Transferir como PDF, PPTX









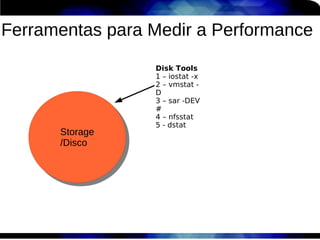
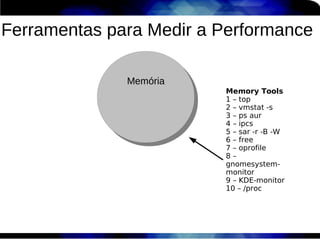


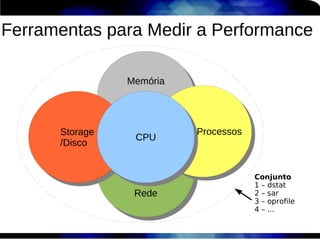


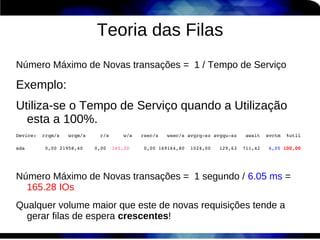


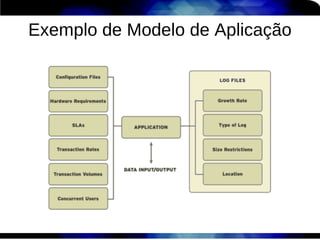
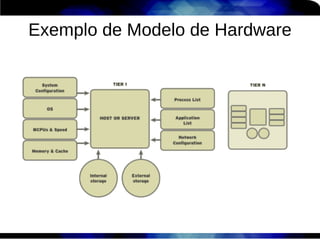

























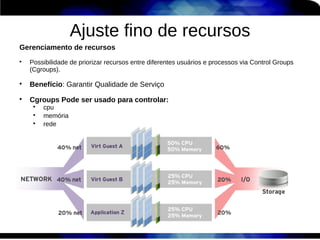
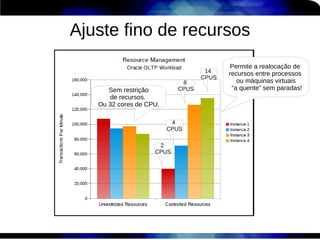

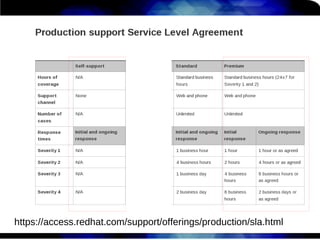
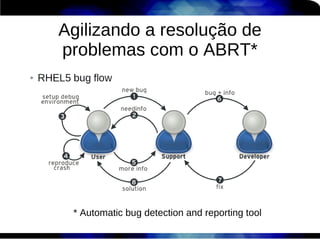
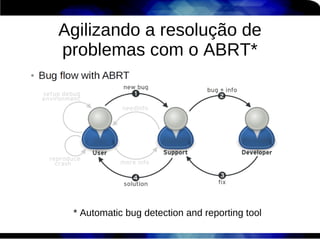
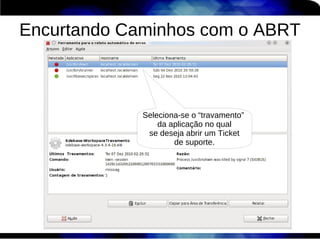
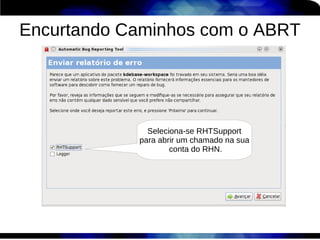
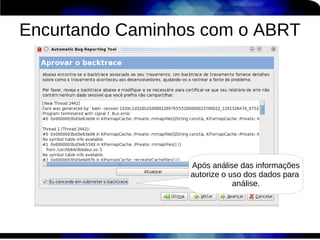
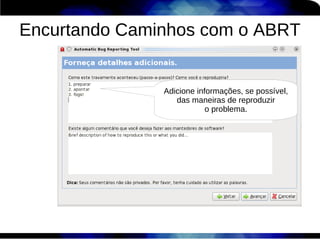
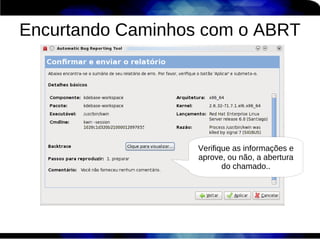
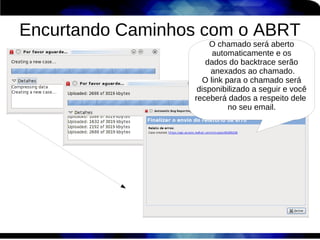
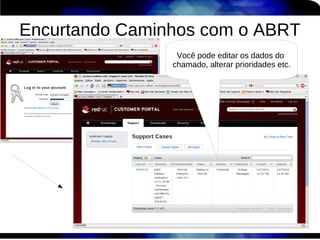

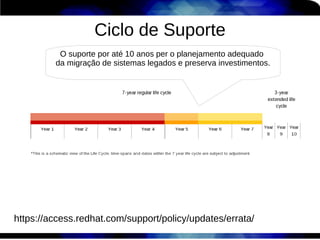
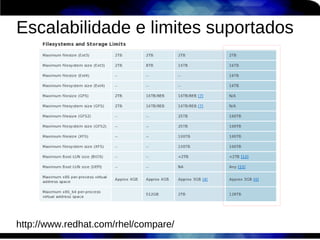





1) O documento discute técnicas de otimização de desempenho (performance tuning) no Red Hat Enterprise Linux, incluindo medição de desempenho, teoria de filas de espera, armazenamento, memória e processos. 2) É destacada a importância de se medir o desempenho para identificar gargalos antes de realizar ajustes, utilizando ferramentas como iostat, sar, vmstat e top. 3) Conceitos como lei de Little, throughput, utilização e tempo médio de resposta são explicados para fundament




































































