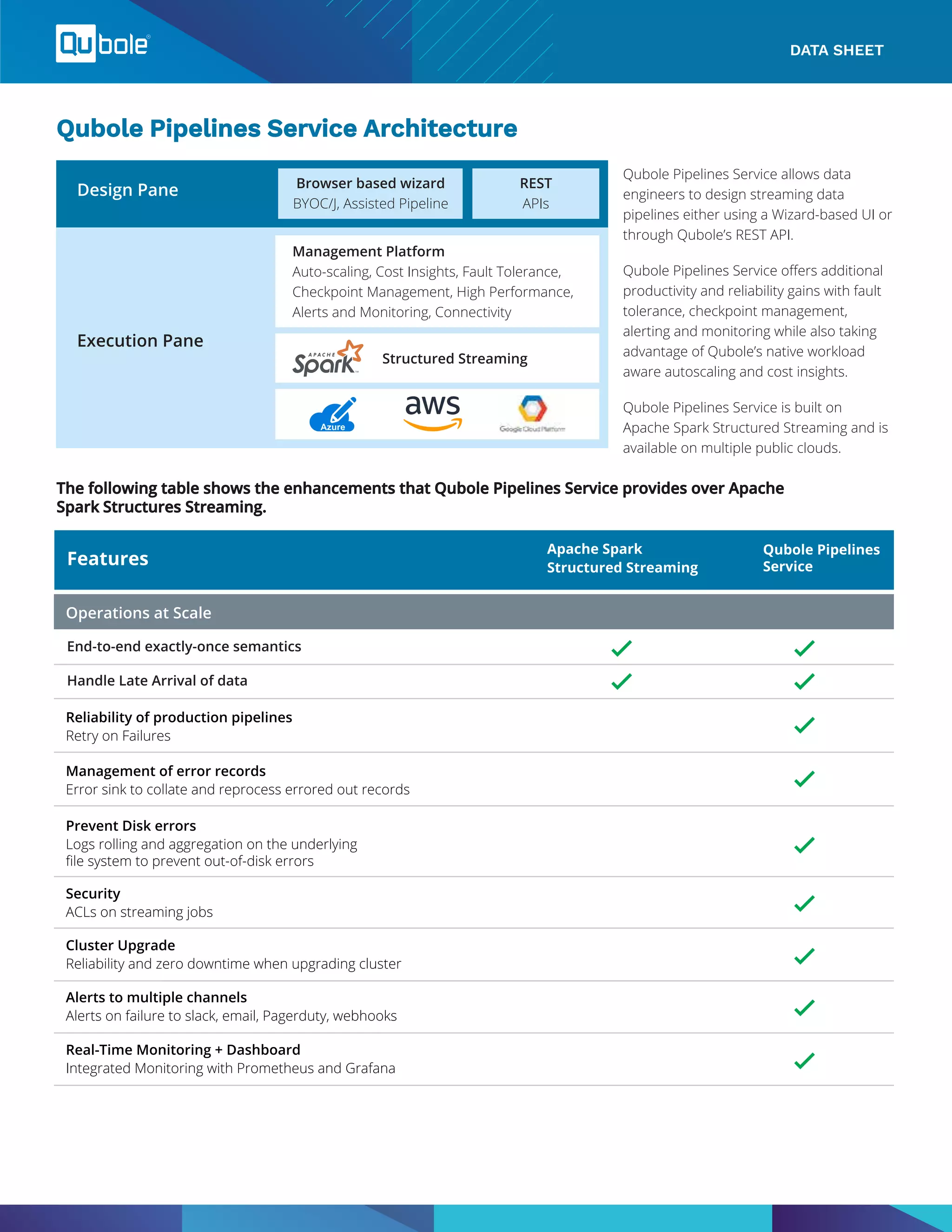
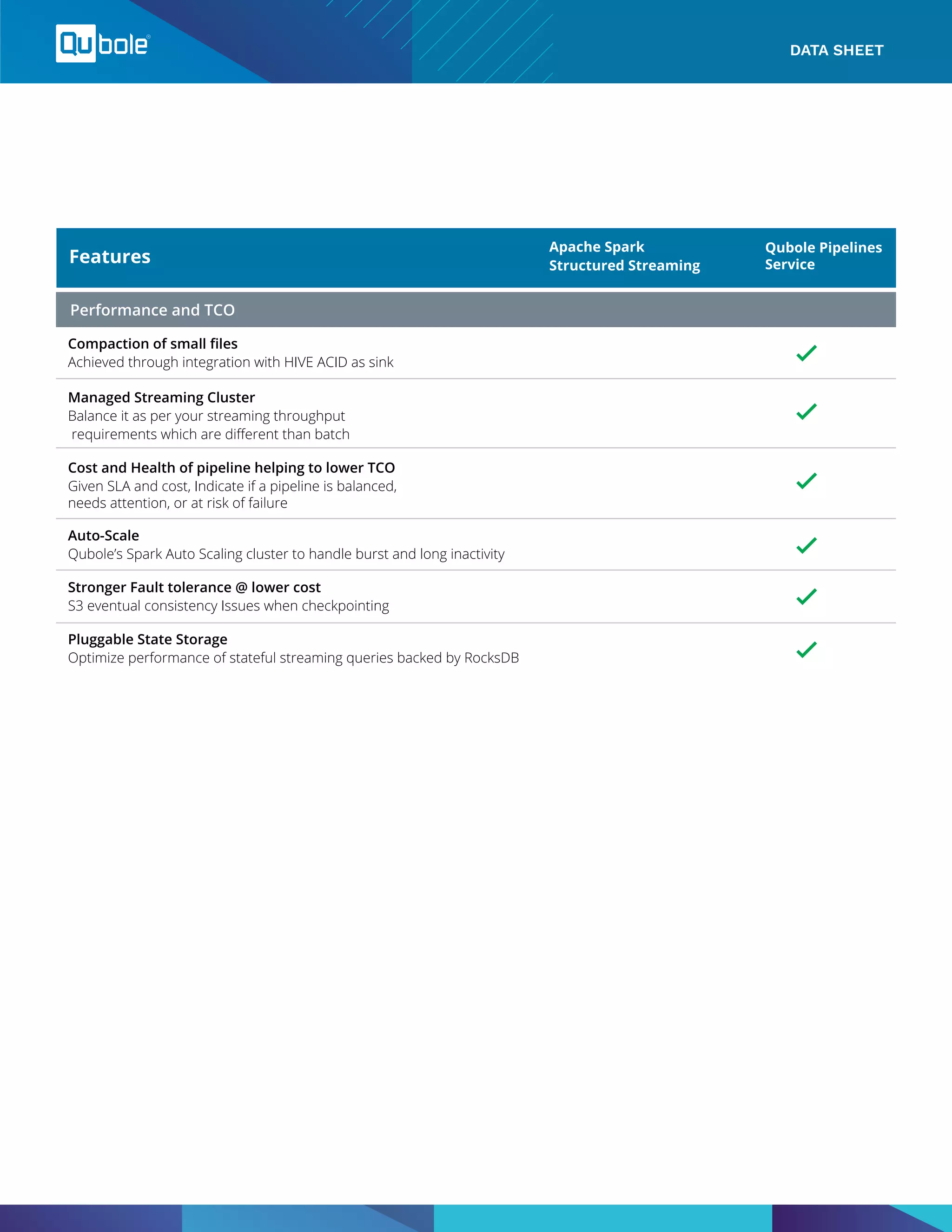
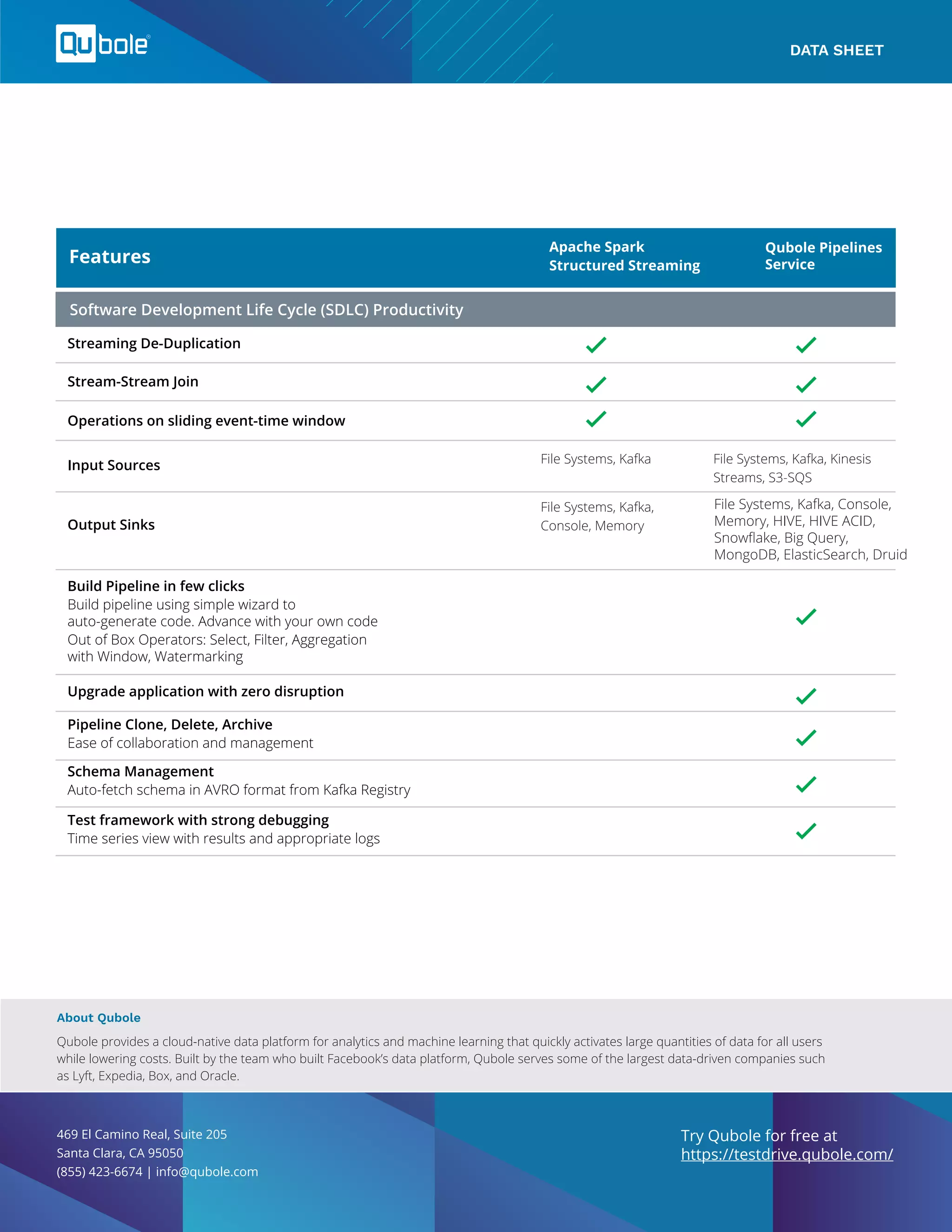
Qubole Pipelines Service is a comprehensive stream processing platform built on Apache Spark, designed to manage streaming ETL pipelines with minimal overhead. It focuses on reducing time-to-decision by facilitating real-time data insights and provides enhanced features like fault tolerance, auto-scaling, and monitoring across cloud environments. The service aims to simplify the complexities of data processing for data engineers and data scientists, promoting productivity and reliability in pipeline management.