Baixado 21 vezes










![Exemplos
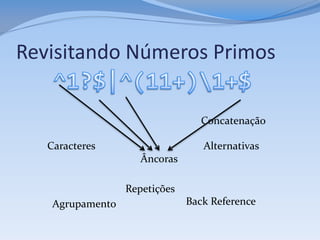
Acha linhas com configurações:
grep "^ *[^# ]" php.ini
Acha linhas que não estejam em branco:
grep –v "^$" .profile
Índice de todas palavras em um texto:
[w.start() for w in re.finditer(r'bw', text)]
Todas palavras de um texto:
@words = $text =~ /w+/
Dia, mês e ano de uma data:
($d, $m, $a) = text =~ /(dd)/(dd)/(d{4})/
Remove espaços do fim da linha:
sed -p'' -e 's/ *$//‘
Divide linha em palavras e símbolos
text split """bs*|s*b"""](https://image.slidesharecdn.com/regex-120625222102-phpapp01/85/Regex-11-320.jpg)

![Autômatos Finitos Determinísticos
Texto termina em n?
n
[^n] n
Regex:
0 .*n$ 1
[^n]](https://image.slidesharecdn.com/regex-120625222102-phpapp01/85/Regex-13-320.jpg)





![Outras operações de Composição
Qualquer caracter: .
Qualquer um de um conjunto: [r1r2-r3]
Qualquer um não em um conjunto: [^r1r2]
Classes de caracteres: [[:alpha:]], w,
Negação de classes: [^[:alpha:]], W
Classes POSIX: p{Upper}, P{InGreek}
Zero ou um: r?
Um ou mais: r+
Entre n e m repetições: r{n, m}](https://image.slidesharecdn.com/regex-120625222102-phpapp01/85/Regex-19-320.jpg)
![Classes úteis
[:alnum:]
w – inclui sublinhado (não palavras como W)
[:alpha:]
[:blank:]
[:cntrl:]
[:digit] ou d (não dígito como D)
[:graph:]
[:lower:]
[:print:]
[:punct:]
[:space:] ou s (não espaço como S)
[:upper:]
[:xdigit:]](https://image.slidesharecdn.com/regex-120625222102-phpapp01/85/Regex-20-320.jpg)











![E-mail regex
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:.[a-z0-
9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[x01-x08x0bx0cx0e-
x1fx21x23-x5bx5d-x7f]|[x01-x09x0bx0cx0e-
x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?.)+[a-
z0-9](?:[a-z0-9-]*[a-z0-9])?|[(?:(?:25[0-5]|2[0-4][0-
9]|[01]?[0-9][0-9]?).){3}(?:25[0-5]|2[0-4][0-
9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[x01-
x08x0bx0cx0e-x1fx21-x5ax53-x7f]|[x01-
x09x0bx0cx0e-x7f])+)])](https://image.slidesharecdn.com/regex-120625222102-phpapp01/85/Regex-37-320.jpg)







O documento discute expressões regulares (regex), mencionando que: 1) Embora regex sejam aceitas por quase todas as bibliotecas, na verdade não são expressões regulares; 2) São difíceis de entender e fáceis de errar; 3) Apesar disso, são extremamente compactas.





































