Baixar para ler offline













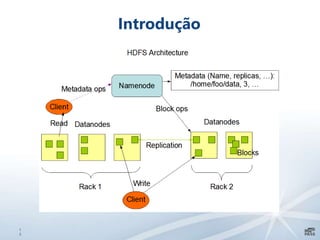
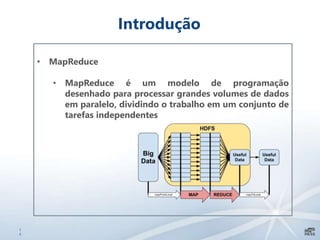
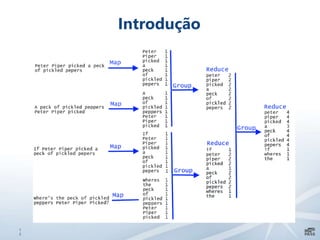


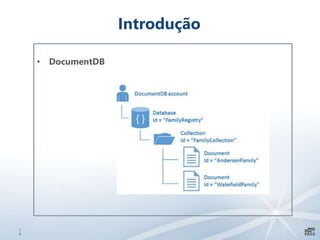





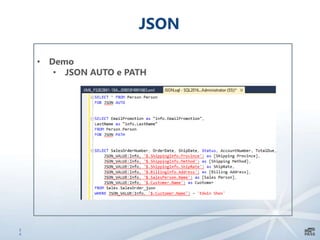
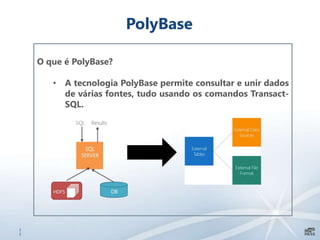
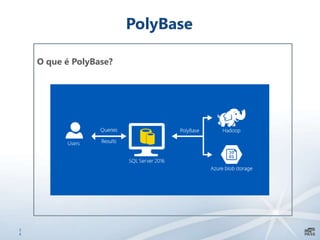




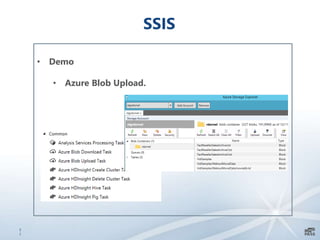



Este documento apresenta uma introdução sobre bancos de dados heterogêneos, incluindo XML, NoSQL, Hadoop, HDFS, Hive e DocumentDB. Também discute como esses sistemas podem ser usados junto com o SQL Server, demonstrando funcionalidades como JSON, PolyBase e SSIS. O objetivo é mostrar como é possível trabalhar com diferentes tipos e fontes de dados usando ferramentas do SQL Server.



































































