

![Sobre o palestrante Márcio Alves Marinho Profissional com mais de 15 anos de experiência no mercado de T.I, trabalhando diversas empresas públicas e privadas, em uma grande variedade de domínios de negócio, tais como engenharia civil, automação comercial, finanças, forças armadas, dentre outros. Seu perfil inclui gerenciamento de projetos e equipes, arquitetura de software, design, OOAD, SOA, EAI, Web Services, revisão de código, mentoring, coaching, Scrum, XP, Java, JavaEE, C++, .NET Framework, C#, ASP.NET, ASP.NET MVC, Ruby, Rails, Webphere AS, Websphere MQ, JBoss, Weblogic, dentre outos. Pós-graduado pelo NCE/UFRJ IBM SOA Certified Solution Designer Certified Scrum Master Sun Certified Enterprise Architect Sun Certified Business Components Developer Sun Certified Web Components Developer Sun Certified Java Programmer LinkedIn http://www.linkedin.com/in/marciomarinho Twitter http://twitter.com/marciomarinho Facebook http://www.facebook.com/marcio.a.marinho Blog : www.marciomarinho.com Contato : [email_address] / 8115-9884](https://image.slidesharecdn.com/jbossclustering4-100226105123-phpapp01/85/JBoss-Clustering-2-320.jpg)







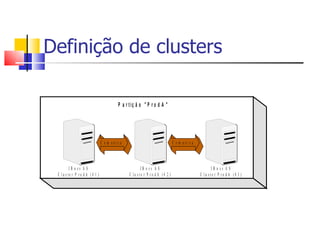

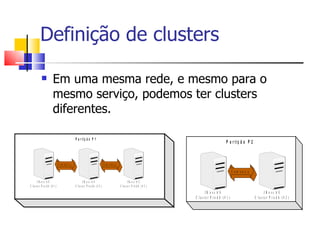

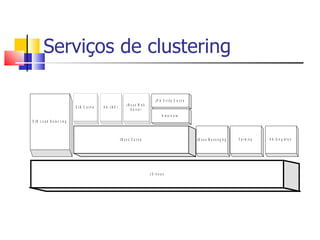









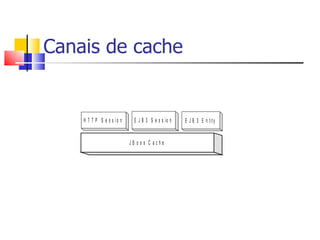


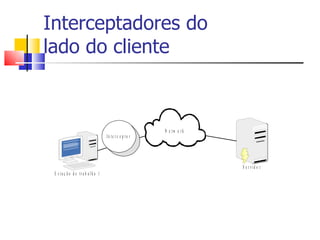


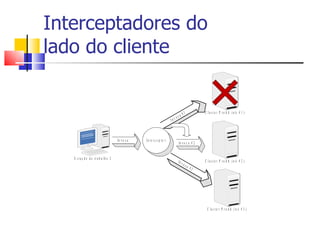





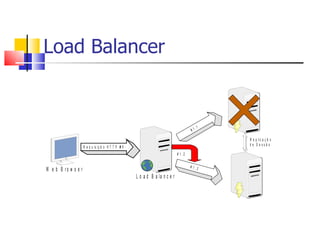





















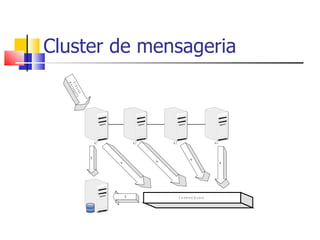







1) O documento discute clustering e alta disponibilidade no JBoss, incluindo definição de clusters, partições, canais de cache e interceptadores do lado do cliente. 2) É apresentada a arquitetura do JGroups e como ele fornece comunicação entre os nós do cluster. 3) Serviços como sessões HTTP, EJBs e mensageria podem ser clusterizados no JBoss.



























