Baixado 11 vezes




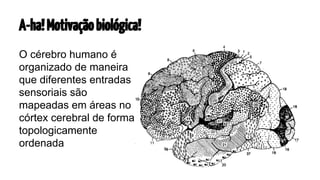
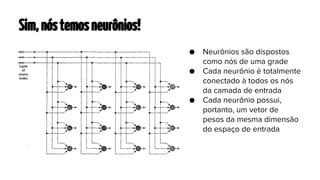














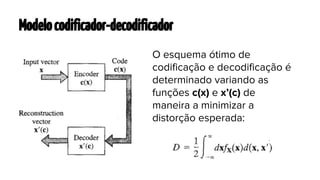










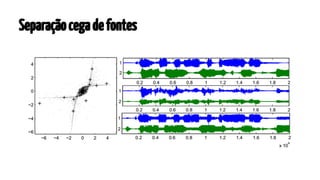





O documento apresenta os mapas auto-organizáveis, que são redes neurais não supervisionadas, capazes de transformar padrões de entrada em uma representação topologicamente ordenada. O processo de formação do mapa envolve três etapas principais: competição, cooperação e adaptação, com duas fases de ordenação e convergência. Além disso, destaca suas aplicações em mapeamento em larga escala, como processamento de linguagem natural e sistemas de recomendação.
















