Baixar para ler offline























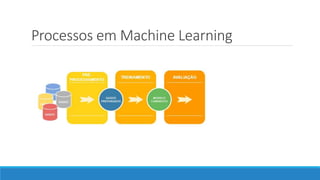
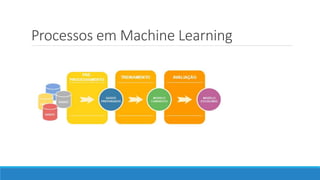
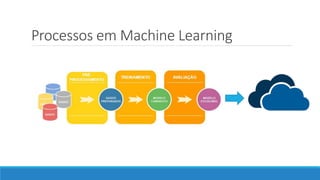







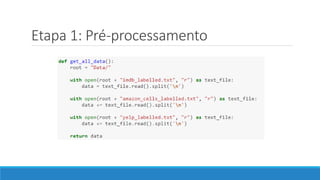
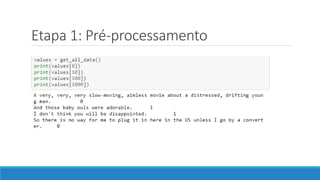
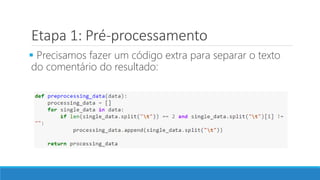

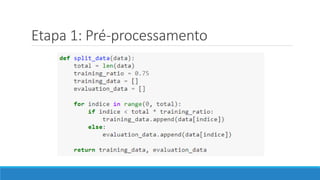


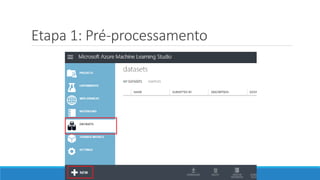
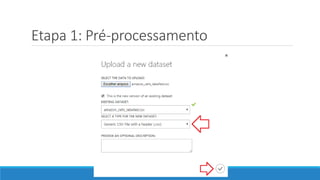

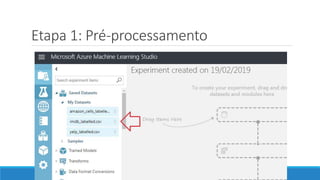

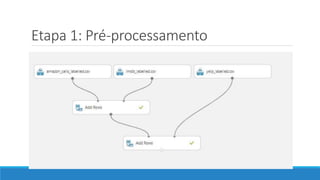
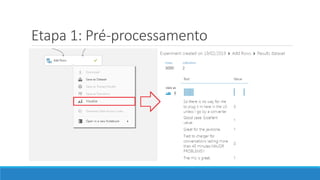

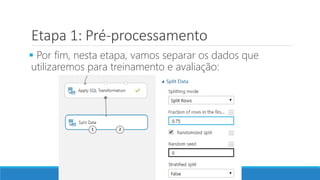


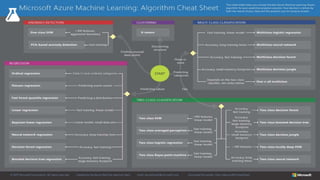








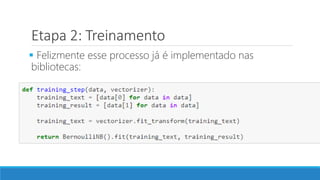
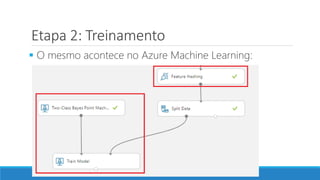
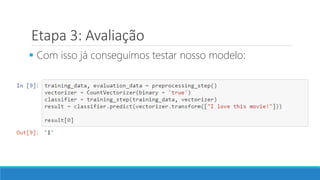

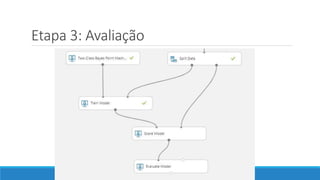







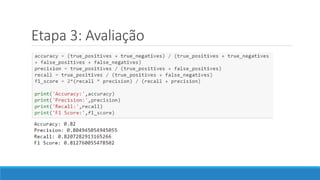



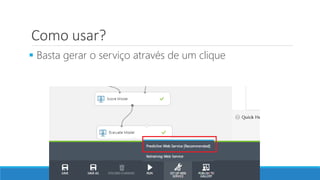
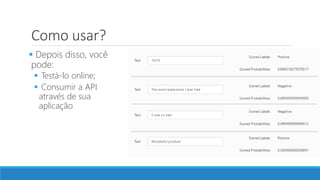




O documento discute o machine learning, definindo suas etapas e processos, começando com a coleta e pré-processamento de dados, seguido pelo treinamento de um modelo para classificar comentários como positivos ou negativos. Ele destaca a importância de algoritmos e técnicas como vectorização para análise de texto, além de avaliar o modelo utilizando métricas de desempenho. O autor também menciona a utilização de plataformas como Azure Machine Learning para facilitar o desenvolvimento e a implementação de modelos de machine learning.

![[DTC21] Raphael Castilho - Começando com Inteligência Artificial e Machine Le...](https://cdn.slidesharecdn.com/ss_thumbnails/iaemachine-210317154040-thumbnail.jpg?width=640&height=640&fit=bounds)








































