Baixar para ler offline















![Diretivas de compilação
➢ A maioria dos construtores em OpenMP são diretivas do compilador ou pragmas;
➢ Diretivas consiste em uma linha de código com significado “especial” para o
compilador;
➢ Para C e C++, a diretiva possui a seguinte forma:
○ #pragma omp construct [clause [clause] …]
○ Ex. #pragma omp parallel
➢ Para Fortran:
○ !$OMP PARALLEL
➢ Pragma Parallel
○ Define uma região paralelizável sobre um bloco estruturado de código;
○ As threads bloqueiam no fim da região;
○ Os dados são compartilhados (shared) entre as threads ao menos que seja
especificados de outra forma.](https://image.slidesharecdn.com/openmp-140911171157-phpapp01/85/OpenMP-18-320.jpg)




![Diretiva / Construtor de trabalho
● for / parallel for
○ Permite que os grupos de instruções definidas em um loop sejam
paralelizadas.
float dot_prod(float* a, float* b, int N){
float sum =0.0;
#pragma omp parallel for shared(sum)
for(int i=0;i<N;i++){
sum+=a[i]*b[i];
}
return sum;
}](https://image.slidesharecdn.com/openmp-140911171157-phpapp01/85/OpenMP-25-320.jpg)
![Paralelismo aninhado
● Dentro de uma região paralela, quando as threads encontram outro construtor
paralelo, elas criam novos grupos de threads e tornam-se as threads mestre
desses novos grupos;
● Essas regiões são denominadas regiões paralelas aninhadas e por padrão são
executadas de forma sequêncial, ou seja, o novo grupo criado contém apenas uma
thread, que é a própria thread mestre do grupo.
#pragma omp parallel {
#pragma omp parallel for
for( int i = 0; i < n; i++ ){
#pragma omp parallel for
for( int i = 0; i < n; i++ )
c[i] = a[i]+b[i];
}
}](https://image.slidesharecdn.com/openmp-140911171157-phpapp01/85/OpenMP-26-320.jpg)

![Diretiva / Construtor de trabalho
● single [nowait]
○ com nowait a barreira pode ser relaxada.
#pragma omp parallel
{
#pragma omp single
printf(“Serão %d threads n”, omp_get_num_threads())
taskA();
#pragma omp single nowait
printf(“A thread %d terminou n”, omp_get_thread_num());
}](https://image.slidesharecdn.com/openmp-140911171157-phpapp01/85/OpenMP-28-320.jpg)

![Diretiva / Construtor de sincronização
● critical[(nome)]
○ Permite que trechos de código sejam executados em regime de exclusão
mútua.
int prox_x, prox_y;
#pragma omp parallel shared(x,y) private (prox_x, prox_y)
{
#pragma omp critical(eixox)
prox_x = dequeue(x);
taskA(prox_x,x);
#pragma omp critical(eixoy)
prox_y = dequeue(y);
taskA(prox_y,y);
}](https://image.slidesharecdn.com/openmp-140911171157-phpapp01/85/OpenMP-30-320.jpg)
![Diretiva / Construtor de sincronização
● master [nowait]
○ Indica que em uma região paralela ou um trecho de código deve ser executado
apenas pela thread master;
○ Representa uma barreira;
○ com nowait a barreira pode ser relaxada.
#pragma omp parallel
{
#pragma omp master
printf(“Serão %d threads n”, omp_get_num_threads());
foo();
#pragma omp master nowait
printf(“A thread master terminou n”);
}](https://image.slidesharecdn.com/openmp-140911171157-phpapp01/85/OpenMP-31-320.jpg)
![Diretiva / Construtor de sincronização
● atomic [read, write, update e capture]
Especifica que uma posição de memória deve ser atualizada atomicamente.
#pragma omp atomic
● barrier
Quando esta directiva é alcançada por uma thread, este espera até que os
restantes chegem ao mesmo ponto.
#pragma omp barrier
● flush
Identifica um ponto de sincronização no qual é necessário providenciar uma
visão consistente memória.
#pragma omp flush](https://image.slidesharecdn.com/openmp-140911171157-phpapp01/85/OpenMP-32-320.jpg)
![Cláusula - Schedule
● Cláusula: schedule
○ Afeta como as iterações do laço são mapeadas entre as threads
○ schedule(static [,chunk])
■ Blocos de iterações de tamanho “chunk”
■ Distribuição Round robin
○ schedule(dynamic [,chunk])
■ Iteração de tamanho “chunk”
■ Ao terminar as iterações, a thread requisita o próximo passo
○ schedule(guided [,chunk])
■ Agendamento dinâmico iniciado com um tamanho grande
■ O tamanho dos blocos diminui, não menor do que “chunk”](https://image.slidesharecdn.com/openmp-140911171157-phpapp01/85/OpenMP-33-320.jpg)






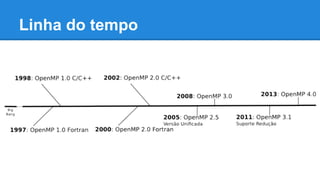
O documento apresenta uma introdução ao OpenMP, incluindo sua origem, objetivos, modelos de memória e execução, serviços, variáveis de ambiente e diretivas. É detalhada a sintaxe e uso de diretivas como parallel, for, sections e cláusulas como schedule e if.



































































