A dissertação de Nuno Miguel Cerqueira Costa aborda a combinação de lógicas de descrição e programação em lógica, destacando sua importância na representação de conhecimento e na web semântica. O trabalho propõe a extensão de um sistema de processamento de queries, inicialmente compatível apenas com o perfil OWL 2 EL, para incluir o OWL 2 QL, permitindo raciocínios polinomiais em contextos de grandes volumes de dados. A pesquisa destaca o formalismo híbrido MKNF, que une as semânticas das lógicas de descrição e da programação lógica para aumentar a expressividade na representação de domínios complexos.








![chapterEnquadramento, Objectivos e Contribuições
Representação de conhecimento e raciocínio é uma área da inteligência artificial cujo o
objectivo é determinar como se pode representar conhecimento simbolicamente e manipulá-
lo automaticamente com programas de raciocínio. Por outra palavras, é o ramo da inte-
ligência artificial relacionado com o pensamento, e com o seu contributo para o compor-
tamento inteligente [7].
Muitas das linguagens de representação de conhecimento desenvolvidas até agora
podem ser classificadas em uma das duas seguintes famílias, que têm sido desenvolvidas
nos últimos 30 anos quase independentemente uma da outra [37]:
• a primeira inclui formalismos que tentam reconstruir abordagens populares como
os sistemas baseados em estruturas e redes semânticas, entre os quais as lógicas de
descrição são os mais proeminentes;
• a segunda família é centrada na ideia de modelar o conhecimento com regras e o
seu formalismo fundamental é fornecido pela programação em lógica.
O estudo das lógicas de descrição (DL) tem coberto não só os fundamentos teóri-
cos como também a implementação de sistemas de representação de conhecimento e o
desenvolvimento de aplicações em várias áreas, e tem-se revelado bem sucedido. O ele-
mento chave para esse sucesso é a metodologia de investigação baseada numa interação
próxima entre teoria e prática, havendo, por um lado, várias implementações de sis-
temas baseados em lógicas de descrição, que oferecem uma paleta de formalismos de
descrição com diferentes poderes expressivos, e aplicados em vários domínios, e por ou-
tro lado, um estudo detalhado das propriedades formais e computacionais do raciocínio
nesses formalismos. Esses estudos são normalmente motivados pelo uso de certos tipos
de construtores em sistemas implementados ou pela necessidade desses construtores em
aplicações específicas [4].
As lógicas de descrição representam o domínio de interesse em termos de conceitos,
que denotam conjuntos de objectos, e relações entre conceitos, sobre esses conjuntos de
objectos. Oferecem um conjunto de construtores para combinar conceitos, expressando,
desse modo, novos conceitos. As propriedades dos conceitos e relações são descritas
através axiomas de subsunção, que estabelecem que cada instância de um dado conceito
(resp., relação) é também instância de um outro conceito (resp., relação). As proprieda-
des dos objectos expressam-se recorrendo a asserções de pertença, que indicam de que
conceito um dado objecto é instância ou em que relações participa com outros objectos.
Em geral, são fragmentos da lógica de primeira ordem [9]. Os sistemas de representação
de conhecimento baseados em lógicas de descrição, podem suportar, além de queries, di-
versos serviços de raciocínio, como a classificação, na qual se estrutura o conjunto dos
axiomas da ontologia, numa hierarquia de subsunções, onde as subsunções implícitas,
i.e. implicadas por outras, são tornadas explicitas; ou verificação de consistência, no qual
se verifica se não existem conjuntos de axiomas e asserções contraditórios entre si.
2](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-8-320.jpg)
![Relativamente à programação em lógica, embora também lhe possa ser atribuída a se-
mântica da lógica de primeira ordem, semânticas não monótonas – onde adicionar nova
informação pode invalidar conclusões previamente derivadas – como a dos modelos es-
táveis e a dos modelos bem fundados, são habitualmente mais vantajosas. Ambas as
semânticas se baseiam no conceito de modelo canónico, onde a resposta para uma dada
query a um programa em lógica é determinada por um modelo canónico do programa,
que é seleccionado de acordo com uma certa definição de semântica, que pode, dessa
forma, estabelecer uma certa noção senso comum – algo essencial ao ser humano, que
o permite raciocinar com base em conhecimento incompleto ou ambíguo, e rever esse
conhecimento quando na presença de nova informação.
As lógicas de descrição e a programação em lógica exibem certas limitações, e as
limitações de uma podem ser compensadas pelas potencialidades de outra. Desta forma,
problemas de representação complexos requerem, frequentemente, ambas.
As limitações das lógicas de descrição são duas. Primeira, as restrições sintáticas
usadas para garantir decidibilidade no raciocínio, impedem axiomatizar certas relações
que contenham ciclos. Em segundo lugar, como a maioria das lógicas de descrição são
fragmentos da lógica de primeira ordem, não permitem introspecção nem inferências não
monótonas, o que as impede de:
• axiomatizar a assunção do mundo fechado, i.e. a assunção de que todos os factos rele-
vantes são conhecidos e que os que não o são são falsos, inerente às bases de dados
e formalizada, nesse contexto, por Reiter [40];
• suportar raciocínio com base em assunções por omissão, i.e. assumindo que algo é
verdadeiro, a menos que contradiga os factos conhecidos.
Quanto às regras, as limitações devem-se maioritariamente à impossibilidade de raci-
ocinar com domínios ilimitados ou infinitos, i.e. não é possível inferir conclusões acerca
de elementos arbitrários (ex.: de “todos os A são B e todos os B são C” derivar “todos
os A são C”). Sendo, consequentemente, tipicamente usadas em problemas centrados em
dados, como consultas, mas não para raciocinar acerca de esquematizações conceptuais
[37].
Os potenciais benefícios de integrar lógicas de descrição com regras tem sido reco-
nhecidos desde o inicio, e um corpo de investigação significativo tem-se dedicado a essa
problemática [37].
Uma combinação efectiva de regras não monótonas com ontologias em lógicas de des-
crição é vantajosa em vários cenários reais. Por exemplo, nos serviços fronteiriços a avali-
ação de factores de riscos das cargas importadas, como terrorismo, drogas, segurança de
consumidores e violação de tarifas, envolve conhecimento sobre matérias-primas, enti-
dades empresariais, sobre o comércio, as politicas governamentais e acordos comerciais.
Nesse cenário, a classificação das importações ou exportações de acordo com o conheci-
mento taxonómico inerente a esse domínio poderia processar-se recorrendo aos serviços
de raciocínio fornecidos pelas lógicas de descrição; as leis, regulamentos, e políticas de
3](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-9-320.jpg)
![classificação poderiam ser representadas com regras não monótonas. Em geral, qualquer
domínio em que a integração e acesso inteligente a dados e a representação e avaliação
de politicas de negócios, regulamentos, ou mapeamentos entre fontes de informação se-
jam necessários, pode beneficiar do uso dessa combinação de ontologias com regras – e
em alguns casos, essa poderá vir a ser a melhor solução.
Outro exemplo (adaptado de [30]), simplificado mas concreto, que será usado ao
longo da presente exposição para elucidar vários conceitos, é o seguinte.
Exemplo 1. Considere-se uma loja online de venda de música. Com o intuito de atrair
mais utilizadores e aumentar as vendas, decidiu-se introduzir ferramentas mais sofisti-
cadas para as recomendar e procurar.
Para esse propósito, foi usada uma ontologia para estruturar e manter os dados das
músicas. Cada uma tem um identificador único e pode ser associada com o artista, o
compositor, o género, e a origem da música.
Além disso, o sistema deve permitir expressar directrizes, tanto baseadas num critério
geral como nas especificações do utilizador. Por exemplo, a loja pode recomendar a todos
os clientes músicas que são mais vendidos. Ou algum cliente pode desejar que lhe se-
jam recomendados músicas que ainda não tenha e que, de acordo com algum critério de
preferência, provavelmente goste. Enquanto que a primeira directriz pode ser represen-
tada na ontologia, a segunda requer assunção do mundo fechado (e.g., para inferir "por
omissão", i.e., na ausência de evidencias em contrário, que o cliente não tem a música) e
podem ser representadas através de regras não monótonas.
Actualmente, foram já definidos alguns formalismos que permitem, de forma mais
ou menos limitada, essa combinação. Destacam-se, entre eles, pelas suas propriedades
ou meramente por motivos históricos, os seguintes: SWRL [23, 25], DLP [20], AL-log [11],
CARIN [34], DL + log [41], Horn-SHIQ [26], MKNF hibrido [30, 37], programas dl [13,
14], programas dl disjuntivos [16], lógica de equilíbrio quantificado para bases de conhecimento
híbridas [16], grafos de descrição [36] , esquemas nominais [31], regras híbridas sob semântica
bem fundada [12] e programas HEX [15]. O MKNF 1 híbrido apresenta algumas vantagens
importantes sobre as outras abordagens.
Motik e Rosati discutem em [37] essa proeminência do MKNF híbrido face às outras
abordagens, defendendo que um tal formalismo, que integre ontologias DL e programas
em lógica, deve satisfazer certos critérios, e constatando que, de entre os formalismos
na altura conhecidos, o MKNF híbrido é o único que os satisfaz a todos. Os critérios que
enunciou foram os seguintes:
1. fidelidade – a integração entre DL e regras deve preservar a semântica de ambos os
formalismos, i.e. a semântica de uma base de conhecimento híbrida na qual um dos
componentes é vazia deve ser a mesma que a do outro componente;
1
Do inglês, Minimal Knowledge and Negation as Failure
4](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-10-320.jpg)
![2. estreiteza – as regras não devem constituir uma camada sobre as DL nem o contrário;
em vez disso, a integração entre as duas deve ser estreita, no sentido que ambas
devem poder contribuir com consequências para o outro componente;
3. flexibilidade – o formalismo híbrido deve ser flexível e permitir que o mesmo predi-
cado seja visto sob a perspectiva do mundo aberto e do mundo fechado, enriquecendo
assim as DL com consequências não monótonas e as regras com capacidades de ra-
ciocínio taxonómico;
4. decidibilidade – o formalismo deve ser decidível, e, de preferência, de baixa comple-
xidade.
Além dessas propriedades, já de si vantajosas face às obtidas nas outras abordagens
a bases de conhecimento híbridas, é de notar, e é particularmente relevante no contexto
desta dissertação, a existência de um algoritmo, o SLG(O) (ver capítulo 4), para a semân-
tica a três valores de verdade apresentada em [30], que permite interrogar tais bases de
conhecimento com complexidade de dados polinomial, no caso de DLs onde as consul-
tas sejam polinomiais – como é o caso do OWL 2 QL. Esse algoritmo opera directamente
sobre as regras da base de conhecimento e delega o raciocínio relativo à ontologia a me-
canismos de inferência DL externos. Como as bases de conhecimento híbridas MKNF são
paramétricas quanto à DL usada, esse mecanismo de inferência é visto como um oráculo
– uma abstração dos referidos mecanismos, que define as propriedades que estes tem de
satisfazer para garantir a correcção e completude do algoritmo.
Embora quase todas as alternativas mencionadas alcancem, com algumas restrições,
a decidibilidade, os critérios da fidelidade, estreiteza, e flexibilidade, não são satisfeitos si-
multaneamente. Em traços gerais, as abordagens à combinação de ontologias DL com
regras, actualmente conhecidas, passam por: manter os dois componentes, ontologias
e regras, separados tanto sintática como semanticamente, i.e. os dois componentes se-
rem expressos em termos de vocabulários disjuntos e atribuir-se-lhes semânticas distin-
tas, integrando-se apenas por meio de uma interface (ex., introduzindo, no componente
das regras, predicados especiais que permitam consultar a ontologia, como é o caso nos
programas dl), o que impede que os critérios da estreiteza e da flexibilidade se verifiquem;
ter-se uma semântica unificadora, o que se traduz em estreiteza na integração, mas ter-se
ainda vocabulários disjuntos, não se verificando assim a flexibilidade; e finalmente, uma
integração completa, tendo-se um só vocabulário e uma só semântica para (a combinação
de) os dois componentes, onde esses critérios da estreiteza e flexibilidade são satisfeitos.
Entre as últimas, o MKNF híbrido é a única que garante fidelidade.
Um interesse renovado na integração das lógicas de descrição com regras tem sido im-
pulsionado pelo advento da Web Semântica [37]. De acordo com um dos seus principais
precursores, Tim Berners-Lee et al., a Web Semântica é uma extensão da Web onde se as-
socia à informação um significado preciso, i.e. inteligível não só para o utilizador como
para as próprias máquinas, de modo a permitir uma melhor cooperação entre computa-
dores e pessoas, e a proporcionar um ambiente onde agentes de software, transitando de
5](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-11-320.jpg)
![página em página, possam realizar tarefas sofisticadas para os seus utilizadores [5].
Desde o seu inicio até aos dias de hoje, essa concepção de Web Semântica tem vindo a
ser refinada, sendo actualmente possível mapeá-la numa arquitectura bem definida, em
que alguns dos componentes já foram desenvolvidos e já são recomendação da W3C 2
(ver figura 1).
Figura 1: Pilha tecnológica da Web Semântica (adaptado de [8])
Um dos componentes já desenvolvidos é o relativo às ontologias – i.e., colecções de
informação que especificam, formalmente, conceptualizações partilhadas, ou, por ou-
tras palavras, vocabulários de termos, definidos através das suas relações, mantidas em
documentos acessíveis na Web [5]. É nesta componente que as lógicas de descrição de-
sempenham um papel crucial, dando suporte teórico à linguagem OWL Web Ontology
Language – actual recomendação da W3C para a representação de ontologias.
A semântica formal e a existência de ferramentas de raciocínio eficientes e compro-
vadamente correctas, como Pellet, FaCT++ e RACER, têm feito da OWL a linguagem de
escolha para aplicação prática em diversos campos como biologia, medicina, geografia,
astronomia, agricultura e defesa. Essa extensiva experiência prática tem confirmado os
benefícios do uso das lógicas de descrição para a representação de conhecimento, mas
também tem realçado as suas limitações, já discutidas neste documento [37].
No que diz respeito às regras, cujo papel é descrever consequências de dadas infor-
mações, que tanto podem ser a derivação de planos de acção como a de novas informa-
ções [5], existem também alguns raciocinadores como os interpretadores Prolog, o XSB 3,
o clasp 4, o cmodels 5 e o DLV-complex 6. Há também um formato padrão, recomendado
2
http://www.w3.org/
3
http://xsb.sourceforge.net/
4
http://www.cs.uni-potsdam.de/clasp/
5
http://www.cs.utexas.edu/users/tag/cmodels/
6
https://www.mat.unical.it/dlv-complex/
6](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-12-320.jpg)
![pela W3C, para as representar, o RIF, que suporta ambos os tipos de regras mencionados
[6]. No entanto, ainda não existem muitas ferramentas de raciocínio que as suportem
de forma integrada com a camada ontológica. Uma dessas ferramentas, e aquela que
se considera a que apresenta melhores propriedades, precisamente por adoptar como
fundamento teórico o MKNF híbrido e implementar a resolução SLG(O), beneficiando
assim das vantagens já discutidas, é o NoHR.
Na sua versão original, o NoHR suporta apenas o perfil 7 OWL 2 EL do OWL. Definiu-
se em [28], para esse efeito, um oráculo SLG(O) para EL+
⊥
8, que se baseia na tradução
da ontologia para regras equivalentes, quanto às repostas obtidas para as queries, e res-
pectiva avaliação recorrendo ao próprio SLG(O). Deste modo, elimina-se a necessidade
de recorrer raciocinadores DL externos e reduz-se o SLG(O) a um algoritmo já imple-
mentado, de forma comprovadamente efectiva – o SLG, aplicado no XSB. A ontologia de
entrada é reduzida de modo a que os construtores que não podem ser expressos, ou não
têm significado, sob a forma de regras, possam ser ignorados, sem que se percam deri-
vações relevantes – para o que se recorre ao serviço de classificação do raciocinador DL
ELK 9; depois traduzida para regras Prolog, as quais são posteriormente utilizadas no
XSB Prolog, para responder se às queries.
Além do OWL 2 EL, é importante que o NoHR suporte os vários perfis do OWL, um
vez que, cada um deles se adequa a contextos distintos. Entre os três perfis da OWL 2
DL [19], merece particular destaque o OWL 2 QL, que tem suporte teórico na lógica de
descrição DL-LiteR (ver Secção 1.5), pelas seguintes características:
• suporta mecanismos de interrogação completos e consistentes com complexidade
LOGSPACE (AC0) quanto aos dados 10;
• permite expressar os principais elementos de modelos conceptuais como Diagra-
mas de Classes UML e Diagramas de Entidades e Relações;
• torna possível armazenar os dados em Bases de Dados relacionais padrão e poste-
riormente interrogá-los, através da ontologia, por meio de um simples mecanismo
de reescrita, em que a query é traduzida para SQL para ser lançada a um Sistema
de Gestão de Bases de Dados, sem qualquer mudança nos dados.
Tais características fazem dele um perfil adequado a grande parte das aplicações Web
actuais, e outras, que lidam com grandes volumes de dados e onde responder a queries
seja a tarefa de raciocínio mais importante.
Uma aplicação relevante do OWL 2 QL é o Acesso a Dados Baseado em Ontologias
(OBDA), que corresponde a uma combinação de uma camada de dados, como Bases de
7
Os perfis do OWL são versões reduzidas que sacrificam alguma da expressividade original para permitir
um raciocínio mais eficiente.
8
Um fragmento importante do EL++
.
9
Note-se que o raciocinador DL só é necessário na fase de tradução da ontologia; após traduzida, todas
as queries podem ser respondidas sem ele, recorrendo apenas ao XSB Prolog.
10
Isto é, quanto à ABox (ver secção 1.1)
7](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-13-320.jpg)




![1
Lógicas de Descrição
As Lógicas de Descrição (DL) [4] são uma família de formalismos de representação de
conhecimento que representam o conhecimento de um domínio definindo, em primeiro
lugar, os conceitos do domínios (a sua terminologia), e depois usando esses conceitos
para especificar propriedades de objectos ou indivíduos do domínio (a “descrição do
mundo”). As Lógicas de Descrição suportam os padrões de inferência que ocorrem em
muitas aplicações de sistemas de processamento inteligente de informação, e que são
também usados pelos humanos para entender e estruturar o mundo: a classificação de
conceitos e indivíduos.
A classificação de conceitos determina as relações de subconceito/superconceito (ha-
bitualmente chamadas de subsunção, neste contexto) entre os conceitos da terminologia,
permitindo assim estruturá-los numa hierarquia de subsunções – o que não só fornece
informação útil sobre a relação entre esses conceitos, como contribui para outros servi-
ços de inferência. A classificação de indivíduos determina se um dado individuo é ne-
cessariamente instância de um certo conceito, i.e. se, da informação explicitada, se pode
concluir que o individuo é instância desse conceito, em todos os cenários que se coadu-
nem com essa informação, fornecendo assim novo conhecimento sobre as propriedades
desses indivíduos.
A decidibilidade e complexidade dos serviços de inferência, classificação e outros,
depende do poder expressivo da DL em causa. Por um lado, DLs demasiado expressivas
podem tornar tais serviços intratáveis, ou até mesmo indecidíveis. Por outro lado, DLs
com muito pouco poder expressivo – e assim, com serviços de raciocínio mais eficientes
– podem não ser suficientemente expressivas para representar conceitos importantes de
determinados domínios. Assim, o compromisso entre a expressividade das DLs e com-
plexidade dos respectivos serviços de inferência tem sido um dos aspectos mais centrais
12](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-18-320.jpg)


![1. LÓGICAS DE DESCRIÇÃO 1.2. Semântica
O axioma 1.5 assegura que cada música tem pelo menos um artista, enquanto que
o 1.6 restringe o contradomínio da relação HasArtist para Artist, e 1.7 o contradomínio de
HasComposed para Piece. O axioma 1.8 indica que se algo foi composto por um certo
indivíduo, essa composição tem-no como artista. O axioma 1.9 define Composer como
subconjunto dos indivíduos que compuseram algo.
Os axiomas 1.6-1.9, por si só, já permitem derivar que um compositor é um artista.
É de notar que essa conclusão é possível mesmo sem a presença de nenhum compositor
ou música. Tal é o efeito que se pretende quando se raciocina, com esquemas de conhe-
cimento, em domínios infinitos. Não obstante, é evidente que havendo informação espe-
cífica é possível usá-la para derivações acerca de indivíduos específicos. Por exemplo, na
presença da asserção 1.14 é possível derivar que GeorgeGershwin é um artista.
O axioma 1.10 expressa uma directiva de recomendação geral: CDs que sejam mais
vendidos são automaticamente recomendados aos clientes. O axioma 1.11 garante que
um CD entre os menos vendidos nunca é recomendado. Tal é particularmente útil para
restringir as recomendações específicas para cada cliente.
O axioma 1.12 é uma restrição de integridade, que garante que algum engano na
introdução dos dados em que um peça fique classificada como artista ou vice-versa é
detectado 1.
As asserções 1.13-1.16 indicam que Blue Train tem John Coltrane como artista, que
George Gershwin compôs Rhapsody In Blue, que Gustav Mahler é compositor, e que Blue
Train é um CD dos mais vendidos, respectivamente.
1.2 Semântica
A semântica das Lógicas de Descrição é dada em termos de interpretações, I = ∆I , .I ,
que consistem num domínio de interpretação não vazio ∆I e uma função de interpreta-
ção .I , que atribui a cada conceito C um subconjunto CI de ∆I , e a cada relação R uma
relação binária RI sobre ∆I – as extensões do conceito ou relação, respectivamente.
A tabela 1.1 2 especifica as principais expressões permitidas em Lógicas de Descrição
e respectiva semântica. As expressões permitidas em descrições de conceitos, aqui deno-
tados por C, e as descrições de relações, denotados por R, estão incluídas nessa tabela.
Uma interpretação I é um modelo de uma axioma de subsunção C1 C2 (resp.,
R1 R2), se C1
I
⊆ C2
I
(resp., R1
I
⊆ R2
I
).
1
É discutível o quão realista se poderia considerar a inclusão de um tal axioma numa ontologia aplicada
ao contexto prático descrito. O proposito deste axioma é principalmente permitir expor certas propriedades
em exemplos subsequentes (ver exemplo 60).
2
As expressões apresentadas nessa tabela, com a excepção do complemento de relações (¬R), correspon-
dem aquelas que são permitidas em SROIQ, [24] a DL na qual a linguagem OWL 2 DL se fundamenta [38].
Além dessas expressões também são permitidos axiomas de simetria, assimetria, transitividade, reflexivi-
dade, irreflexividade, e disjunção para as relações. São também impostas certas restrições nos axiomas de
subsunção de relações, de modo a preservar decidibilidade. Tal não é, no entanto, relevante para a presente
exposição.
15](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-21-320.jpg)

![1. LÓGICAS DE DESCRIÇÃO 1.3. Queries
Para especificar a semântica das asserções de pertença, estende-se a função de in-
terpretação para constantes, atribuindo a cada constante a um objecto aI ∈ ∆I . Uma
interpretação I é um modelo de uma asserção C(a) (resp., R(a, b)), se aI ∈ CI (resp.,
(aI , bI ) ∈ RI ).
Dado um axioma de subsunção ou uma asserção de pertença α, e uma interpretação
I, denota-se por I |= α o facto de I ser um modelo de α. Dado um conjunto (finito) de
asserções K, denota-se por I |= K o facto de I ser um modelo de todas as asserções em
K. Um modelo de uma KB O = T , A é uma interpretação I tal que I |= T e I |= A.
Diz-se que uma KB é satisfazível se tiver pelo menos um modelo; e que uma asserção
α é consequência lógica de uma KB K, o que se denota por O |= α, se todos os modelos
de K forem também modelos de α.
1.3 Queries
Define-se união de queries conjuntivas q do seguinte modo
q = {x |
i=1,...,n
∃yi. conji(x, yi)} (1.17)
onde cada conji(x, yi) é uma conjunção de átomos e igualdades, com variáveis livres x e
variáveis fechadas yi. Dada uma interpretação I, qI é o conjunto de tuplos de elementos
do domínio que, quando atribuídos às variáveis livres da fórmula i=1,...,n ∃yi. conji(x, yi),
a tornam verdadeira em I. Uma união de queries conjuntivas sobre uma ontologia O é uma
união de queries conjuntivas cujos os átomos são da forma A(z) ou P(z1, z2), onde A e P
denotam, respectivamente, um conceito atómico e uma relação atómica de O, e z, z1, z2
são constantes em O ou variáveis.
1.4 EL+
⊥
O EL+
⊥ é um fragmento da lógica de descrição EL++ [3], na qual o perfil OWL 2 EL se
baseia [19]. O conjunto de expressões permitidas em EL+
⊥é dado pela seguinte gramática:
C → A | | ⊥ | C C | ∃R.C
R → P | R ◦ R
T → C C | R P
U → C(a) | R(a, b)
onde A denota um conceito atómico; P uma relação atómica; C uma descrição de conceito; R
uma descrição de relação; T um axioma de subsunção; e U uma asserção de pertença.
Um dos resultados interessantes da DL EL++
– e assim, do EL+
⊥– é o da subsunção
17](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-23-320.jpg)


![2. PROGRAMAÇÃO EM LÓGICA 2.1. Modelos estáveis
com essa ideia de modelo canónico, são apresentadas nas secções 2.1 e 2.2.
2.1 Modelos estáveis
Como mencionado, o universo de Herbrand de um programa em lógica P é o conjunto, HP,
de todos os termos formados pelos símbolos de função que ocorrem nesse programa
(incluindo constantes). Um átomo (resp., regra ou programa) instanciado obtém-se subs-
tituindo todas as variáveis livres desse átomo (resp., regra ou programa) por termos
do universo de Herbrand. A base de Herbrand de P é o conjunto, ˆHP, dos átomos ins-
tanciados, P(t1, · · · , tn), formados por um símbolo de predicado, P, que ocorrem no
programa e os termos, t1, · · · , tn, pertencentes a HP. Uma interpretação de Herbrand,
I, de um programa P é um subconjunto de ˆHP, e associa a cada símbolo de predi-
cado n-ário em P uma única relação n-ária em HP – para um predicado P, a relação
{(t1, . . . , tn) | P(t1, . . . , tn) ∈ I}.
Uma interpretação de Herbrand, I, é modelo de Herbrand de α, denotado por I |= α,
se:
1. α é um átomo instanciado P(t1, · · · , tn) e P(t1, · · · , tn) ∈ I;
2. α é um literal instanciado negativo not A e A ∈ I;
3. α é uma regra instanciada H ← A1, · · · , Am, not Bm+1, · · · , not Bn e I não é modelo
de algum literal Ai ou not Bj ou I é modelo de H; ou
4. α é um programa instanciado P e I é modelo de todas as regras contidas em P.
Define-se ainda modelo mínimo de Herbrand de um programa P, least(P): um modelo
de Herbrand de P, M, tal que, para qualquer modelo de Herbrand M de P, M ⊆
M . Um programa positivo, i.e. no qual não ocorrem literais negativos, tem um único
modelo mínimo de Herbrand. Por causa dessa univocidade, e por ser um modelo que
atribui uma semântica compatível com o senso comum – é razoável assumir que com um
programa, assim como com outras formas de representação de conhecimento, se pretende
expressar apenas o que é necessariamente verdadeiro, em vez de tudo o que pode, ou não,
ser verdadeiro – é esse o modelo canónico para programas positivos.
Já num programa negativo, tal não possível, uma vez que este pode ter vários mode-
los mínimos de Herbrand. Assim, em [18] define-se, para um dado programa instanciado
P e um subconjunto M, de ˆHP, o programa PM, obtido de P removendo:
1. cada regra na qual ocorra um literal negativo not B no seu antecedente, se B ∈ M;
2. todos os literais negativos nos antecedentes das restantes regras.
Assim definido, PM é um programa positivo, pelo que tem um único modelo minimo
de Herbrand, least(PM). Se least(PM) = M então M é o conjunto estável ou modelo
estável de P.
20](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-26-320.jpg)
![2. PROGRAMAÇÃO EM LÓGICA 2.2. Modelos bem fundados
Os conjuntos estáveis de um dado programa P podem ser entendidos como “os pos-
síveis conjuntos de crenças que um agente racional pode ter se lhe são dadas como pre-
missas o programa P” [18].
Se M é o conjunto de factos que se considera verdadeiros, então qualquer regra que
contenha no antecedente um literal not B tal que B ∈ M, é nesse ponto e vista, inútil; e
que contenha no antecedente not B com B ∈ M, trivial. Assim, as premissas de P podem
ser substituídas por PM. Se um conjunto de átomos M escolhido é precisamente aquele
que segue logicamente do conjunto simplificado de premissas PM, então essa escolha é
racional.
A semântica dos modelos estáveis é definida para um program P, se P tem exacta-
mente um modelo estável, e estabelece esse modelo como o modelo canónico de P.
Esta semântica dos modelos estáveis é aplicada na Answer Set Programming – um pa-
radigma de programação orientado para problemas de procura.
2.2 Modelos bem fundados
Em [17] desenvolve-se o conceito de conjuntos infundados. Define-se do seguinte modo.
Seja P um programa em lógica, com base de Herbrand ˆHP, e I uma interpretação de P.
U ⊆ ˆHP é um conjunto infundado (de P) relativamente a I se cada regra instanciada r de
P, cujo o átomo do consequente, H, está contido em U, H ∈ U, satisfaz uma das seguintes
condições:
(i) I |= A ou I |= not B, para algum A ou not B do antecedente de r; ou
(ii) algum literal positivo do antecedente de r, A, pertence a U, A ∈ U.
Intuitivamente, I corresponde ao que é conhecido de antemão acerca do modelo pre-
tendido para P. As regras que satisfazem a condição (i) não permitem novas derivações,
uma vez que as suas hipóteses já são conhecidas como falsas. A condição (ii) é a condição
de não fundamentação: a derivação de um dado literal, A, de U depende da derivação
de outros literais também contidos em U, pelo que, nenhum literal em U pode ser esta-
belecido como verdadeiro pelas regras de P, e partindo de I, em primeiro lugar. Deste
modo, se se estabelecer como falsos todos os átomos em U, não há nenhuma forma de
derivar posteriormente a sua verdade.
21](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-27-320.jpg)
![2. PROGRAMAÇÃO EM LÓGICA 2.2. Modelos bem fundados
Exemplo 3. Considere-se o programa consistindo nas seguintes regras (instanciadas) [17]:
p(a) ← p(c), not p(b). (2.2)
p(b) ← not p(a). (2.3)
p(e) ← not p(d). (2.4)
p(c). (2.5)
p(d) ← q(a), not q(b). (2.6)
p(d) ← q(b), not q(c). (2.7)
q(a) ← p(d). (2.8)
q(b) ← q(a). (2.9)
Os átomos {p(d), q(a), q(b), q(c)} formam um conjunto infundado relativamente ao
conjunto ∅. Em particular, {q(c)} é infundado pela condição (i) – não existe nenhuma re-
gra que possa ser usada para estabelecer a sua verdade. O conjunto {p(d), q(a), q(b)} é
infundado pela condição (ii) – não há forma de estabelecer p(d) sem primeiro estabelecer
q(a) ou q(b) (embora se possa estabelecer ¬q(b), para suportar a primeira regra com con-
sequente p(d), tal é irrelevante quanto à obtenção dos conjuntos infundados). De modo
similar, não existe forma de estabelecer q(a) sem primeiro estabelecer p(d), e não existe
forma de estabelecer q(b) sem primeiro estabelecer q(a). Claramente q(c) nunca pode ser
provado, mas além disso, pode também constatar-se que entre p(d), q(a), e q(b), nenhum
pode ser provado em primeiro lugar.
Contrariamente, {p(a), p(b)} não constitui um conjunto infundado apesar de cada ele-
mento depender do outro, pois as dependências dão-se apenas "através"da negação. Se-
ria tentador afirmar que tentativas de provar p(a) e p(b) também falhariam, mas tal afir-
mação é errónea.
A diferença entre os conjuntos {p(d), q(a), q(b)} e {p(a), p(b)} é a seguinte: declarar
um dos átomos p(d), q(a), q(b) como falso não permite provar a verdade de nenhum dos
outros atámos. Contudo, uma vez que um dos átomos p(a) ou p(b) se declare falso,
torna-se possível provar que o outro é verdadeiro; e se ambos foram declarados como
falsos, tem-se uma inconsistência.
A semântica bem fundada usa as condições (i) e (ii) para obter as conclusões negati-
vas: estabelece todos os átomos em U como negativos.
A semântica bem fundada de um dado programa é definida pelo menor ponto fixo
de uma sequência transfinita obtida pela aplicação sucessiva de uma transformação de
conjuntos de literais. Essa transformação é definida do seguinte modo. Considere-se
um programa P. Seja TP(I) o conjunto dos átomos dos consequentes das regras cujos
literais do antecedente são verdadeiros em I e UP(I) o maior conjunto infundado de P
relativamente a I, i.e. a união de todos os conjuntos que são infundados relativamente a
I. A transformação é definida por WP(I) = TP(I) ∪ {not B | B ∈ UP(I)}; e a sequência
22](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-28-320.jpg)
![2. PROGRAMAÇÃO EM LÓGICA 2.2. Modelos bem fundados
por:
I0 = ∅ (2.10)
In+1 = WP(In) (2.11)
Iδ =
α<δ
Iα (2.12)
Denote-se por M o menor ponto fixo dessa sequência. A semântica bem fundada de um
programa P é o “significado” representado por M. A ∈ M denota que A é verdadeiro;
not B ∈ M, que B é falso. Para os literais da base de Herbrand para os quais nenhuma
dessas condições se verifique, a semântica não atribui nenhum valor de verdade (ou atri-
bui o valor indefinido). Se M inclui todos os átomos da base de Herbrand, então é um
modelo total e é designado modelo bem fundado; caso contrário é designado modelo parcial
bem fundado.
Dois resultados importantes, que relacionam os modelos bem fundados com os mo-
delos estáveis são os seguintes: se um dado program P tem um modelo total bem fun-
dado então esse modelo é o único modelo estável; e, um modelo parcial bem fundado de
um programa P é um subconjunto de qualquer o modelo estável de P.
A semântica bem fundada tem complexidade de dados, i.e. complexidade computa-
cional de decidir uma resposta para uma query atómica instanciada (neste caso, decidir
qual o valor de verdade de um dado átomo, de acordo com o modelo parcial bem fun-
dado), em função do número de factos, PTIME.
Entre os vários algoritmos existentes para avaliação de queries a programas em lógica,
merece particular destaque o SLG [10] (Linear resolution with Selection function for Gene-
ral logic programs), uma vez que este permite computar a semântica bem fundada com
complexidade temporal de dados polinomial, havendo, contrariamente a outros, a ga-
rantia de terminação 4; e é independente da estratégia de controlo, i.e. a ordem pela qual
os literais surgem nas regras não afecta o resultado – opostamente ao que acontece com o
SLD, que é, nesse aspecto, menos declarativo. O SLG é definido com base numa série de
transformações que transformam, passo a passo, cada query num conjunto de regras de
resposta (ver capitulo 4). Este algoritmo é aplicado no XSB [10] – um sistema dedutivo
para programas em lógica, comprovadamente efectivo.
4
Em programas limitados na profundidade dos termos.
23](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-29-320.jpg)
![3
Bases de Conhecimento MKNF
MKNF (Minimal Knowledge and Negation as Failure) é uma lógica epistêmica não monótona
que estende a lógica de primeira ordem com um operador de introspecção – permite fazer
referência ao que é conhecido, i.e. à própria KB – e o operador de negação por omissão.
Essa lógica permite representar teorias de primeira ordem e programas em lógica não
monótona, preservando a sua semântica – a dos modelos estáveis ou a modelos bem
fundados, no caso dos programas em lógica.
Baseando-se nessas características da lógica MKNF, em [37] Motik e Rosati definem
bases de conhecimento híbridas MKNF. Tais bases de conhecimento integram completa-
mente ontologias DL e programas em lógica não monótonas, e, além de satisfazerem
os critérios da estreiteza, e da flexibilidade, satisfazem o da fidelidade – a semântica que lhes
é atribuída preserva a semântica clássica, na componente da ontologia DL, e dos mode-
los estáveis, na componente das regras. Com algumas restrições (segurança DL), que não
afectam significativamente a expressividade, garante-se a decidibilidade.
Em [30] estende-se a semântica originalmente definida para as bases de conhecimento
híbridas MKNF de [37], com modelos a dois valores de verdade, para uma de mode-
los a três valores. Essa semântica permite não só aproximar a semântica dos modelos
estáveis como também aplicar a noção de modelos bem fundados da programação em
lógica às bases de conhecimento híbridas. Além disso, o seu modelo canónico – o mo-
delo MKNF bem fundado – é computável com complexidade de dados menor ou igual à
modelos MKNF a dois valores.
Além dos quatro critérios enumerados anteriormente a abordagem das bases de co-
nhecimento híbridas MKNF tem algumas propriedades importantes. Em bases de conhe-
cimento consistentes, é coerente no sentido de [39], i.e. se uma fórmula ϕ é falsa clas-
sicamente na ontologia, então a interpretação não monótona de ϕ nas regras é forçada
24](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-30-320.jpg)
![3. BASES DE CONHECIMENTO MKNF 3.1. Sintaxe
a ser também falsa; permite detectar inconsistências sem nenhum esforço de computa-
ção adicional substancial, além da verificação de consistência da ontologia apenas; e, a
complexidade computacional de dados da abordagem depende da complexidade da DL
aplicada, sendo que, se a DL tiver complexidade polinomial, a combinação com as regras
mantém-se polinomial.
Nas próximas secções deste capitulo introduz-se a lógica MKNF e definem-se bases de
conhecimento híbridas MKNF (Secção 3.1) e a sua semântica (Secção 3.2).
3.1 Sintaxe
A lógica de conhecimento mínimo e negação por falha (MKNF) [30] estende a lógica de pri-
meira ordem com os operadores modais K e not . Informalmente, K ϕ pode ser lido
como “sabe-se ϕ” e not ϕ como “não se sabe ϕ”. O operador not permite inferências
com base em ausência de informação, de forma semelhante à negação por omissão da
programação em lógica.
As fórmulas MKNF são definidas do seguinte modo. Seja Σ = (Σc, Σf , Σp) uma assi-
natura de primeira ordem, onde Σc é um conjunto de constantes, Σf é o conjunto de sím-
bolos de função, e Σp é o conjunto de predicados contendo o predicado de igualdade ≈.
Um átomo de primeira ordem P(t1, · · · , tn), onde P é um predicado e ti são termos de pri-
meira ordem, é uma fórmula MKNF. Se ϕ é uma fórmula MKNF, então ¬ϕ, ∃x : ϕ, K ϕ
e not ϕ são fórmulas MKNF, assim como ϕ1 ∧ ϕ2, para fórmulas MKNF ϕ1 e ϕ2. Além
disso, ϕ1 ∨ ϕ2, ϕ1 ⊃ ϕ2, ϕ1 ≡ ϕ2, ∀x : ϕ, t, f, t1 ≈ t2, e t1 ≈ t2 são abreviações, respecti-
vamente, para ¬(¬ϕ1 ∧ ϕ2), ¬ϕ1 ∨ ϕ2, (ϕ1 ⊃ ϕ2) ∧ (ϕ2 ⊃ ϕ1), ¬(∃x : ¬ϕ), a ∨ ¬a, a ∧ ¬a,
≈ (t1, t2), e ¬(t1 ≈ t2).
As bases de conhecimento hibridas MKNF são essencialmente fórmulas MKNF res-
tritas e consistem em dois componentes: uma ontologia DL expressável em lógica de
primeira ordem e um conjunto finito de regras. Constituem, desse modo, uma possí-
vel abordagem à combinação de Lógicas de Descrição com programas em lógica, e são
aplicáveis a qualquer lógica de descrição DL que seja um fragmento de primeira ordem
e satisfaça as seguintes condições 1:
1. cada base de conhecimento O ∈ DL pode ser traduzida (ver tabela 1.1) para uma
fórmula π(O) de primeira ordem sem funções com igualdade;
2. DL suporta asserções de pertença da forma P(a1, · · · , an), onde P é um predicado
e cada ai é uma constante de DL; e
3. a verificação de satisfazibilidade e verificação de instanciação (i.e verificação de
consequências lógicas da forma O |= P(a1, ..., an)) são decidíveis.
Uma regra MKNF r, com átomos de primeira ordem sem funções H, Ai e Bi, tem a
1
As lógicas de descrição subjacentes à OWL satisfazem estas condições.
25](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-31-320.jpg)
![3. BASES DE CONHECIMENTO MKNF 3.1. Sintaxe
forma 2 :
K H ← K A1, · · · , K An, not B1, · · · , not Bm (3.1)
onde K H, K A1, · · · , K An, e not B1, · · · , not Bm são denominados consequente, antece-
dente positivo e antecedente negativo, respectivamente. Uma regra MKNF é positiva se m = 0
e é um facto se n = m = 0; é DL-segura se toda a variável que nela ocorre, ocorre em
pelo menos um átomo não DL, i.e. que não ocorre na ontologia DL em causa, do seu
antecedente positivo. Um programa MKNF P é um conjunto finito de regras MKNF.
Uma base de conhecimento híbrida MKNF K é um par (O, P), onde O é uma ontolo-
gia DL expressável em lógica de primeira ordem e P um programa MKNF. K diz-se
DL-segura se todas as regras em K são DL-seguras. A semântica das bases de conheci-
mento MKNF híbridas é dada pela semântica das fórmulas MKNF com as quais se pode
representá-las, havendo a garantia que, se forem MKNF-consistentes e DL-seguras, têm
um e um só modelo bem fundado MKNF (ver secção 3.2).
Para expressar uma base de conhecimento híbrida K = (O, P), tal como definida,
numa fórmula MKNF válida, estende-se a transformação π do seguinte modo, onde r é
uma regra MKNF na forma 3.1 e x é o vector de variáveis livres de r:
π(r) = ∀x : (K A1 ∧ · · · ∧ K An ∧ not B1 ∧ · · · ∧ not Bm ⊃ K H) (3.2)
π(P) =
r∈P
π(r) (3.3)
π(K) = K π(O) ∧ π(P) (3.4)
As bases de conhecimento hibridas MKNF, mesmo sem símbolos de função, são, em
geral, indecidíveis, a menos que restringidas de alguma forma. Isto acontece porque as
regras podem ser aplicadas a todos os objectos de um domínio infinito. Para recuperar
a decidibilidade, basta então restringir a aplicação das regras a apenas indivíduos que
apareçam na base de conhecimento, respeitando a segurança DL, anteriormente definida.
Enquanto que a segurança DL garante que as regras são aplicadas apenas aos indivíduos
que ocorrem numa dada base de conhecimento hibrida MKNF, a sua instanciação (abaixo
definida) garante que são aplicadas a todos eles.
A instanciação3 de uma base de conhecimento hibrida MKNF K = (O, P), é a KB
KG = (O, PG) onde PG é obtido de P por substituição de cada regra r de P com o
conjunto de regras obtido substituindo cada variável em r com constantes de K, de todas
as maneiras possíveis.
Exemplo 4. Considere-se novamente o cenário do Exemplo 1, juntamente com os axio-
mas e asserções do Exemplo 2. Esses axiomas podem ser parte de uma ontologia O de
uma base de conhecimento híbrida MKNF (O, P). Em P pode expressar-se directivas de
recomendação adicionais, em particular aquelas que requeiram a assunção do mundo
2
Apenas se consideram regras não disjuntivas, i.e. sem disjunções no consequente, porque é para essas
que os resultados de tratabilidade computacional de [30] se verificam.
3
Em Inglês, ground instantiation.
26](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-32-320.jpg)

![3. BASES DE CONHECIMENTO MKNF 3.2. Semântica
consequências dos predicados “definidos” tanto na ontologia como nas regras. O resul-
tado pode ainda ser aplicado para derivar consequências subsequentes e acrescentá-las
em qualquer uma das partes da base de conhecimento.
3.2 Semântica
Embora a lógica MKNF tenha sido originalmente definida em [35], e as bases de conheci-
mento híbridas MKNF em [35], com uma semântica com dois valores de verdade, para o
propósito da dissertação interessa apenas, tal como discutido no início do presente capí-
tulo, a semântica apresentada em [30], com três valores de verdade, pelo que, apenas se
apresenta a semântica ai definida 5. À semelhança do que acontece da programação em
lógica, quando se adoptam modelos a três valores de verdade no lugar de dois obtêm-se
modelos mais "cépticos", no sentido em que há menos compromisso com a verdade ou
falsidade dos factos, e portanto, mais fracos do ponto de vista do conhecimento derivá-
vel, mas, em contrapartida, o raciocínio torna-se computacionalmente menos complexo.
De acordo com a referida semântica, o valor de verdade de uma fórmula MKNF é
definido com base numa estrutura de avaliação. Os valores possíveis são t, f ou u, e
têm a ordenação f < u < t 6. Uma estrutura MKNF é um triplo (I, M, N) constituído
por uma interpretação de primeira ordem I e dois pares M = M, M1 e N = N, N1 de
conjuntos de interpretações de primeira ordem, onde M1 ⊆ M e N1 ⊆ N. Tal estrutura
MKNF diz-se total se M = M, M e N = N, N e parcial caso contrário. Uma dada
estrutura MKNF avalia uma fórmula MKNF de acordo com a figura 3.1.
Note-se que é ao impor-se M1 ⊆ M e N1 ⊆ N na definição de estrutura MKNF
garante-se que nenhum fórmula MKNF é avaliada por nenhuma estrutura MKNF como
verdadeira e falsa simultaneamente.
É de notar também, que, embora as estruturas MKNF permitam avaliar fórmulas
MKNF com três valores de verdade, isso só acontece com as que não sejam de primeira
ordem, i.e. nas quais ocorram os operadores modais K ou not . As restantes são avali-
adas apenas com dois valores de verdade, e exactamente com o mesmo valor com que
seriam valoradas na lógica de primeira ordem, dada a interpretação I. Tal é desejável,
uma vez que se pretende satisfazer o critério da fidelidade e, consequentemente, preservar
a semântica das lógicas de descrição, que, como mencionado, são geralmente fragmentos
da lógica de primeira ordem.
Uma interpretação MKNF consiste num par (M, N) de conjuntos não vazios de inter-
pretações de primeira ordem, M e N, com ∅ ⊂ N ⊆ M. Se M = N, então a interpretação
5
Todas as definições subsequentes dizem-lhe respeito, pelo que não se faz a distinção entre modelos a
dois valores e modelos a três valores, que se faz no artigo original.
6
Do Inglês, true, false e undefined, respectivamente. Subsequentemente denota-se por max(C) e min(C),
de acordo com essa ordenação, como o maior, menor, respectivamente, valor de verdade contido em C.
28](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-34-320.jpg)
![3. BASES DE CONHECIMENTO MKNF 3.2. Semântica
(I, M, N)(P(t1, · · · , tn)) =
t sse (tI
1 , · · · , tI
n) ∈ PI
f sse (tI
1 , · · · , tI
n) ∈ PI
(3.13)
(I, M, N)(¬ϕ) =
t sse (I, M, N)(ϕ) = f
u sse (I, M, N)(ϕ) = u
f sse (I, M, N)(ϕ) = t
(3.14)
(I, M, N)(ϕ1 ∧ ϕ2) = min{(I, M, N)(ϕ1), (I, M, N)(ϕ2)} (3.15)
(I, M, N)(ϕ1 ⊃ ϕ2) =
t sse (I, M, N)(ϕ2) ≥ (I, M, N)(ϕ1)
f caso contrário
(3.16)
(I, M, N)(∃x : ϕ) = max{(I, M, N)(ϕ[α/x]|α ∈ ∆)} (3.17)
(I, M, N)(K ϕ) =
t sse (J, M, M1 , N)(ϕ) = t para todo J ∈ M
f sse (J, M, M1 , N)(ϕ) = f para algum J ∈ M1
u caso contrário
(3.18)
(I, M, N)(not ϕ) =
t sse (J, M, N, N1 )(ϕ) = f para algum J ∈ N1
f sse (J, M, N, N1 )(ϕ) = t para todo J ∈ N
u caso contrário
(3.19)
Figura 3.1: Avaliação das fórmula MKNF
(M, N) é denominada total, caso contrário, parcial. Uma interpretação MKNF (M, N) sa-
tisfaz uma fórmula fechada7 ϕ, o que se denota por (M, N) |= ϕ, se e só se:
(I, M, N , M, N )(ϕ) = t
para todo I ∈ M. Se existe uma interpretação que satisfaça ϕ, então ϕ diz-se consistente.
Uma interpretação MKNF é um modelo MKNF de um dada fórmula MKNF fechada ϕ
se:
(i) (M, N) |= ϕ e
(ii) para cada interpretação MKNF (M , N ) com M ⊆ M e N ⊆ N , onde pelos menos
uma das inclusões é estrita e (M , N ) é total se (M, N) é total, existe I ∈ M tal
que (I , M , N , M, N )(ϕ) = t.
Intuitivamente, pode considerar-se uma interpretação MKNF como uma avaliação
hipotética da fórmula considerada, e que a condição (ii) verifica, tendo fixado a avaliação
dos átomos modais not , se a avaliação dos átomos modais K é mínima relativamente à
ordenação dos valores de verdade. Ilustra-se no exemplo seguinte como essa minimiza-
ção é obtida [30].
7
Sem variáveis livres, i.e. não quantificadas.
29](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-35-320.jpg)
![3. BASES DE CONHECIMENTO MKNF 3.2. Semântica
Exemplo 5. Considere-se a fórmula MKNF ϕ (correspondente a duas regras):
(not p ⊃ K q) ∧ (not q ⊃ K p)
Um par de interpretação MKNF (M, N) que satisfaça a condição (i) da definição an-
terior tem de avaliar ambas os conjunctures como verdadeiros. O par de interpreta-
ção MKNF ({{p}, {p, q}}, {{p, q}}) que avalia K p como t e K q como u satisfaz a pri-
meira condição mas não é um modelo MKNF de ϕ uma vez que não satisfaz a condi-
ção (ii) (considere-se (M , N ) = ({∅, {p}, {q}, {p, q}}, {{p, q}}), por exemplo – na ver-
dade, esse par de interpretação MKNF é um modelo MKNF). O operador not é sem-
pre avaliado relativamente ao par de interpretação MKNF (M, N), mesmo quando se
considera a condição (ii). Portanto, para N = {{p, q}}, as duas implicações são, de qual-
quer forma, verdadeiras; e M tem de ser o conjunto de todas as interpretações possíveis,
{{∅, {p}, {q}, {p, q}}, para satisfazer a condição (ii). Assim, obtém-se o par de interpreta-
ção MKNF que avalia K p e K q como u. Tal mostra que o par de interpretação MKNF
inicial não era minimal relativamente à avaliação dos átomos K . De modo similar à mi-
nimização da avaliação de K p de t para u, mudanças de u para f também são possíveis:
mantém-se M = {{p}, {p, q}} e coloca-se N = M. Agora a avaliação de K q é minimi-
zada de u para f, e é fácil verificar que o par de interpretação MKNF resultante é de facto
um modelo MKNF de ϕ.
Uma dada fórmula MKNF fechada ϕ diz-se MKNF-consistente se admite modelo MKNF
e MKNF-inconsistente caso contrário.
Uma fórmula MKNF fechada ψ é consequência lógica de outra fórmula MKNF fechada
ϕ se, para todos os modelos MKNF (M, N) de ϕ, (I, M, N , M, N )(ψ) = t, o que se
denota por ϕ |=3
MKNF ψ.
Em [30] define-se também um modelo canónico, o modelo MKNF bem fundado, que,
similarmente ao que é habitual na programação em lógica, corresponde ao menor modelo
relativamente ao conhecimento derivável.
Um modelo MKNF (M, N) de uma dada fórmula fechada MKNF ϕ é o modelo MKNF
bem fundado de ϕ, se M1 ⊆ M e N1 ⊇ N, para todos os modelos MKNF de (M1, N1) de ϕ.
Como numa base de conhecimento híbrida MKNF arbitrária com domínio contável
infinito existem infinitos modelos MKNF, trabalhar directamente sobre os eles torna-se
inexequível. Portanto, é necessária uma representação finita. A solução, apresentada
em [30], é representar o modelo MKNF através de uma fórmula de primeira ordem cujo
conjunto de modelos (de primeira ordem) correspondem ao próprio modelo MKNF. In-
tuitivamente, uma tal fórmula é obtida primeiro dividindo os átomos modais ocorrendo
na base de conhecimento híbrida MKNF instanciada em átomos verdadeiros e falsos, e
depois construindo a fórmula de primeira ordem com base nos átomos verdadeiros e na
ontologia. Parte-se do conjunto dos átomos K da base de conhecimento instanciada, que
corresponde ao menor conjunto contendo todos os átomos K ocorrendo nela, e, para
30](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-36-320.jpg)
![3. BASES DE CONHECIMENTO MKNF 3.2. Semântica
cada átomo modal not ϕ, um átomo K ϕ. Uma partição parcial (T, F) desse conjunto con-
siste em dois subconjuntos disjuntos entre si, onde, intuitivamente, T contém todos os
átomos modais verdadeiros, F todos os átomos modais falsos, e um terceiro conjunto,
formado pelos elementos do conjunto dos átomos K que não estão nem em T nem em
F, habitualmente denotado por U, corresponde ao que é considerado indefinido. A cada
interpretação MKNF (M, N) pode fazer-se corresponder uma partição parcial (T, F), a
partição parcial induzida por essa interpretação, de acordo com o seguinte:
1. K ϕ ∈ T implica que, para toda a interpretação I em M, (I, M, N)(K ϕ) = t;
2. K ϕ ∈ F implica que, para toda a interpretação I em M, (I, M, N)(K ϕ) = f; e
3. K ϕ ∈ T e K ϕ ∈ F implica que, para toda a interpretação I em M, (I, M, N)(K ϕ) =
u.
As fórmulas de primeira ordem correspondentes à ontologia e aos átomos em T são satis-
feitas exactamente pelas interpretações de M; as fórmulas correspondentes à ontologia e
aos elementos do conjunto de átomos K que não estão em F são satisfeitas exactamente
pelas interpretações de N. É por tal se verificar que é possível representar qualquer mo-
delo MKNF por meio de uma partição parcial.
Em [30] é apresentada uma computação bottom-up sobre os átomos K de uma dada
KB que permite obter a partição parcial correspondente ao seu modelo MKNF bem fun-
dado. Nessa computação são aplicados, sucessivamente, e de forma cumulativa, dois
operadores – um que faz derivações com base na ontologia e outro com base nas regras
– a duas transformações da KB instanciada, que à semelhança do que acontecia com a
transformação apresentada na Secção 2.1, a tornam positiva – uma similar a essa última e
outra que na qual se tem adicionalmente em conta a negação clássica, de modo a garantir
coerência com a negação por omissão. Em [2] é apresentada uma computação bottom-up
alternativa na qual se aplica uma só transformação a uma versão duplicada da base de
conhecimento (ver Secção 4.2), na qual o algoritmo top-down SLG(O) se baseia.
31](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-37-320.jpg)
![4
SLG(O)
Em [1] é apresentada uma extensão do SLG para bases de conhecimento híbridas MKNF
consistente com a semântica bem fundada, o SLG(O) . No caso de queries DL-seguras, é
decidível com complexidade de dados PC, onde C é a complexidade de responder a uma
query na DL usada na KB em causa.
O algoritmo SLG é introduzido, através de um exemplo, na Secção 4.1. Uma defini-
ção detalhada das operações do SLG pode ser consultada em [42]. A Secção 4.2 descreve
a operação que estende o SLG para bases de conhecimento híbridas MKNF, a Resolução
com Oráculo , que incorpora as derivações da ontologia por meio de um oráculo – um
função que, para uma dada query, um dado conjunto de factos, anteriormente derivados,
devolve um conjunto de factos que em conjunto com os anteriores e a ontologia, é sufici-
ente para provar a query. Além disso, essa secção descreve também uma transformação
de duplicação da base de conhecimento – toda a ontologia e cada regra – que é necessá-
ria aplicar previamente à avaliação SLG(O) de modo a garantir coerência, e para permitir
detectar possíveis inconsistências.
4.1 SLG
Uma avaliação SLG corresponde a uma sequência de florestas de árvores de derivação,
obtidas pela aplicação sucessiva de uma conjunto de operações que criam um novo nó,
uma nova árvore, ou marcam uma certa árvore como completamente avaliada. O se-
guinte exemplo clarifica a ideia exposta [1].
32](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-38-320.jpg)
![4. SLG(O) 4.1. SLG
Exemplo 6. Considere-se a seguinte base de conhecimento híbrida MKNF com O vazio:
p(b) ← (4.1)
p(c) ← not p(a) (4.2)
p(X) ← t(X, Y, Z), not p(Y ), not p(Z) (4.3)
p(a) ← p(b), p(a) (4.4)
t(a, a, b) ← (4.5)
t(a, b, a) ← (4.6)
Figura 4.1: Floresta final para a query p(c) a P1. [1]
Considere-se uma query p(c) a K na qual nenhum dos átomos é DL, i.e. nenhum orá-
culo necessita ser usado. A figura 6 mostra a floresta SLG no fim da avaliação. Nela, cada
nó é etiquetado com um número indicando a ordem no qual foi criado na avaliação SLG.
Um nó consiste ou no símbolo fail, ou numa regra formada por um consequente que re-
presenta um dado subgolo atómico e as substituições nele efectuas e por um antecedente
constituído por um conjunto de Adiamentos, seguidos do símbolo |, seguido pelos Golos
ainda a serem examinados. A avaliação começa com a criação da árvore inicial da query
com raiz p(C) ← |p(C) no nó 1. Filhos de nós raiz são criados através da operação Resolu-
ção de Clausulas do Programa tal com na resolução SLD do Prolog. Assim, a avaliação usa a
33](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-39-320.jpg)



![4. SLG(O) 4.2. Oráculo
Considere-se uma base de conhecimento híbrida MKNF K contendo a ontologia O =
{C F E}, {C(a)} . Assuma-se que IF é vazia, e que existe pelo menos uma regra cujo
consequente unifica com F(a). Considere-se a query a E(a). Assim, compTO(∅, E(a), {F(a)})
verifica-se porque O ∪ {F(a)} |= E(a). Portanto, derivar F(a) das regras seria suficiente
para concluir que E(a) é verdadeiro em todos os modelos MKNF bem fundados.
Os oráculos completos são usados para definir a operação Resolução com Oráculo ,
que não tem correspondência no SLG. Seja Kd = (O, Od, Pd) uma base de conhecimento
híbrida MKNF duplicada. Dada uma floresta Fn de uma avaliação SLG(O) de Kd, Fn+1
pode ser produzido do seguinte modo.
Definição 8. Contenha Fn uma árvore com nó raiz N = S ← |S, e suponha-se que se tem
compTO(IFn
, S, G). Assuma-se que N não contém nenhum filho N = S ← |G em Fn.
Então adicione-se N como filho de N.
O conjunto O ∪ I+
F ∪ L (e, de modo semelhante, Od ∪ I+
F ∪ L) pode ser inconsistente
mesmo que o modelo MKNF bem fundado de K exista. Consequentemente, um tal orá-
culo completo potencialmente permite obter grande número de derivações inúteis para
derivar S se K é MKNF-consistente. Veja-se o seguinte exemplo [1].
Exemplo 9. Considere-se a base de conhecimento híbrida MKNF contendo a ontologia
O = {C ¬D, E F}, {C(a)} . Assuma-se que IF é vazio e considere-se a query
E(a). Se O fosse estendida com D(a), O ficaria inconsistente, e assim, todos as afirmações
seriam deriváveis de O, inclusivamente E(a). Ou seja, tem-se compTO(∅, E(a), {D(a)})
por O ∪ {D(a)} ser inconsistente. Contudo, como K é MKNF-consistente, D(a) não pode
ser derivada, pelo que a árvore correspondente acaba por falhar em qualquer avaliação
SLG(O) .
A complexidade de todo o procedimento SLG(O) depende da complexidade do orá-
culo e do número de resultados devolvidos por cada chamada ao oráculo. Mesmo que
computação de um resultado do oráculo, i.e. a chamada ao mecanismo exterior de raci-
ocínio DL, seja tratável, a complexidade (de dados) do SLG(O) pode ainda ser exponen-
cial, se a quantidade soluções geradas pelo oráculo for exponencial (e.g. se se retornam
todos os superconjuntos de uma solução). Tal sucede porque a definição de oráculo,
anteriormente apresentada, é demasiado geral. Para se obterem resultados de complexi-
dade mais interessantes, algumas assunções tem de ser feitas relativamente ao oráculo.
Define-se, de acordo com isso, o oráculo parcial correcto.
Definição 10. Seja Kd = (O, Od, Pd) uma base de conhecimento hibrida MKNF dupli-
cada, S um subgolo, e L um conjunto de átomos instanciados tal que cada L ∈ L é unifi-
cável com pelo menos um consequente de regra em Pd (designados átomos do programa).
Um oráculo parcial para O, denotado por pTO, é a relação pTO(IF , S, L) tal que se
pTO(IF , S, L)
37](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-43-320.jpg)

![5
NoHR
Embora já tenham sido formalizadas várias outras abordagens às bases de conhecimento
híbridas além do MKNF híbrido, poucas delas foram implementadas. Entre as menciona-
das na introdução, apenas para programas dl, programas HEX e regras híbridas sob semântica
bem fundada se conhecem implementações: NLP-DL 1 e DReW [43], dlhex 2, e HD-rules 3,
respectivamente.
O NLP-DL implementa os programas dl sob a semântica dos modelos estáveis e bem
fundados. A ideia essencial dos programas dl é incluir queries à ontologia nas regras,
sendo o fluxo de informação entre os dois componentes, ontologia e programa, bidirec-
cional – pode fornecer-se dados de entrada às queries e as respostas às queries afectam o
que pode ser inferido nas regras. A implementação integra os raciocinadores DLV [33] e
RACER [22] – a utilização do RACER, torna-a compatível com o OWL, e permite raciocí-
nio sobre os construtores da DL SHIQ.
O DReW reescreve um programa dl sobre uma ontologia expressável em Datalog 4 num
programa Datalog com negação e chama um raciocinador baseado em regras, o DLV, para
efectuar o raciocínio. Deste modo mitiga-se o custo adicional de se recorrer a um racioci-
nador DL externo. Nesse aspecto, é similar ao NoHR, que também reescreve a ontologia
em regras e recorre ao um raciocinador de regras para as avaliar. Note-se contudo que a
abordagem dos programas dl está entre as que mantém os dois componentes da KB sepa-
rados tanto sintática como semanticamente, i.e. são expressos em termos de vocabulários
1
http://www.kr.tuwien.ac.at/research/systems/semweblp/
2
http://www.kr.tuwien.ac.at/research/systems/dlvhex/
3
http://www.ida.liu.se/hswrl/
4
Tal é o caso do EL+
⊥e DL-LiteR .
39](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-45-320.jpg)
![5. NOHR
disjuntos e é-lhes atribuída semânticas distintas, o que impede que os critérios da estrei-
teza e flexibilidade sejam satisfeitos, contrariamente ao que acontece com o MKNF híbrido,
em que o NoHR se baseia. Presentemente, o DReW suporta o OWL 2 RL, e o OWL 2 QL,
e implementa apenas a semântica bem fundada.
Os programs HEX são uma extensão dos programas em lógica não monótonos sob
semântica dos modelos estáveis com o suporte para átomos externos de ordem superior.
Os átomos externos são uma forma genérica de built-in que permite não só aceder a
raciocinadores DL, como a módulos de software externos genéricos. O dlvhex é uma
implementação de um grande fragmento dos programas HEX. A implementação inclui
diversos plug-in para a avaliação dos átomos externos. O plug-in que diz respeito às DL
utiliza o raciocinador DL RACER, é compatível com o OWL e suporta a DL SHOIN(D).
O HD-rules implementa as regras híbridas sob semântica bem fundada. Nesta abordagem
as variáveis e constantes das regras podem ser restringidas a determinados conceitos da
ontologia. Um modelo bem fundado do programa, respeitando as restrições, é depois
computado para cada modelo da ontologia. A implementação usa XSB e o raciocinador
DL Pellet 5.
As vantagens das bases de conhecimento híbridas MKNF face às outras abordagens,
nomeadamente às que são subjacentes ao sistemas mencionados, foram já discutidas,
pelo que se dispensa uma análise mais profunda dos sistemas referidos e se opta por
estudar mais aprofundadamente apenas o sistema NoHR [28].
O NoHR é um plug-in do Protégé que permite adicionar um conjunto de regras (tal
como se conhecem na programação em lógica) não monótonas a uma ontologia EL+
⊥, e in-
terrogar a base de conhecimento combinada. O formalismo subjacente é a semântica bem
fundada para as bases de conhecimento híbridas MKNF. Portanto, nenhuma restrição
além do segurança-DL é imposta nas regras que podem ser escritas. A ferramenta baseia-
se no procedimento SLG(O) e, com o auxilio do raciocinador OWL 2 EL ELK, traduz a
ontologia para regras, e submete o resultado, juntamente com as regras não monótonas,
ao sistema de querying top-down XSB. Com o plug-in resultante, mesmo queries a onto-
logias de grande dimensão, como as SNOMED CT, aumentadas com grande quantidade
de regras, podem ser processadas com num tempo de resposta interactivo, após o breve
período de pré-processamento inicial. Algumas funcionalidades e características adicio-
nais do NoHR são: carregamento e edição programas em lógica, e definição predicados
com aridade arbitrária; opção por uma ou várias respostas para cada query; terminação
da resposta às queries; e a robustez relativamente a inconsistências entre a ontologia e as
regras.
Dado que no SLG(O) a definição de oráculo é abstracta, para implementar esse al-
goritmo foi necessário definir-se previamente um oráculo SLG(O) para a DL suportada,
EL+
⊥. Do ponto de vista teórico, esse oráculo corresponde à tradução da ontologia para re-
gras não monótonas equivalentes quanto às respostas a queries, e a sua avaliação através
5
Embora utilize um raciocinador DL que suporta completamente o OWL-DL, a implementação é ainda
um protótipo, e não é claro quais os construtores sobre os quis raciocina correctamente.
40](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-46-320.jpg)
![5. NOHR 5.1. Redução da TBox
do próprio SLG(O) . Deste modo, eliminou-se a necessidade de recorrer raciocinadores
DL externos e reduziu-se o SLG(O) a um algoritmo já implementado, de forma compro-
vadamente efectiva – o SLG, aplicado no XSB. Como a ontologia de entrada pode conter
construtores que não podem ser expressos ou não têm significado sob a forma de regras,
ela é previamente reduzida de modo a esses construtores serem, sem perda de informa-
ção relevante, eliminados – é com esse propósito que se recorre ao serviço de classificação
do raciocinador DL ELK. Essa redução é descrita na Secção 5.1. A tradução propriamente
dita é apresentada na Secção 5.2. Por fim, na Secção 5.3, descreve-se o sistema implemen-
tado.
5.1 Redução da TBox
Para obter as regras correspondentes à ontologia o sistema efectua o seguinte preproces-
samento. Em primeiro lugar o algoritmo implementado no ELK é usado para tornar
explicito o conhecimento implícito da base de conhecimento, i.e. acrescentam-se axio-
mas e asserções que não estão incluídas na ontologia, mas que podem, de alguma forma,
derivar-se dela. Depois disso, removem-se alguns axiomas redundantes quanto às res-
postas a queries.
Como mencionado, a ideia base do oráculo é traduzir a ontologia para regras não
monótonas semanticamente equivalentes. Um dos aspectos a ter em conta num tal pro-
cedimento é a impossibilidade de se traduzir directamente certos axiomas. Tal é o caso
de axiomas de subsunção de conceitos que contenham existenciais ∃R.C do lado direito.
Ora, esses axiomas nunca podem, por si só, contribuir para as derivações do oráculo.
Considere-se, por exemplo, a KB híbrida dos Exemplos 2 6 e 4. Um oráculo não po-
deria derivar nenhuma asserção com base no axioma Composer ∃HasComposed e
na asserção Composer(GustavMahler). No entanto, os axiomas ∃HasArtist−
Artist,
HasComposed−
HasArtist e Composer ∃HasComposed em conjunto, já permitem,
indirectamente, concluir que com Composer(GustavMahler) se pode derivar Artist(Gus
tavMahler). Assim, a classificação é aplicada, antes da tradução propriamente dita, para
tornar explicita tais ligações implícitas, e com isso, todas as subsunções de conceitos com
∃R.C poderem ser reescritas ou removidas.
O procedimento para a classificação de TBox EL+
⊥ é descrito em [29]. Primeiro, um
conjunto inicial input é definido de modo a conter uma anotação init(A) para cada con-
ceito atómico A em O. Depois, um conjunto de regras de inferência EL+
⊥ é aplicado exaus-
tivamente a input, originando Closure como resultado final, o qual contém os axiomas
deriváveis de O e anotações da forma init(C) e C →R D, onde a última representa o
facto de, para dois conceitos (inicializados) C e D, C ∃R.D ser também derivável.
As regras de inferência EL+
⊥ são definidas apenas para os axiomas da TBox. Contudo,
6
Note-se que a ontologia desse exemplo não está em EL+
⊥. No entanto, serve os propósitos da presente
exposição.
41](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-47-320.jpg)
![5. NOHR 5.2. Tradução
as asserções de conceitos também tem de ser consideradas. Por exemplo, ∃R.C(a) jun-
tamente com ∃R.C D, torna D(a) derivável. A solução adoptada, adaptada de [29],
foi aplicar uma transformação N que reescreve asserções de conceitos C(a) na forma de
axiomas de subsunção de conceitos Na C, assumindo um conjunto fixo de conceitos
atómicos Na, que não ocorrem em O, para cada constante a de O. Note-se que esta trans-
formação não se aplica a asserções de relação, uma vez que não ocorrem nelas conceitos
da forma ∃R.C. Tem-se finalmente que, para uma dada ontologia consistente O e um
certo axioma α não contendo nenhum conceito atómico da forma Na, O |= α se e só se
N(O) |= N(α).
A ontologia reduzida é definida do seguinte modo.
Definição 11. Seja O uma ontologia EL+
⊥, input um conjunto expressões init(A) para
cada conceito atómico A de O, e Closure o fecho de input relativamente a N(O) conforme
as regras de inferência EL+
⊥. A ontologia reduzida de O é obtida de O = N(O) ∪ Closure
do seguinte modo.
1. removem-se todas as anotações da forma init(C), C →R D, e os axiomas da forma
C ∃R.D de O ;
2. removem-se todos os subconceitos da forma ∃R.D do lado direito de qualquer axi-
oma C D1 D2 ∈ O ; se nenhum conjuntor restar, remove-se completamente o
axioma;
3. substituem-se todos os axiomas de subsunção de conceito da forma Na C que
restarem por C(a), para cada constante a de O.
Note-se que input contém uma anotação init(Na) para cada constante a. Além disso,
os passos 1. e 2. removem todos os subconceitos da forma ∃R.D dos axiomas que repre-
sentam asserções de conceitos, resultantes da transformação N. Portanto, a ontologia
reduzida não contém existenciais, nem em asserções nem no lado direito de axiomas.
Mostra-se em [28] que a ontologia reduzida de O deriva as mesmas asserções atómicas
que O.
Lema 12. Seja O uma ontologia EL+
⊥, O a ontologia reduzida O, A um conceito atómico e P uma
relação atómica. Então O |= A(a) se e só se O |= A(a) e O |= P(a, b) se e só se O |= P(a, b).
Com esse resultado, é mostrado que O pode ser substituída pela ontologia reduzida
e ainda se obtém um oráculo parcial correcto.
5.2 Tradução
Após a redução da ontologia pode proceder-se à sua tradução para regras. As únicas
questões ainda em aberto são a coerência e a detecção de inconsistências MKNF. Recorde-
se que a coerência assegura que quando se infere uma negação clássica também se infere
42](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-48-320.jpg)

![5. NOHR 5.2. Tradução
(a1) para cada A(a) ∈ O:
A(a) ←
Ad(a) ← not NA(a)
(a2) para cada R(a, b) ∈ O:
R(a, b) ←
Rd(a, b) ← not NR(a, b)
(t1) para cada A ∈ O:
A(x) ←
Ad(x) ← not NA(x).
(c1) para cada C A ∈ O:
A(x) ← tr(C, x)
Ad(x) ← tr(C, x)d, not NA(a)
(c2) para cada R S ∈ O:
S(x, y) ← R(x, y)
Sd(x, y) ← Rd(x, y), not NS(x, y)
(r1) para cada R1 ◦ · · · ◦ Rk S ∈ O:
S(x1, y) ← R1(x1, x2), · · · , Rk(xk, y)
Sd(x1, y) ← Rd
1(x1, x2), · · · , Rk
d(xk, y), not NS(x1, y)
(i1) para cada A ⊥ ∈ O:
NA(x) ←
(i2) para cada D ⊥ ∈ O:
{NA(y) ← tr(D, x) {A(y)} | A(y) ∈ tr(D, x)} ∪
{NR(y, z) ← tr(D, x) {R(y, z)} | R(y, z) ∈ tr(D, x)}
Criam-se em Pd
O as regras que representam O e Od. Novamente, se ⊥ não ocorre nelas
podem dispensar-se todas as regras com predicados duplicados e (i1) e (i2) em nada con-
tribuem. Os literais not NA(x) e not NS(x, y) são adicionados às regras duplicadas de
acordo com a ideia de duplicação expressa na definição de base de conhecimento híbrida
MKNF duplicada, apresentada na secção 4.2: assegura-se que sempre que dado átomo
A(a) é classicamente falso se pode derivar, das regras resultantes da tradução, que Ad(a)
é falso, mas não necessariamente que A(a) é falso, o que permite detectar inconsistências
MKNF. Essa é também a razão pela qual (i1) e (i2) não produzem regras duplicadas: áto-
mos baseados em predicados da forma NCd ou NRd nunca são utilizados.
É também demonstrado em [28] que os programas resultantes da aplicação da tra-
dução apresentada derivam as mesmas asserções atómicas que as KB duplicadas que os
originam.
44](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-50-320.jpg)
![5. NOHR 5.3. Implementação
Lema 15. Seja O uma ontologia reduzida EL+
⊥, A um conceito atómico e P uma relação atómica.
O |= A(a) se e só se Pd
O |= A(a) e Od |= Ad(a) se e só se Pd
O |= Ad(a); e, de modo semelhante,
O |= P(a, b) se e só se Pd
O |= P(a, b) e Od |= Pd(a, b) se e só se Pd
O |= Pd(a, b).
Assim, pode definir-se um oráculo parcial correcto baseado em Pd
O, do seguinte modo.
Definição 16. Seja Kd = (O, Od, Pd) uma base de conhecimento MKNF duplicada, onde
O é uma ontologia EL+
⊥. Seja O a ontologia reduzida de O. Define-se o oráculo EL+
⊥de
O, denotado por pTEL
O , como o oráculo parcial tal que pTEL
O (I, S, L) se só se Pd
O ∪ I ∪
L |=WF S, onde I e L são os conjuntos das regras correspondentes aos literais de I e L,
respectivamente.
Com o último resultado, sabe-se que em vez de usar dois raciocinadores, um para a
ontologia e outro para as regras, pode simplificar-se todo o processo integrando ambas as
fases, a resolução propriamente dita e a computação do oráculo, num único raciocinador
de regras. É também demostrado que tal abordagem é decidível com complexidade de
dados polinomial.
5.3 Implementação
Figura 5.1: Arquitectura do sistema NoHR [28]
Os dados de entrada do plug-in consistem num ficheiro OWL, que pode ser manipulado,
como habitualmente, no Protégé, e um ficheiro de regras. Para o último, é fornecido um
separador etiquetado “NoHR Rules” que permite carregar, guardar e editar ficheiros de
regras num painel de texto. A sintaxe segue as convenções do Prolog, pelo que a primeira
regra do Exemplo 4, por exemplo, pode ser escrita do seguinte modo
Recomend(X) :- Piece(X), not owns(X), not LowEval(X), interesting(X).
Um separador “NoHR Query” (ver a figura 9.3 do Capítulo 9) também permite visu-
alizar as regras, mas o seu principal propósito é lançar as queries à base de conhecimento
(constituída pela ontologia e as regras carregadas). Sempre que uma primeira query é
45](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-51-320.jpg)

![6
Raciocínio em DL-LiteR
Em [9] estudam-se algumas técnicas de raciocínio DL para DL-LiteR . Nomeadamente
investiga-se a satisfazibilidade de ontologias DL-LiteR e as suas consequências lógicas
(ver Secção 6.3). Mostra-se que é possível reduzir a verificação de subsunção – i.e. que um
dado axioma de subsunção é consequência lógica da ontologia – e verificação de pertença
– i.e. que uma dada asserção de pertença é consequência lógica da ontologia – à satis-
fazibilidade. Mostra-se também que é possível verificar a satisfazibilidade de uma dada
ontologia, com TBox positiva, através de uma interpretação canónica (ver Secção 6.1) dela.
Quando a sua TBox tem axiomas negativos, recorre-se à interpretação correspondente ao
modelo minimal da ABox (ver definição 23) e a um fecho negativo da TBox (secção 6.2).
No contexto desta dissertação, dado o seu desenvolvimento teórico, esses resultados são
particularmente relevantes, e amplamente aplicados.
6.1 Interpretação canónica
Começa-se por introduzir a noção de interpretação canónica de uma ontologia, i.e. de uma
interpretação que é representante de qualquer possível modelo dela, no sentido em que
qualquer modelo tem de definir extensões (de conceitos e relações) que contenham as
extensões definidas nessa interpretação. Tal interpretação é particularmente importante,
porque permite determinar se uma ontologia é satisfazível.
Para simplificar a exposição é adoptada a seguinte função, que mapeia uma relação
47](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-53-320.jpg)


![6. RACIOCÍNIO EM DL-LiteR 6.1. Interpretação canónica
existe j ≥ i tal que chasej+1(O) = chasej(O) ∪ f , onde f resulta da aplicação de α a f em
chasej(O).
Com base no operador chase define-se finalmente a interpretação canónica.
Definição 20. Seja O = T , A uma ontologia DL-LiteR . Define-se a interpretação canónica
de O denotada por can(O), como a estrutura de interpretação ∆can(O), .can(O) , onde
1. ∆can(O) = ΓC;
2. acan(O) = a, para cada constante a ocorrendo em chase(O);
3. Acan(O) = {a | A(a) ∈ chase(O)}, para cada conceito atómico A; e
4. Pcan(O) = {(a1, a2) | P(a1, a2) ∈ chase(O)}, para cada relação atómica P.
Em [9] demonstra-se que o a interpretação canónica é sempre modelo da parte posi-
tiva da TBox de uma dada ontologia e sua ABox.
Lema 21. Seja O = T , A uma ontologia DL-LiteR , Tp o conjunto de subsunções positivas em
T . Então, can(O) é um modelo de Tp, A .
Exemplo 22. Considere-se ontologia do exemplo 2. Computa-se chase(O), do seguinte
modo.
Inicialmente tem-se S0 = {Composer(GustavMahler), HasArtist(BlueTrain, John
Coltrane), HasComposed(GeorgeGershwin, RapsodyInBlue), TopSeller(BlueTrain)}. A
primeira asserção, assumindo a ordenação lexicográfica seguida neste exemplo – recorde-
se que na construção de chase(O) se selecionam as asserções e os axiomas pela sua or-
dem lexicográfica – para qual existe um axioma aplicável é Composer(GustavMahler),
à qual pode ser aplicado Composer ∃HasComposed. Por (cr2) obtém-se S1 = S0 ∪
{HasComposed(GustavMahler, a1)}. Depois, o axioma ∃HasArtist−
Artist é apli-
cado a HasArtist(BlueTrain, JohnColtrane) e tem-se, por (cr3), S2 = S1 ∪{Artist(John
Coltrane). Seguidamente, por (cr5), aplica-se HasComposed HasArtist−
a HasCompo
sed(GeorgeGershwin, RhapsodyInBlue), obtendo-se S3 = S2 ∪ {HasArtist(Rhapsody
InBlue, GeorgeGershwin). A essa última asserção é aplicado o axioma ∃HasArtist−
Artist, que, por (cr2), dá origem a S4 = S3 ∪ {Artist(GeorgeGershwin)}. De modo simi-
lar, aplica-se HasComposed Artist−
a HasComposed(GustavMahler, a1), obtendo-se
S5 = S4 ∪ {HasArtist(a1, GustavMahler); e ∃HasArtist−
Artist à asserção adicio-
nada, originando-se S6 = S5 ∪ {Artist(GustavMahler)}. Depois, aplica-se ∃HasCompo
sed−
Piece a HasComposed(GeorgeGershwin, RhapsodyInBlue), por (cr2), obtendo-
se S7 = S6 ∪ {Piece(RhapsodyInBlue)}; e, de modo semelhante, aplica-se esse axi-
oma a HasComposed(GustavMahler, a1), obtendo-se S8 = S7 ∪ {Piece(a1)}. Final-
mente, aplica-se TopSeller Recommend a TopSeller(BlueTrain), obtendo-se S9 =
S8 ∪ {Recommend(BlueTrain)}. Tem-se então chase(O) = {Composer(GustavMahler),
HasArtist(BlueTrain, JonhColtrane), HasComposed(GeorgeGershwin, RapsodyInBl
50](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-56-320.jpg)



![6. RACIOCÍNIO EM DL-LiteR 6.3. Satisfazibilidade
algum axioma negativo não for satisfeito pelo resultado da computação descrita, tal sig-
nifica que não é possível construir nenhuma interpretação que satisfaça a ontologia, ou
seja, que ela não admite nenhum modelo.
Outro resultado relevante de [9] é que os serviços relacionados com a consequência
lógica, instanciação e subsunção, em ontologias DL-LiteR podem ser reduzidos à satisfa-
zibilidade.
Relativamente à instanciação para expressões de conceito é apresentado o seguinte
resultado.
Teorema 29. Seja O uma ontologia DL-LiteR , C um conceito, d uma constante que ocorre em
O, e ˆA um conceito atómico que não ocorre em O. Então O |= C(d) se e só se a ontologia
O = T ∪ { ˆA ¬C}, A ∪ { ˆA(d)}
é insatisfazível.
De modo semelhante, é apresentado o seguinte resultado para expressões de relações.
Teorema 30. Seja O uma ontologia DL-LiteR , R uma relação, a e b das constantes ocorrendo
em O, e ˆP uma relação atómica que não ocorre em O. Então O |= R(a, b) se e só se a ontologia
O = T ∪ { ˆP ¬R}, A ∪ { ˆP(a, b)}
é insatisfazível.
Com efeito, raciocinado por contradição, se se tem que ao acrescentar a negação de
uma certa asserção à ontologia 2 ela deixa de ser satisfazível, tal significa que não existe
nenhum modelo no qual essa asserção seja falsa, ou seja, ela é forçosamente verdadeira
em todos os modelos. Por outro lado, se a ontologia já era insatisfazível antes da adição
da negação da asserção, então todos as asserções já eram dela deriváveis, e, em particular,
a asserção considerada.
Relativamente à subsunção de conceitos tem-se o resultado seguinte.
Teorema 31. Seja T uma TBox DL-LiteR , C1 e C2 dois conceitos, ˆA um conceito atómico que
não ocorre em T , e d uma constante. Então T |= C1 C2 se e só se a ontologia
O = T ∪ { ˆA C1, ˆA ¬C2}, { ˆA(d)}
é insatisfazível.
O último resultado endereça subsunção de relações.
2
Note-se que o conceito ˆA (resp., relação ˆP) são utilizados porque, em DL-LiteR , não é possível adicionar
a negação de outro modo. Recorde-se que só se permitem asserções atómicas na ABox.
54](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-60-320.jpg)















![7. TRADUÇÃO COM REDUÇÃO 7.2. Análise
só se Pd
O |= Ad(a), e, de modo semelhante, O |= P(a, b) se e só se Pd
O |= P(a, b) e Od |= Pd(a, b)
se e só se Pd
O |= Pd(a, b).
Demonstração. Considere-se o caso dos predicados originais. Apenas as asserções de per-
tença formadas pelos predicados originais, i.e. asserções da forma A(a) ou P(a, b), e axi-
omas de subsunção positivos (que não sejam da forma B ∃Q – note-se que a ontologia
está reduzida relativamente aos existenciais) de O podem contribuir para a derivação
das asserções consideradas, que na definição 64 são tratados nos casos (a1), (a2), (c1)
e (r1), e cujas regras resultantes, para os predicados originais, são as únicas que podem
contribuir para a derivação (em regras) de tais asserções. Sabe-se que as regras mencio-
nadas, nos casos (a1), (a2) e (c1), são traduções logicamente equivalentes [20]. No caso
(r1) é fácil constatar que o mesmo se verifica. Veja-se. P1 P2 corresponde, de facto, a
P2(x, y) ← P1(x, y); P1 P2
−
a P2(y, x) ← P1(x, y); P1
−
P2 a P2(x, y) ← P1(y, x); e
P1
−
P2
−
a P2(y, x) ← P1(y, x). Assim, conclui-se que O |= A(a) se e só se Pd
O |= A(a) e
O |= P(a, b) se e só se Pd
O |= P(a, b).
Considere-se agora as asserções com predicados especiais, i.e. da forma NH(ti), onde
H é um conceito atómico ou uma relação atómica, e que representam uma query a ¬H(ti).
Pretende-se demonstrar que O |= ¬H(ti) se e só se Pd
O |= NH(ti). Apenas as asserções de
pertença formadas pelos predicados originais, e axiomas de subsunção de O podem con-
tribuir para a derivação de tais asserções. Como já se demonstrou que as traduções das
asserções com predicados originais e dos axiomas de subsunção positivos de O derivam
exactamente as mesmas asserções que a ontologia original O, basta mostrar então que o
mesmo é verdade para as negações clássicas derivadas através dos axiomas de subsun-
ção negativos de O, que correspondem aos casos (i1) e (i2) cujas as regras resultantes são
as únicas que podem contribuir para a derivação (em regras) de tais asserções. É fácil
constatar que tais regras são de facto logicamente equivalentes aos axiomas descritos.
Veja-se. No caso (i1), NA2(x) ← A1(x) e NA1(x) ← A2(x) correspondem, de facto, a
A1 ¬A2; NA2(x) ← P(x, z) e NP(x, z) ← A2(x) a ∃P ¬A; e NA2(x) ← P(z, x)
e P(z, x) ← A2(x) a ∃P− ¬A – representando os literal ¬A(x) pelos átomos NA(x).
O outro axioma capturado em (i1), B ¬∃Q, corresponde à fórmula de primeira ordem
∀x(tr(B, x) ⊃ ¬∃y(tr(Q, x, y))), que é equivalente a ∀x, y(tr(B, x) ⊃ ¬tr(Q, x, y)), ou às
regras, tr(¬Q, x, y) ← tr(B, x) e tr(¬B) ← tr(Q, x, y). No caso (i2), NP2(x, y) ← P1(x, y)
e NP1(x, y) ← P2(x, y) corresponde, de facto, a P1 ¬P2; NP2(y, x) ← P1(x, y) e
NP1(x, y) ← P2(y, x) a P1 ¬P2
−
; NP2(x, y) ← P1(y, x) e NP1(y, x) ← P2(x, y) a
P1
−
¬P2; e NP2(y, x) ← P1(y, x) e NP1(y, x) ← P2(y, x) a P1
−
¬P2
−
. Assim,
conclui-se que O |= NH(ti) se e só se Pd
O |= NH(ti).
Considere-se agora as asserções com predicados duplicados, i.e, da forma Ad(a) ou
Pd(a, b). O argumento é semelhante ao usado para os as asserções com os predicados ori-
ginais, mas agora aplicada aos predicados duplicados. Tem de considerar-se adicional-
mente apenas os literais negativos auxiliares not NA(x) e not tr(Q, x, y), acrescentados
ao corpo das regras, para os predicados duplicados, nos casos (a1), (a2), (c1) e (r1), com o
70](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-76-320.jpg)



![7. TRADUÇÃO COM REDUÇÃO 7.2. Análise
{A(a)} ; e que can(O ) não satisfaz O se e só se db(A ∪{A(a)}) |= cln(T ), A ∪{A(a)} .
Portanto, para demostrar a propriedade pretendida basta mostrar que db(A ∪ {A(a)}) |=
cln(T ), A ∪ {A(A)} se e só se db(A ∪ {A(a)}) |= cln(T ), A ∪ {A(a)} .
Considerem-se as TBox negativas T1 = cln(T ) e T2 = cln(T ), e um axioma negativo
arbitrário α. Pelo corolário 27 tem-se que T1 |= α se e só se T |= α; e que T2 |= α se e só se
T |= α. Ora, dado que T é a TBox de uma redução de O = T , A , sabe-se que T |= α
se e só se T |= α. Portanto, tem-se T1 |= α se e só se T2 |= α. Mostra-se que de facto se
tem db(A ) |= T1, A se e só se se db(A ) |= T2, A , onde A corresponde a A ∪{A(a)}
e A ∪ {A(a)} – recorde-se que, sendo A a ABox de uma redução de O = T , A , tem-se
A = A.
(→) Sabe-se que db(A ) |= T1, A se e só se existe um axioma negativo β ∈ T1 tal
que db(A ) |= β.
Considere-se β = B1 ¬B2. Nesse caso, T1 |= B1 ¬B2. Portanto, tem-se T2 |= B1
¬B2. É fácil constatar que, para tal se verificar, tem de existir em T2 um axioma negativo,
χ, B1 ¬B2, B2 ¬B1, B1 ¬B1, ou B2 ¬B2. Ora, dado que db(A ) |= B1 ¬B2,
tem-se que existe a tal que db(A ) |= B1(a) e db(A ) |= B2(a). Com isso, conclui-se que
db(A ) |= χ. Ou seja, db(A ) também não satisfaz T2, A .
Considere-se β = B ¬B. Nesse caso, T1 |= B1 ¬B2. Portanto, tem-se T2 |= B
¬B. É fácil constatar que, para tal se verificar, tem de ter-se B ¬B ∈ T2. Portanto,
db(A ) também não satisfaz T2, A .
Considere-se β = Q1 ¬Q2. Por raciocínio similar apresentado no caso β = B1
¬B2, conclui-se que db(A ) não satisfaz T2, A .
Considere-se β = Q ¬Q. Por raciocínio similar ao apresentado no caso β = B
¬B, conclui-se que db(A ) não satisfaz T2, A .
(←) Similar a (→), no sentido inverso, i.e. de T2 para T1.
Lema 54. Seja O uma ontologia DL-LiteR . Seja O uma redução de O. Seja P uma relação
atómica e a e b duas constantes. Então O |= ¬P(a, b) se e só se O |= ¬P(a, b).
Demonstração. Similar ao lema 53.
Em [28] é apresentada a noção de oráculo parcial abstracto, que corresponde a um
oráculo parcial que é necessariamente correcto.
Definição 55. Seja Kd = (O, Od, Pd) uma base de conhecimento MKNF duplicada, onde
O é uma ontologia DL-LiteR . Define-se oráculo parcial abstracto para O, denotado por
pTa
O, como o oráculo parcial tal que pTOa(I, S, L) se só se O ∪ I ∪ L |= S ou Od ∪ I ∪ L
para O ∪ I ∪ L e Od ∪ I ∪ L consistentes, respectivamente.
É também enunciada em [28] a seguinte preposição.
Preposição 56. Seja Kd = (O, Od, Pd) uma base de conhecimento híbrida MKNF. O oráculo
parcial abstracto pTa
O é correcto relativamente a compTO.
74](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-80-320.jpg)

![8
Tradução directa
O oráculo DL-LiteR directo baseia-se numa tradução da ontologia para regras não mo-
nótonas, à semelhança do que acontece com os oráculos EL+
⊥e DL-LiteR indirecto, ante-
riormente apresentados. No entanto, contrariamente a estes, não recorre a qualquer tipo
de redução da TBox. Neste oráculo, ao invés de se evitar a ocorrência de axiomas cuja
tradução para regras não é óbvia, introduzem-se alguns predicados especiais para per-
mitir essa tradução. As quantificações existenciais no lado direito de axiomas, que, com
já se viu, não podem ser representados recorrendo exclusivamente aos operadores da
programação em lógica e aos símbolos da assinatura da ontologia, são aqui representa-
das usando esses predicados especiais.
Outra diferença importante entre o oráculo DL-LiteR directo e os oráculos anteri-
ormente apresentados é que, contrariamente ao primeiro, os últimos pressupõem inde-
pendência entre os conjuntos de axiomas positivos e negativos (no caso do EL+
⊥, a não
existência dos segundos) da TBox à qual é aplicada a tradução, i.e. da TBox reduzida,
no sentido em que, a junção de ambos não deriva mais axiomas que cada um separa-
damente. Recorde-se que um dos passos da redução no oráculo DL-LiteR indirecto é
a aplicação do fecho dos axiomas negativos relativamente aos positivos, que adiciona
precisamente os axiomas negativos que resultam da interacção entre axiomas positivos
e negativos. Ora, no oráculo directo, uma vez que não há redução, essa interacção, nem
sempre trivial, tem de ser tida em conta na própria tradução. Para estudar o efeito dessa
interação entre axiomas positivos e negativos sobre a derivação de asserções, recorre-se a
uma estrutura bem conhecida: o grafo 1. Tal abordagem é igualmente adoptada em [32],
1
Embora [9] (ver capítulo 6) defina o fecho dos axiomas negativos relativamente aos positivos, cln, e apre-
sente algumas das suas propriedades, não fornece outras ferramentas que permitam estudar as propriedades
pretendidas. Revelou-se mais producente optar por introduzir a noção de grafo de TBox mencionada.
76](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-82-320.jpg)




























![8. TRADUÇÃO DIRECTA 8.3. Algoritmos
relações insatisfazíveis, na presença de um axioma B1 ¬B2 (resp., Q1 ¬Q2), basta
intersectar o conjunto dos conceitos (resp., relações) antecessoras de B1 (resp., Q1) com
o conjunto dos antecessores de B2 (resp., Q2). No caso dos conceitos e relações insatis-
fazíveis, perante um axioma, B1 ¬B2 (resp., Q1 ¬Q2), basta filtrar no conjunto das
relações básicas que ocorrem nos antecessores de B1 (resp., Q1) as que tem o seu inverso
a ocorrer em antecessores de B2 (resp., Q2).
Os algoritmos 1 e 2, permitem obter os conjuntos de conceitos e relações definidos pe-
los operadores Ω e Ψ, respectivamente, de acordo com o método descrito. A função Atom
devolve o símbolo de conceito ou relação com o qual é formado o conceito básico ou rela-
ção básica de entrada. A função ANCS, que se baseia no algoritmo Closure, apresentado
em [27], permite obter o conjunto de antecessores, no grafo da TBox formada pelos axio-
mas positivos, de um dado conceito básico (resp., uma dada relação básica). As funções
CInvInter e RInvInter cruzam dois conjuntos de antecessores dos conceitos básicos (resp.,
relações básicas) envolvidos num axioma negativo, da forma descrita anteriormente.
105](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-111-320.jpg)





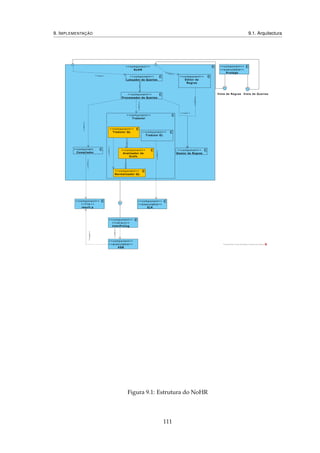

![9. IMPLEMENTAÇÃO 9.2. Funcionamento
Verificar
Perfil
Normalizar
Ontologia
Inicializar
ELK
Inicializar
Grafo
Processar
Regras
Compilar
Regras
Inicializar
XSB
Carregar
Regras
Gerar
Golo
Lançar
Golo
Apresentar
Resultados
Classificar
Ontologia
Verificar
Perfil
Inicializ
ar ELK
Classificar
Ontologia
Traduzir
Ontologia
Gerar
Subgolo
Laçar
Subgolo
Traduzir
Ontologia
Perfil
Perfil
Disjunção Introduzida
Regras Alteradas
Ontologia Alterada
KB Alterada
Nova Query
Respostas Esgotadas
Primeira Query
Existem Disjunções
Próxima Resposta
Verdadeira ou Indefinida
[sim]
[não]
[não]
[sim]
[não]
[sim]
[não]
[sim]
[sim]
[não]
[não]
[sim]
[não]
[sim]
[QL]
[EL]
[não]
[sim]
[QL]
[EL]
[sim]
Powered ByVisual Paradigm Community Edition
Figura 9.2: Funcionamento do NoHR
113](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-119-320.jpg)
![10
Avaliação
Para avaliar a implementação da extensão do NoHR, descrita no capitulo anterior, recorreu-
se a um benchmark bem conhecido na literatura, o LUBM [21]. O seu proposito é permitir
avaliar repositórios da Web Semântica de forma padronizada e sistemática. É destinado a
avaliar o desempenho desses repositórios relativamente a queries sobre conjuntos de da-
dos de grande dimensão, constituídos por uma única e realista ontologia. O benchmark
consiste nessa ontologia, cujo domínio é o das universidades; num conjunto de dados
configuráveis, sintéticos e repetíveis; num conjunto de queries; e em várias métricas de
desempenho.
O LUBM não enfatiza tanto o tratamento da TBox – a sua dimensão é moderada com-
parativamente a outros benchamarks – como o da ABox, ao permitir gerá-la com dimen-
sões arbitrariamente grandes. Tal adequa-se particularmente ao perfil OWL 2 QL, que é,
como já foi mencionado, especialmente adaptado a domínios onde o número de instân-
cias é preponderante sobre a dimensão da terminologia.
O capítulo prossegue do seguinte modo. Na Secção 10.1 descreve-se a experiência
efectuada. Na Secção 10.2 apresentam-se os resultados obtidos. Na última secção, a
Secção 10.3, discutem-se esses resultados.
10.1 Experiência
No LUBM, a universidade é a unidade mínima de geração, que envolve a descrição de
um conjunto de departamentos; e as instâncias das classes e propriedades são decididas
aleatoriamente. Para esses dados serem tão realistas quanto possível, aplicam-se algu-
mas restrições baseadas no senso comum e na investigação do domínio em causa. Os
dados gerados são completamente repetíveis quanto às universidades, pois é possível
115](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-121-320.jpg)


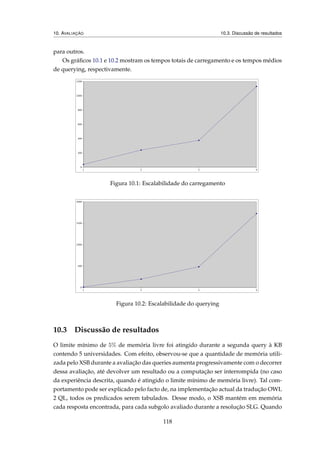
![10. AVALIAÇÃO 10.3. Discussão de resultados
o número de respostas encontradas numa dada avaliação SLG é suficientemente elevado
toda a memória disponível fica ocupada. Embora não seja possível evitar completamente
esse efeito – pelo menos alguns predicados terão de ser sempre tabulados, tornando o
uso de memória linear no número de respostas, envolvendo esses predicados, encon-
tradas na avaliação SLG – acredita-se poder-se mitigá-lo. Por um lado, supõe-se que
seja possível evitar o uso de tabulação para certos predicados. Tal possibilidade poderá
ser futuramente estudada e, se se confirmar, aplicada na prática. Por outro lado, a forma
como se geram e avaliam os golos para se obter a resposta de uma dada query, parece, à
partida, ainda ser susceptível de optimizações significativas.
Quanto ao tempo de carregamento, consideram-se satisfatórios os valores obtidos.
Considera-se que apenas alguns minutos para carregar e traduzir uma ontologia con-
tendo cerca de quatro centenas de milhar de asserções – o que só é necessário efectuar
apenas uma vez para todas as queries subsequentes – são aceitáveis. Relativamente à es-
calabilidade do sistema na fase de carregamento, os dados são pouco conclusivos – seria
necessária mais memória para se poder prosseguir a experiência com mais universida-
des. Embora os resultados obtidos possam sugerir que o sistema possa ser pouco esca-
lável perante ontologias com ABox de dimensões superiores às utilizadas na experiência
(veja-se o gráfico da figura 10.1), tal como acontece com os sistemas estudados em [21],
pode supor-se, dado que os tempos obtidos se mantiveram na ordem dos segundos, que
o sistema seria capaz de carregar (e traduzir) ontologias com ABox relativamente gran-
des, em tempos aceitáveis.
Quanto ao tempo de queries, os valores obtidos revelam a necessidade de algumas
melhorias. Não se coadunam com a eficiência pela qual o XSB é conhecido – note-se que
na fase de querying a computação é delegada, quase completamente, ao XSB. Uma das
explicações que se colocou em hipótese foi a de que o uso de predicados hilog 1 pudesse
ter um impacto negativo no desempenho do XSB. Tal hipótese foi, de facto, corroborada
por algumas experiências que se fizeram posteriormente. Assim, acredita-se que, supri-
mindo o uso dos predicados hilog, e implementando as melhorias já mencionadas, po-
derão obter-se tempos de resposta mais satisfatórios. Embora os resultados possam su-
gerir haverem algumas limitações quanto à escalabilidade do sistema, em geral, (veja-se
o gráfico da figura 10.2), como ainda existem lugar para algumas melhorias importantes,
crê-se que tal não é o caso.
Além da experiência descrita, faria sentido realizar outras em que se comparasse o
NoHR com outros raciocinadores. No entanto, existem algumas restrições importantes.
1
Predicados hilog (consultar http://xsb.sourceforge.net/manual1/manual1.pdf ) são predi-
cados de segunda ordem, i.e. podem sem formados por qualquer termo, seja ele uma constante, uma variá-
vel, ou um termo composto – f(x), por exemplo. Tais predicados permitem, por exemplo, escrever as regras
dom(P)(X) : −P(X, _). e ran(P)(X) : −P(_, X). onde P e X são variáveis, e dom e ran são functores
que denotam o domínio e contradomínio, respectivamente, de uma relação. Usando unicamente essas duas
regras é possível expressar exactamente o mesmo que o conjunto de todas as regras escritas no caso (e) da
tradução directa (64) expressa. Foi no sentido de aproveitar essa possibilidade, reduzindo assim significati-
vamente o número de regras no programa resultante da tradução, que se optou por recorrer aos predicados
hilog.
119](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-125-320.jpg)


![11
Conclusões e Trabalho Futuro
A presente dissertação lega alguns contributos relevantes à área de Representação de Co-
nhecimento. A um nível conceptual, vem fortalecer a visão de bases de conhecimento
como algo heterogéneo nas formas de representação – como são heterogéneas as formas
como o ser humano representa mentalmente a realidade – em vez de como conhecimento
expresso sob uma linguagem particular, que o limita e constrange a certa perspectiva,
juntando-se a uma linha de investigação emergente – a das bases de conhecimento hí-
bridas – com já muito trabalho realizado e várias provas de sucesso dadas. Constitui,
em certa medida, mais uma evidência da viabilidade dessa abordagem à representação
de conhecimento.
Entre os vários formalismos híbridos existentes, o MKNF híbrido é provavelmente o
que melhor revela as potencialidades de se combinar lógicas de descrição com progra-
mação em logica, na medida em que as bases de conhecimentos que suporta realmente
beneficiam, por completo, da expressividade de ambas as formas de representação, e se
mantêm, ainda assim, coesas – tal não é o caso em outros formalismos conhecidos, como
SWRL [23, 25], DLP [20], AL-log [11], CARIN [34], DL + log [41], Horn-SHIQ [26], pro-
gramas dl [13, 14], programas dl disjuntivos [16], lógica de equilíbrio quantificado para bases de
conhecimento híbridas [16], grafos de descrição [36] , esquemas nominais [31], regras híbridas sob
semântica bem fundada [12] e programas HEX [15].
O formalismo MKNF híbrido, por si só, mostra o potencial da agregação das duas
técnicas de representação numa mesma base de conhecimento. A definição de um algo-
ritmo de querying tratável – o SLG(O) – para as bases de conhecimento híbridas MKNF
com ontologias em DLs tratáveis foi um passo em frente no estabelecimento da sua apli-
cabilidade, ao mostrar que raciocinadores destinados a querying – que poderão vir a
122](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-128-320.jpg)

![11. CONCLUSÕES E TRABALHO FUTURO
os conceitos e relações que apresentam certas propriedades que devem reflectir-se nas re-
gras – a insatisfazibilidade e a irreflexividade. Tal técnica é comparável, em efectividade,
à anterior – embora se suponha que tenha, na prática, significativamente melhor desem-
penho, por não necessitar de uma classificação completa e não ser tão penalizada com a
presença de axiomas negativos. Independente de esta abordagem ser ou não superior à
anterior, constitui igualmente outro contributo importante desta dissertação, uma vez
que se mostrou analiticamente a sua correcção e empiricamente a sua viabilidade. Tal
como a tradução da abordagem anterior, também esta poderá inspirar futuras técnicas
de querying DL recorrendo a raciocinadores de regras.
A implementação da extensão do NoHR com o suporte ao OWL 2 QL, é também, por
si só, outro contributo relevante desta dissertação. O perfil QL da linguagem OWL 2 é
particularmente aplicável em contexto empresarial e na Web, uma vez que apresenta pro-
priedades computacionais que lhe conferem a escalabilidade, quanto ao volume de da-
dos, habitualmente requerida em tal contexto. Por esse motivo, de ser escalável quanto
aos dados, é essa a linguagem adoptada no Acesso a Dados Baseado em Ontologias
– técnica na qual se abstrai uma camada dos dados, constituída por diversas bases de
dados, com uma camada ontológica sobre a primeira, de modo a facilitar a integração
de informação proveniente de diversas fontes e em vários formatos distintos – que será
provavelmente padrão em muitas das aplicações do futuro. O NoHR, com a extensão
realizada nesta dissertação, é o primeiro raciocinador a suportar querying a bases de co-
nhecimento híbridas coesas beneficiando completamente, e simultaneamente, da expres-
sividade desse perfil e das regras não monótonas – que são particularmente úteis nos
contextos mencionados, já que sustentam a assunção do mundo fechado, como as bases
de dados. Recorde-se que outros raciocinadores conhecidos, como NLP-DL 2, DReW [43],
dlhex 3, e HD-rules 4, baseiam-se em formalismos que não permitem tirar o mesmo pro-
veito de ambas as formas de representação nem exibem a mesma coesividade. Embora
ainda haja lugar para algumas melhorias no NoHR, os resultados empíricos obtidos per-
mitem concluir que o sistema é viável e que poderá assim vir a servir de base a futu-
ras aplicações Web, empresariais ou governamentais (recorde-se o exemplo de aplicação
enunciado na introdução).
Para trabalho futuro, num plano mais imediato, há as várias melhorias à implemen-
tação já apontadas, e alguns estudos possíveis. A nível teórico, estudar se se pode evitar
tabular certos predicados no XSB, e em que circunstâncias, poderá revelar oportunida-
des de optimização significativas. Além disso, comparar empiricamente a performance
do NoHR usando o oráculo EL+
⊥ou DL-LiteR seria interessante tanto para enriquecer a
avaliação de ambas as técnicas, como para determinar qual delas deverá ser seleccionada
no caso de ontologias que estejam em ambas as lógicas de descrição.
Os desenvolvimentos desta dissertação deixaram, naturalmente, algumas questões
2
http://www.kr.tuwien.ac.at/research/systems/semweblp/
3
http://www.kr.tuwien.ac.at/research/systems/dlvhex/
4
http://www.ida.liu.se/hswrl/
124](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-130-320.jpg)

![Bibliografia
[1] J. J. Alferes, M. Knorr e T. Swift. “Queries to Hybrid MKNF Knowledge Bases th-
rough Oracular Tabling”. Em: The Semantic Web - ISWC 2009, 8th International Se-
mantic Web Conference, ISWC 2009, Chantilly, VA, USA, October 25-29, 2009. Procee-
dings. Ed. por A. Bernstein, D. R. Karger, T. Heath, L. Feigenbaum, D. Maynard, E.
Motta e K. Thirunarayan. Vol. 5823. Lecture Notes in Computer Science. Springer,
2009, pp. 1–16. ISBN: 978-3-642-04929-3.
[2] J. J. Alferes, M. Knorr e T. Swift. “Query-Driven Procedures for Hybrid MKNF Kno-
wledge Bases”. Em: ACM Trans. Comput. Log. 14.2 (2013), 16:1–16:43.
[3] F. Baader, S. Brandt e C. Lutz. “Pushing the EL Envelope”. Em: IJCAI-05, Proceedings
of the Nineteenth International Joint Conference on Artificial Intelligence, Edinburgh, Sco-
tland, UK, July 30-August 5, 2005. Ed. por L. P. Kaelbling e A. Saffiotti. Professional
Book Center, 2005, pp. 364–369. ISBN: 0938075934. URL: http://www.ijcai.
org/papers/0372.pdf.
[4] F. Baader, D. Calvanese, D. L. McGuinness, D. Nardi e P. F. Patel-Schneider, eds.
The Description Logic Handbook: Theory, Implementation, and Applications. Cambridge
University Press, 2003. ISBN: 0-521-78176-0.
[5] T. Berners-Lee, J. Hendler e O. Lassila. “The Semantic Web”. Em: Scientific American
(2001), pp. 96–101.
[6] H. Boley e M. Kifer, eds. RIF Overview (Second Edition). Available from http://
www.w3.org/TR/2013/NOTE-rif-overview-20130205/. W3C Recommen-
dation 05 February 2013, 2013.
[7] R. J. Brachman e H. J. Levesque. Knowledge Representation and Reasoning. Elsevier,
2004. ISBN: 978-1-55860-932-7. URL: http://www.elsevier.com/wps/find/
bookdescription.cws_home/702602/description.
[8] S. Bratt, ed. Emerging Web Technologies to Watch. Available from http://www.w3.
org/2006/Talks/1023-sb-W3CTechSemWeb/. 2006.
126](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-132-320.jpg)
![BIBLIOGRAFIA
[9] D. Calvanese, G. D. Giacomo, D. Lembo, M. Lenzerini e R. Rosati. “Tractable Rea-
soning and Efficient Query Answering in Description Logics: The DL-Lite Family”.
Em: J. Autom. Reasoning 39.3 (2007), pp. 385–429.
[10] W. Chen e D. S. Warren. “Query Evaluation under the Well Founded Semantics”.
Em: Proceedings of the Twelfth ACM SIGACT-SIGMOD-SIGART Symposium on Prin-
ciples of Database Systems, May 25-28, 1993, Washington, DC, USA. Ed. por C. Beeri.
ACM Press, 1993, pp. 168–179. ISBN: 0-89791-593-3. URL: http://dl.acm.org/
citation.cfm?id=153850.
[11] F. M. Donini, M. Lenzerini, D. Nardi e A. Schaerf. “AL-log: Integrating Datalog and
Description Logics”. Em: J. Intell. Inf. Syst. 10.3 (1998), pp. 227–252.
[12] W. Drabent e J. Maluszynski. “Well-Founded Semantics for Hybrid Rules”. Em:
Web Reasoning and Rule Systems, First International Conference, RR 2007, Innsbruck
, Austria, June 7-8, 2007, Proceedings. Ed. por M. Marchiori, J. Z. Pan e C. de Sainte
Marie. Vol. 4524. Lecture Notes in Computer Science. Springer, 2007, pp. 1–15. ISBN:
978-3-540-72981-5.
[13] T. Eiter, G. Ianni, T. Lukasiewicz e R. Schindlauer. “Well-founded semantics for
description logic programs in the semantic web”. Em: ACM Trans. Comput. Log.
12.2 (2011), 11:1–11:41.
[14] T. Eiter, G. Ianni, T. Lukasiewicz, R. Schindlauer e H. Tompits. “Combining answer
set programming with description logics for the Semantic Web”. Em: Artif. Intell.
172.12-13 (2008), pp. 1495–1539.
[15] T. Eiter, G. Ianni, R. Schindlauer e H. Tompits. “Effective Integration of Declarative
Rules with External Evaluations for Semantic-Web Reasoning”. Em: The Semantic
Web: Research and Applications, 3rd European Semantic Web Conference, ESWC 2006,
Budva, Montenegro, June 11-14, 2006, Proceedings. Ed. por Y. Sure e J. Domingue.
Vol. 4011. Lecture Notes in Computer Science. Springer, 2006, pp. 273–287. ISBN:
3-540-34544-2.
[16] T. Eiter, T. Lukasiewicz, R. Schindlauer e H. Tompits. “Well-Founded Semantics for
Description Logic Programs in the Semantic Web”. Em: Rules and Rule Markup Lan-
guages for the Semantic Web: Third International Workshop, RuleML 2004, Hiroshima,
Japan, November 8, 2004. Proceedings. Ed. por G. Antoniou e H. Boley. Vol. 3323. Lec-
ture Notes in Computer Science. Springer, 2004, pp. 81–97. ISBN: 3-540-23842-5.
[17] A. V. Gelder, K. A. Ross e J. S. Schlipf. “The Well-Founded Semantics for General
Logic Programs”. Em: J. ACM 38.3 (1991), pp. 620–650.
[18] M. Gelfond e V. Lifschitz. “The Stable Model Semantics for Logic Programming”.
Em: Logic Programming, Proceedings of the Fifth International Conference and Sympo-
sium, Seattle, Washington, August 15-19, 1988 (2 Volumes). Ed. por R. A. Kowalski e
K. A. Bowen. MIT Press, 1988, pp. 1070–1080. ISBN: 0-262-61056-6.
127](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-133-320.jpg)
![BIBLIOGRAFIA
[19] B. C. Grau, A. Fokoue, B. Motik, Z. Wu e I. Horrocks, eds. OWL 2 Web Ontology
Language Profiles (Second Edition). Available from http://www.w3.org/TR/
2012/REC-owl2-profiles-20121211/. 2012.
[20] B. N. Grosof, I. Horrocks, R. Volz e S. Decker. “Description logic programs: combi-
ning logic programs with description logic”. Em: Proceedings of the Twelfth Interna-
tional World Wide Web Conference, WWW 2003, Budapest, Hungary, May 20-24, 2003.
Ed. por G. Hencsey, B. White, Y. R. Chen, L. Kovács e S. Lawrence. ACM, 2003,
pp. 48–57. ISBN: 1-58113-680-3.
[21] Y. Guo, Z. Pan e J. Heflin. “LUBM: A benchmark for OWL knowledge base sys-
tems”. Em: J. Web Sem. 3.2-3 (2005), pp. 158–182.
[22] V. Haarslev e R. Möller. “RACER System Description”. Em: Automated Reasoning,
First International Joint Conference, IJCAR 2001, Siena, Italy, June 18-23, 2001, Procee-
dings. Ed. por R. Goré, A. Leitsch e T. Nipkow. Vol. 2083. Lecture Notes in Compu-
ter Science. Springer, 2001, pp. 701–706. ISBN: 3-540-42254-4.
[23] I. Horrocks, P. Patel-Schneider, H. Boley, S. Tabet, B. Grosof e M. Dean, eds. SWRL:
A Semantic Web Rule Language Combining OWL and RuleML. Available from http:
//www.w3.org/Submission/SWRL/. 2004.
[24] I. Horrocks, O. Kutz e U. Sattler. “The Even More Irresistible SROIQ”. Em: KR. Ed.
por P. Doherty, J. Mylopoulos e C. A. Welty. AAAI Press, 2006, pp. 57–67. ISBN:
978-1-57735-271-6.
[25] I. Horrocks, P. F. Patel-Schneider, S. Bechhofer e D. Tsarkov. “OWL rules: A propo-
sal and prototype implementation”. Em: J. Web Sem. 3.1 (2005), pp. 23–40.
[26] U. Hustadt, B. Motik e U. Sattler. “Data Complexity of Reasoning in Very Expres-
sive Description Logics”. Em: IJCAI-05, Proceedings of the Nineteenth International
Joint Conference on Artificial Intelligence, Edinburgh, Scotland, UK, July 30-August 5,
2005. Ed. por L. P. Kaelbling e A. Saffiotti. Professional Book Center, 2005, pp. 466–
471. ISBN: 0938075934. URL: http://www.ijcai.org/papers/0326.pdf.
[27] Y. E. Ioannidis, R. Ramakrishnan e L. Winger. “Transitive Closure Algorithms Ba-
sed on Graph Traversal”. Em: ACM Trans. Database Syst. 18.3 (1993), pp. 512–576.
[28] V. Ivanov, M. Knorr e J. Leite. “A Query Tool for EL with Non-monotonic Rules”.
Em: The Semantic Web - ISWC 2013 - 12th International Semantic Web Conference, Syd-
ney, NSW, Australia, October 21-25, 2013, Proceedings, Part I. Ed. por H. Alani, L.
Kagal, A. Fokoue, P. T. Groth, C. Biemann, J. X. Parreira, L. Aroyo, N. F. Noy, C.
Welty e K. Janowicz. Vol. 8218. Lecture Notes in Computer Science. Springer, 2013,
pp. 216–231. ISBN: 978-3-642-41334-6.
[29] Y. Kazakov, M. Krötzsch e F. Simancik. “The Incredible ELK - From Polynomial
Procedures to Efficient Reasoning with EL Ontologies”. Em: J. Autom. Reasoning
53.1 (2014), pp. 1–61.
128](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-134-320.jpg)
![BIBLIOGRAFIA
[30] M. Knorr, J. J. Alferes e P. Hitzler. “Local closed world reasoning with descrip-
tion logics under the well-founded semantics”. Em: Artif. Intell. 175.9-10 (2011),
pp. 1528–1554.
[31] M. Krötzsch, F. Maier, A. Krisnadhi e P. Hitzler. “A better uncle for OWL: nominal
schemas for integrating rules and ontologies”. Em: Proceedings of the 20th Internati-
onal Conference on World Wide Web, WWW 2011, Hyderabad, India, March 28 - April 1,
2011. Ed. por S. Srinivasan, K. Ramamritham, A. Kumar, M. P. Ravindra, E. Bertino
e R. Kumar. ACM, 2011, pp. 645–654. ISBN: 978-1-4503-0632-4.
[32] D. Lembo, V. Santarelli e D. F. Savo. “A Graph-Based Approach for Classifying
OWL 2 QL Ontologies”. Em: Informal Proceedings of the 26th International Workshop
on Description Logics, Ulm, Germany, July 23 - 26, 2013. Ed. por T. Eiter, B. Glimm,
Y. Kazakov e M. Krötzsch. Vol. 1014. CEUR Workshop Proceedings. CEUR-WS.org,
2013, pp. 747–759. URL: http://ceur-ws.org/Vol-1014/paper_21.pdf.
[33] N. Leone, G. Pfeifer, W. Faber, T. Eiter, G. Gottlob, S. Perri e F. Scarcello. “The DLV
system for knowledge representation and reasoning”. Em: ACM Trans. Comput. Log.
7.3 (2006), pp. 499–562.
[34] A. Y. Levy e M.-C. Rousset. “Combining Horn Rules and Description Logics in
CARIN”. Em: Artif. Intell. 104.1-2 (1998), pp. 165–209.
[35] V. Lifschitz. “Nonmonotonic Databases and Epistemic Queries”. Em: Proceedings
of the 12th International Joint Conference on Artificial Intelligence. Sydney, Australia,
August 24-30, 1991. Ed. por J. Mylopoulos e R. Reiter. Morgan Kaufmann, 1991,
pp. 381–386. ISBN: 1-55860-160-0.
[36] B. Motik, B. C. Grau, I. Horrocks e U. Sattler. “Representing ontologies using des-
cription logics, description graphs, and rules”. Em: Artif. Intell. 173.14 (2009), pp. 1275–
1309.
[37] B. Motik e R. Rosati. “Reconciling description logics and rules”. Em: J. ACM 57.5
(2010), 30:1–30:62.
[38] P. Patel-Schneider, B. Motik e B. C. Grau, eds. OWL 2 Web Ontology Language Direct
Semantics (Second Edition). Available from http://www.w3.org/TR/2012/REC-
owl2-direct-semantics-20121211/. 2012.
[39] L. M. Pereira e J. J. Alferes. “Well Founded Semantics for Logic Programs with
Explicit Negation”. Em: ECAI. 1992, pp. 102–106.
[40] R. Reiter. “On Closed World Data Bases”. Em: Logic and Data Bases. 1977, pp. 55–76.
[41] R. Rosati. “DL+log: Tight Integration of Description Logics and Disjunctive Data-
log”. Em: KR. Ed. por P. Doherty, J. Mylopoulos e C. A. Welty. AAAI Press, 2006,
pp. 68–78. ISBN: 978-1-57735-271-6.
129](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-135-320.jpg)
![BIBLIOGRAFIA
[42] T. Swift. “A New Formulation of Tabled Resolution with Delay”. Em: Progress in Ar-
tificial Intelligence, 9th Portuguese Conference on Artificial Intelligence, EPIA ’99, Évora,
Portugal, September 21-24, 1999, Proceedings. Ed. por P. Barahona e J. J. Alferes. Vol. 1695.
Lecture Notes in Computer Science. Springer, 1999, pp. 163–177. ISBN: 3-540-66548-X.
[43] G. Xiao, T. Eiter e S. Heymans. “The DReW System for Nonmonotonic DL-Programs”.
English. Em: Semantic Web and Web Science. Ed. por J. Li, G. Qi, D. Zhao, W. Nejdl e
H.-T. Zheng. Springer Proceedings in Complexity. Springer New York, 2013, pp. 383–
390. ISBN: 978-1-4614-6879-0.
130](https://image.slidesharecdn.com/19809f35-8979-4305-aa0c-4845c9593aeb-150916204432-lva1-app6892/85/OWL-QL-e-Regras-Nao-Monotonas-136-320.jpg)


































