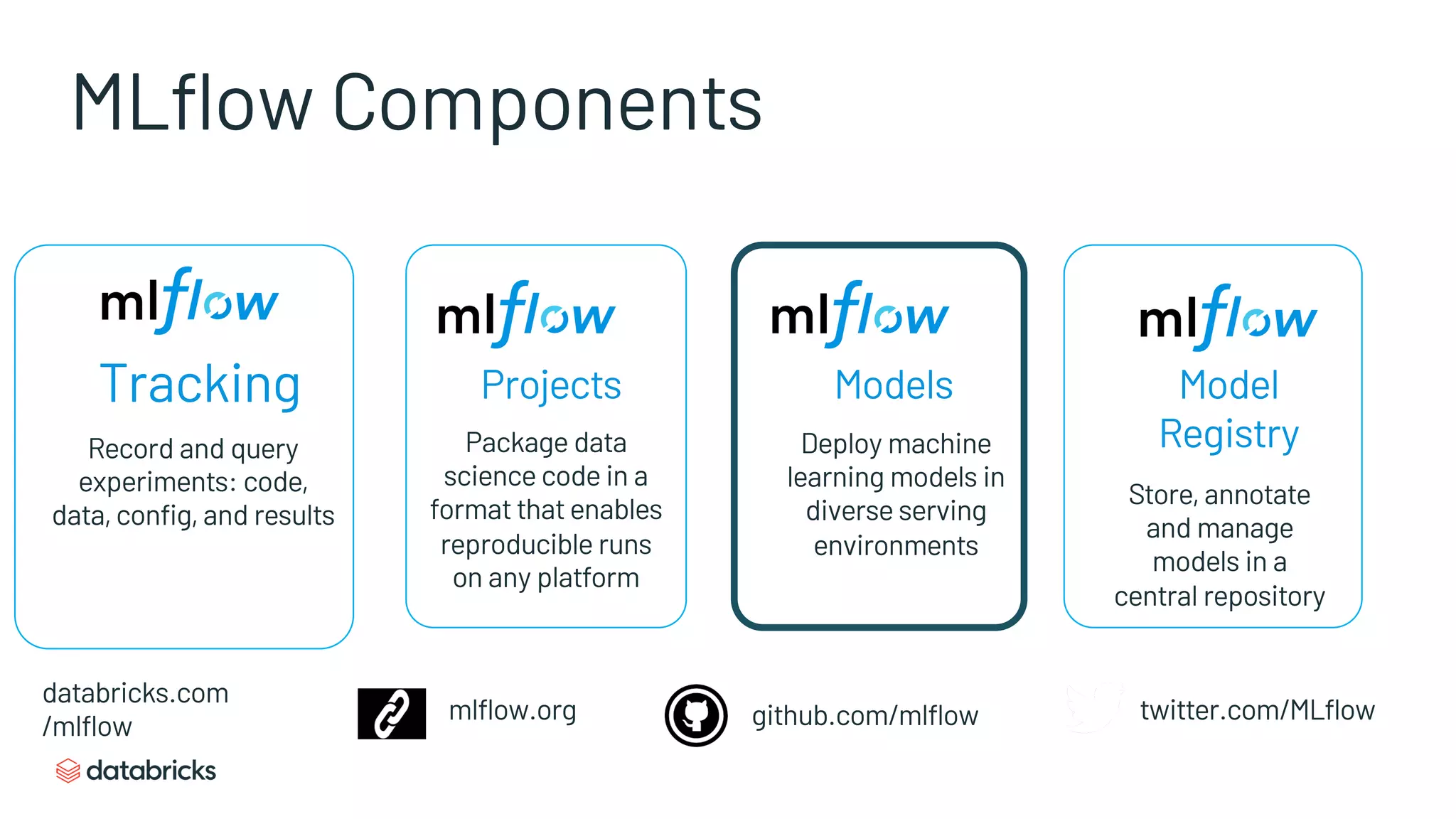
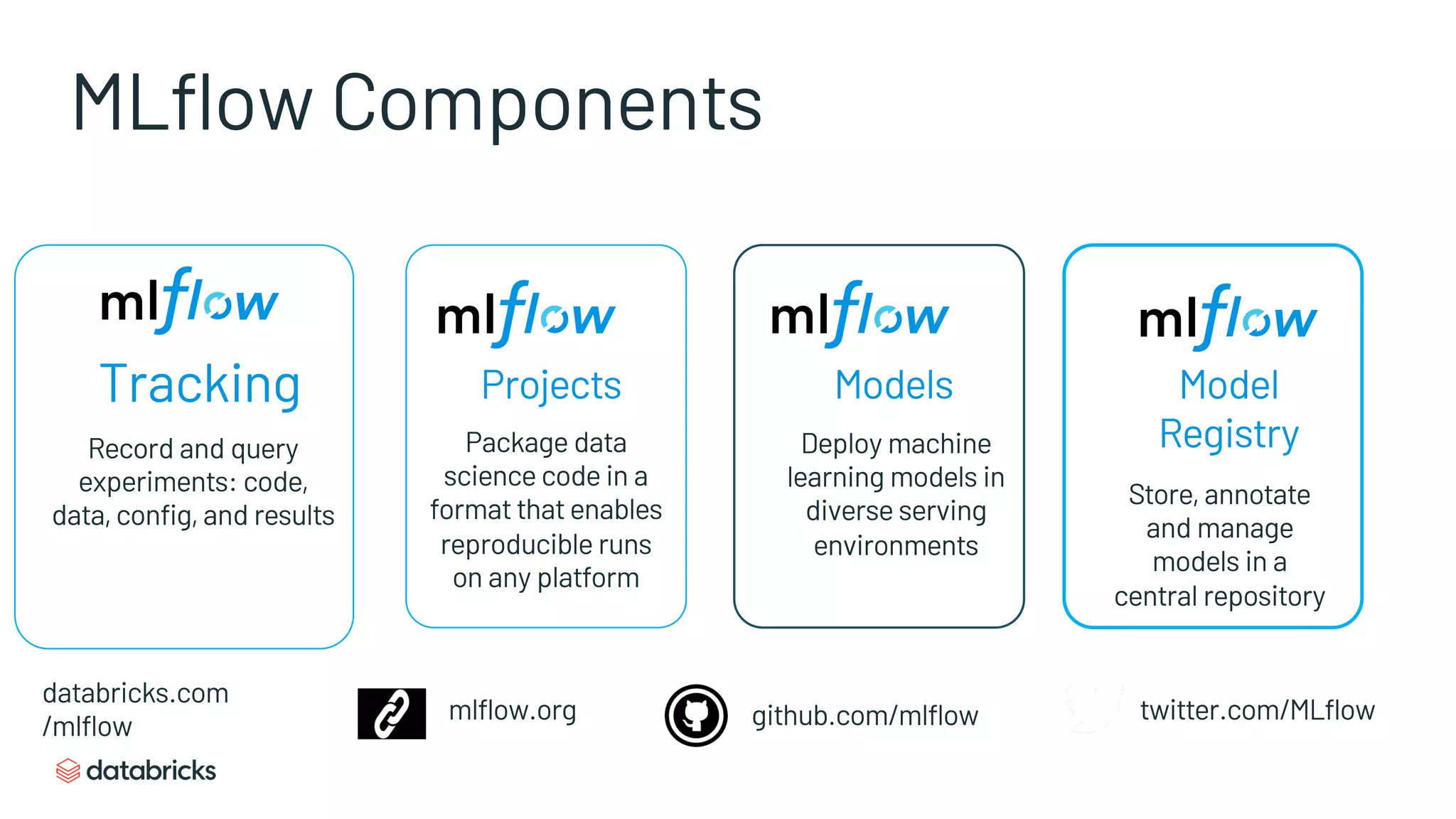
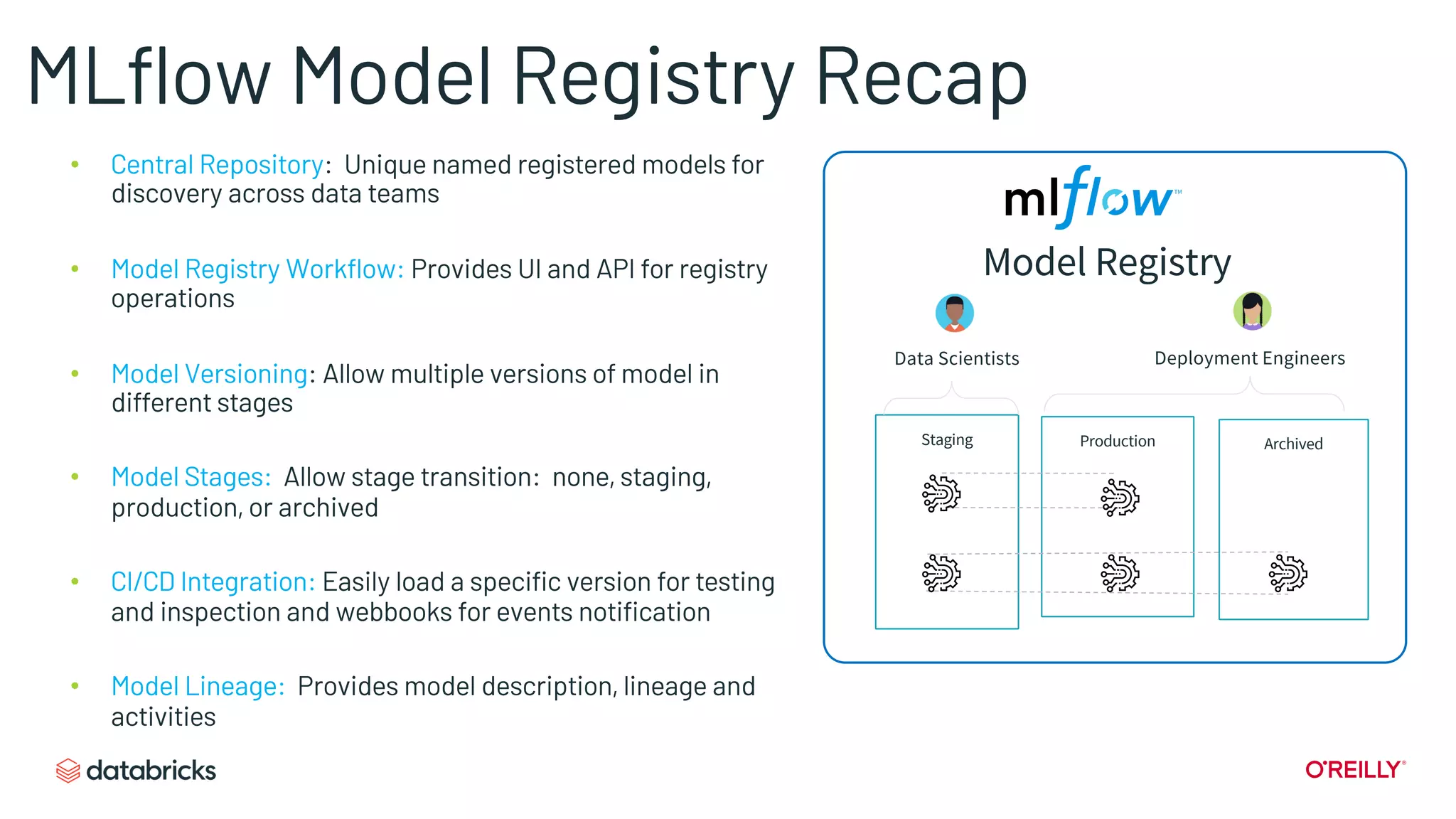
Details MLflow’s core components: Tracking, Projects, Models, and the Model Registry for efficient ML management.
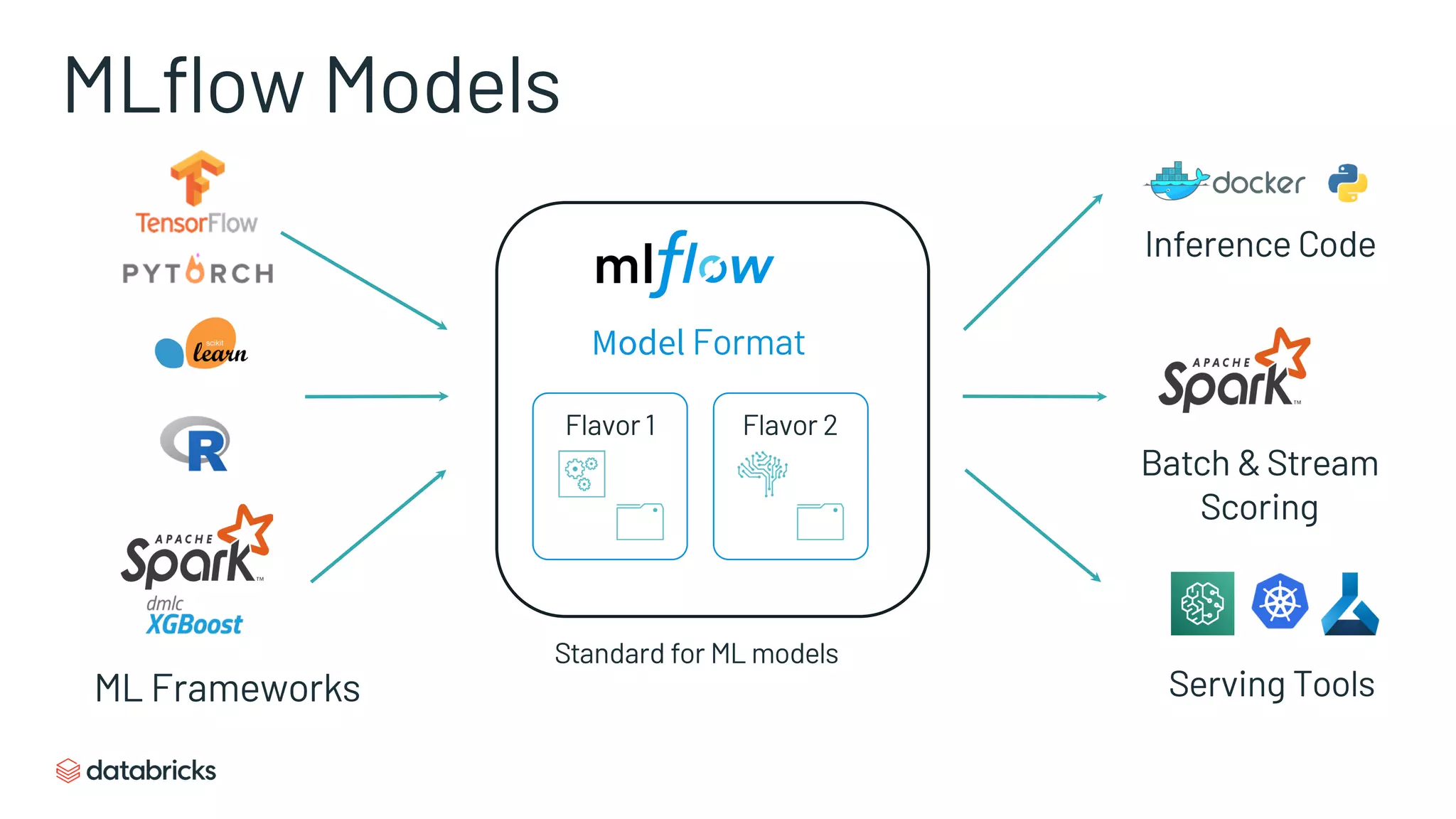
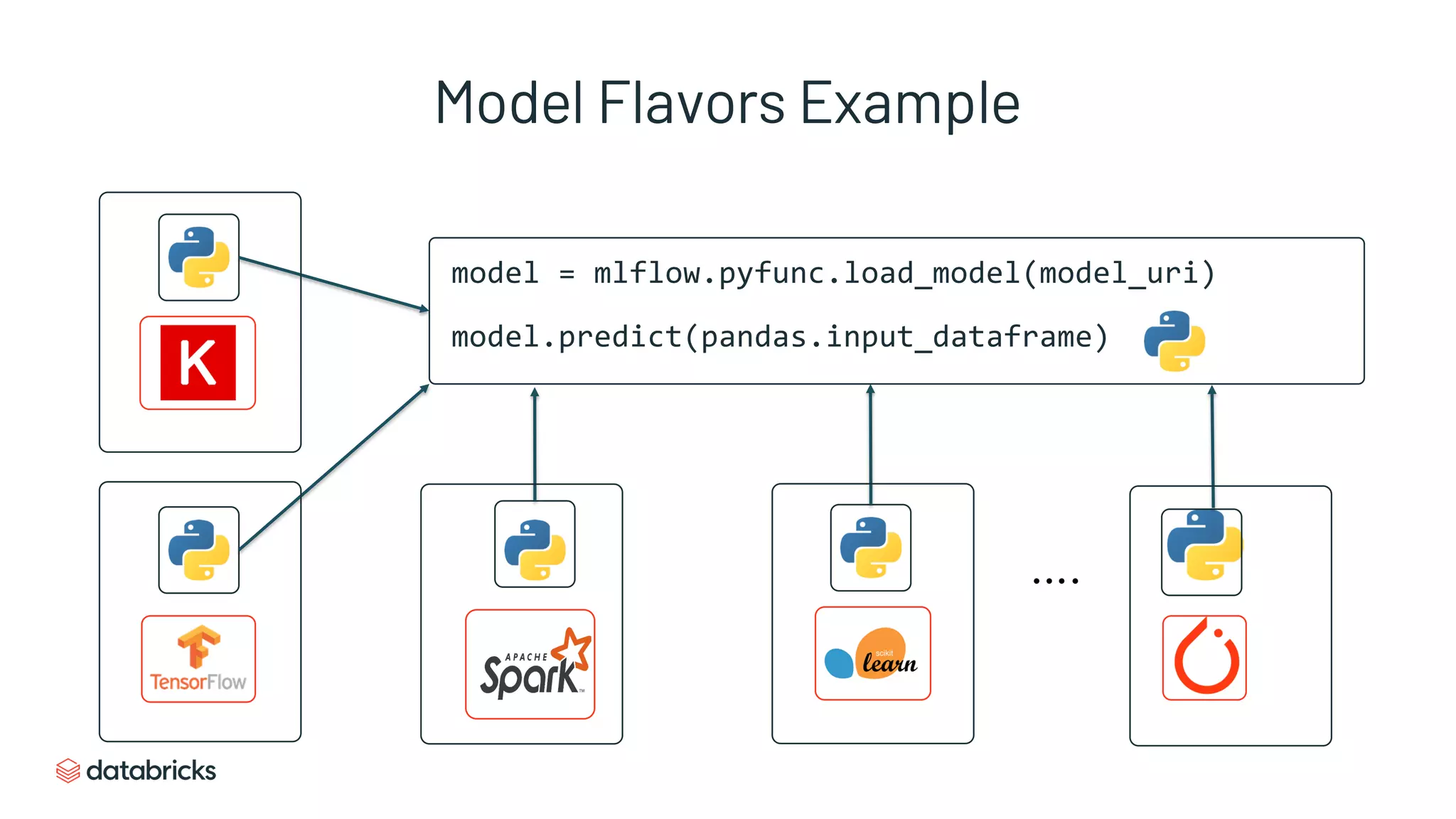
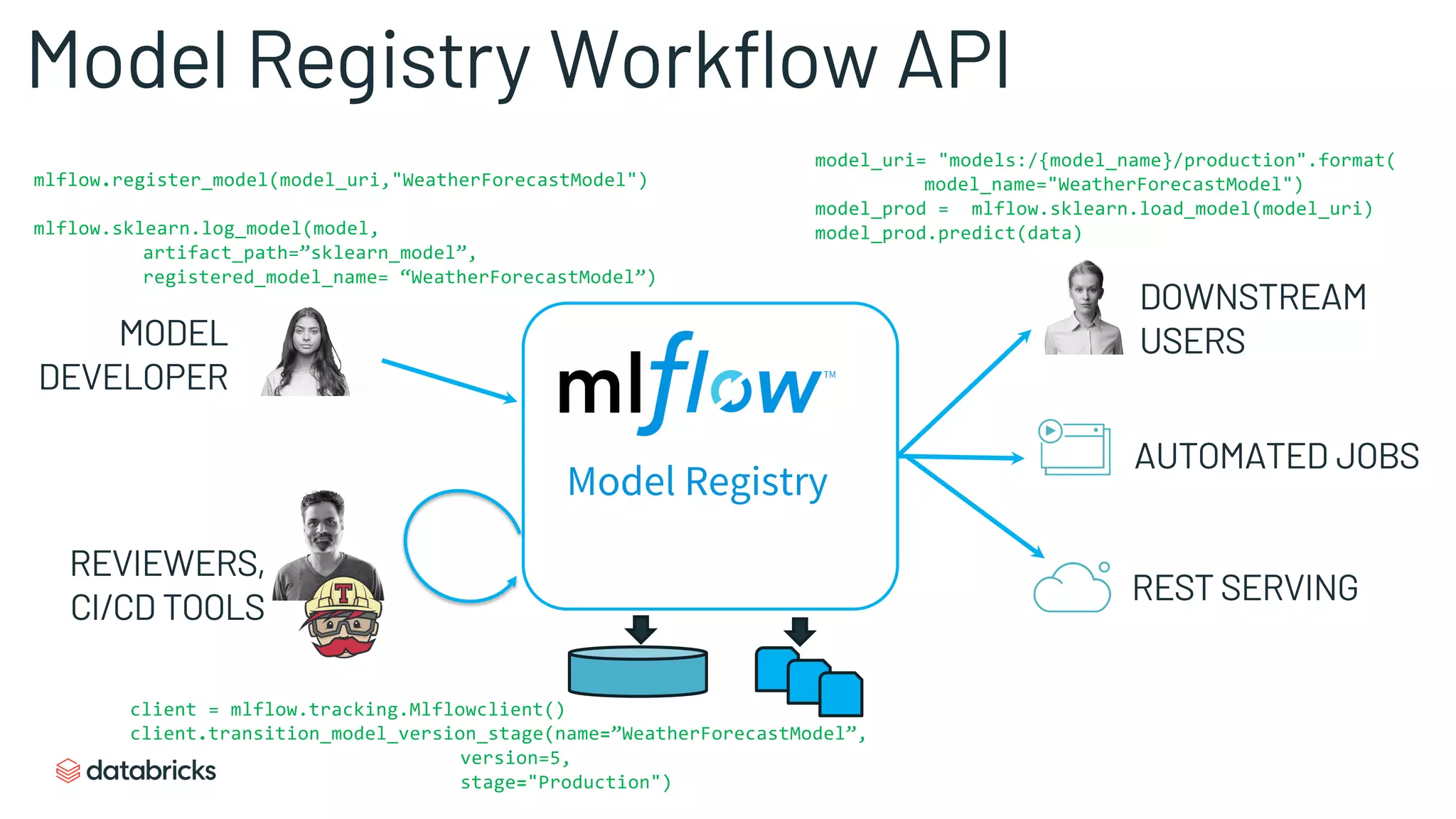
Details of MLflow's model format, showcasing how to load and predict with registered ML models.
Highlights the difficulties faced in managing multiple models within large organizations.
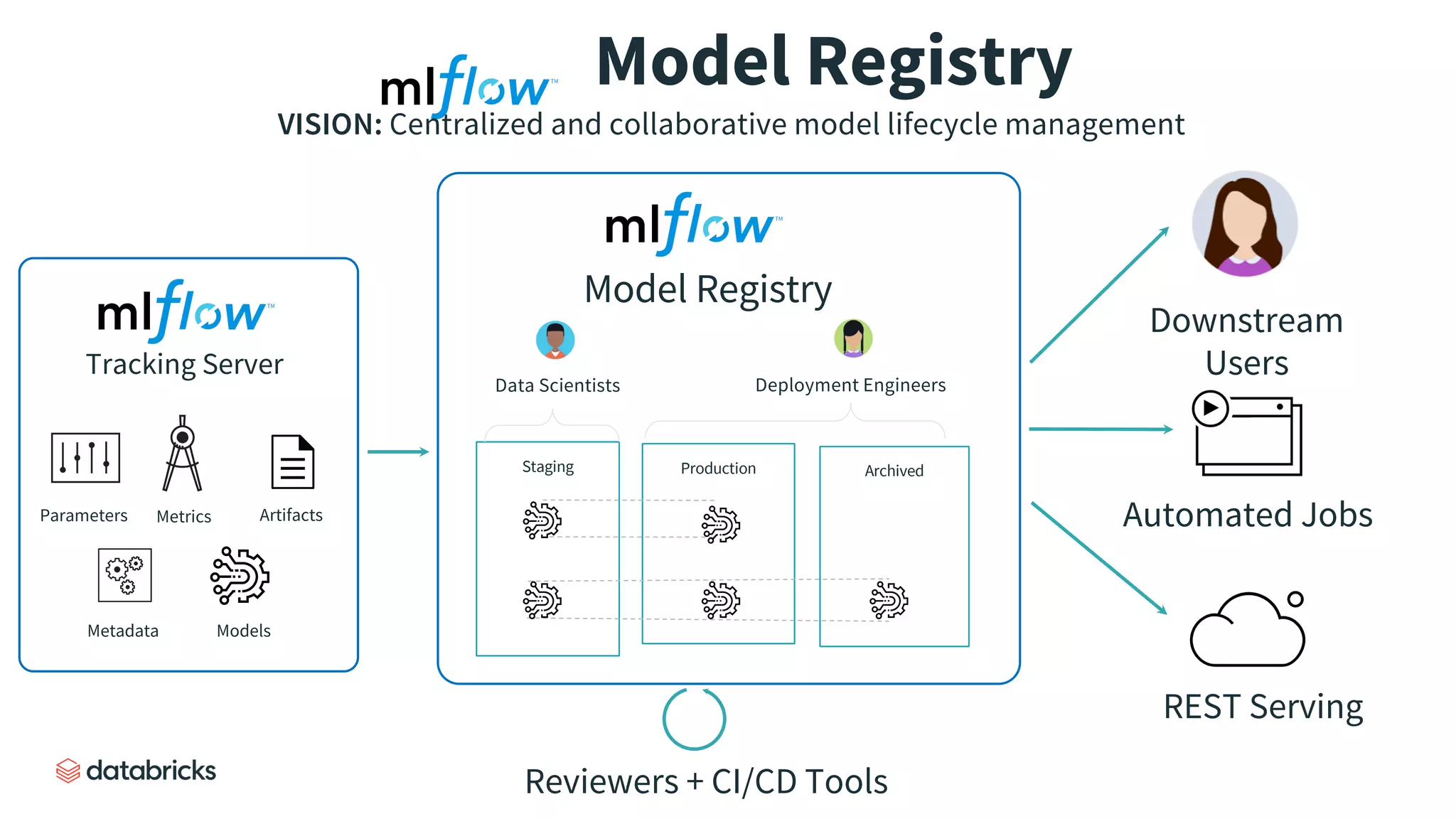
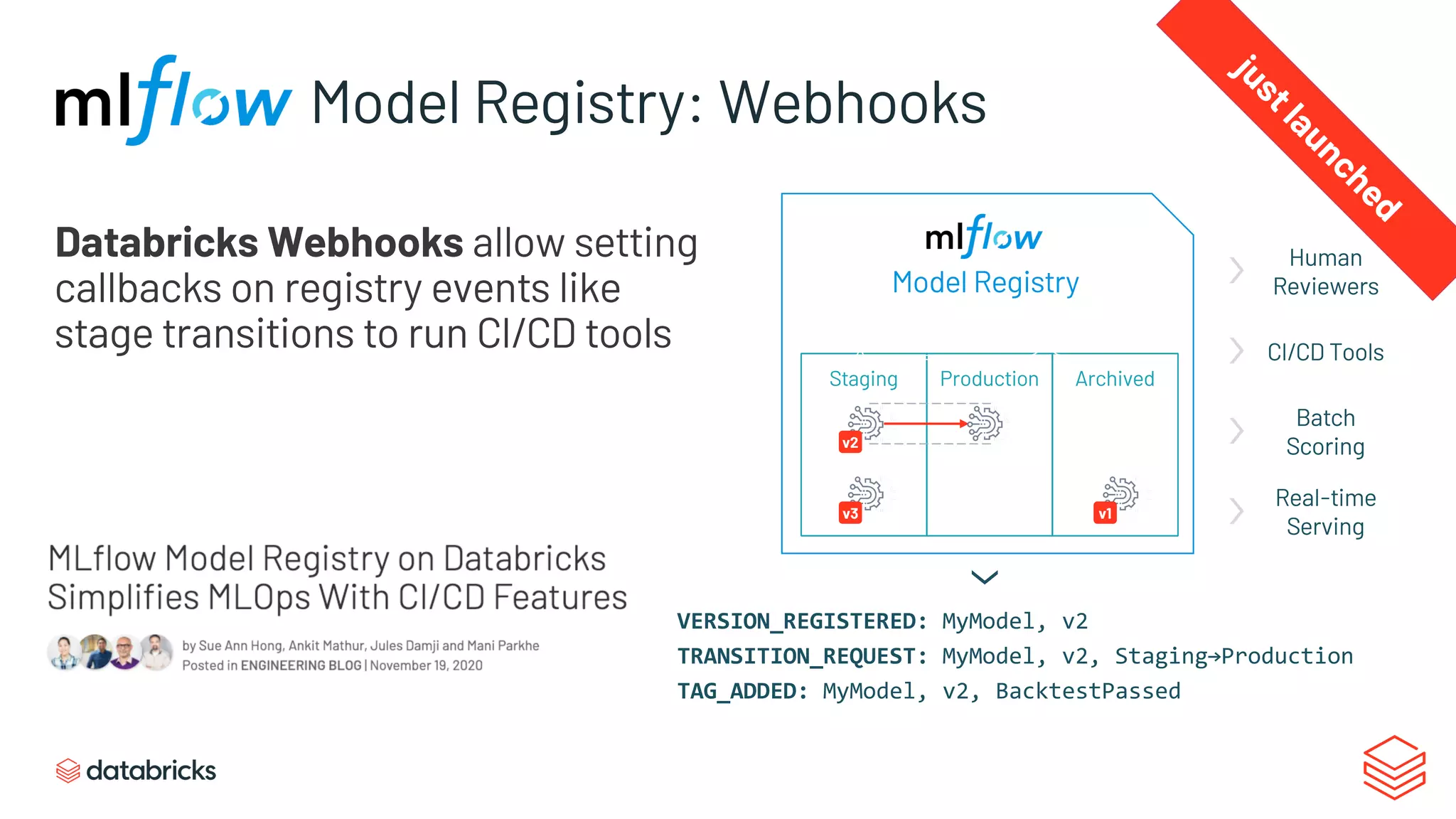
Explores automating model lifecycle management and integration with CI/CD tools.
Describes the functionalities of the model registry, emphasizing version control and model tracking.
Emphasizes the benefits of Lakehouse systems and how MLflow aids in scaling advanced analytics.
Resources for deep diving into Delta Lake, MLflow, and additional reading on data technology.
Closure of the presentation with a session for questions and an invitation to connect.

![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































