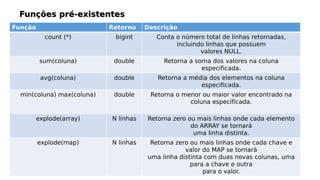
Transferir como PDF, PPTX








![Operador Descrição
A [NOT] BETWEEN B AND C Retorna true se A for maior ou igual a B e A
for menor ou
igual a C Isso pode ser invertido através da
palavra NOT.
A IS NULL Retorna true se a expressão A for nula
A IS NOT NULL Retorna NULL se A ou B forem nulos.
Retorna true se a expressão A não for igual
a expressão B e false caso
sejam iguais
A [NOT] LIKE B Exemplo: ‘foobar’ LIKE ‘foo’ = false ‘foobar’
LIKE ‘foo___’ = true ‘foobar’ LIKE ‘foo%’ =
true
A RLIKE B Exemplo: ‘foobar’ RLIKE ‘foo’ ⇒ true
A REGEXP B O mesmo que RLIKE](https://image.slidesharecdn.com/rafaelsancheshive-200216212633/85/Introducao-ao-Hive-12-320.jpg)
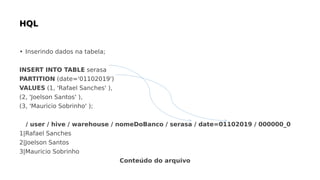
![Função Retorno Descrição
round(double A) bigint Valor arredondado
floor(double A) bigint maior inteiro tal que seja menor ou igual ao
parâmetro
celi(double A) bigint menor inteiro tal que seja maior ou igual ao
parâmetro
substr(string A, int start) string Substring de A com início no caractér da posição
start até o final da string
A
upper(string A) string Conversão de todos os caractéres de A para letras
maíusculas
length(string S) int Tamanho da string
year(string timestamp) int Apenas o ano da string timestamp
get_json_object(string
jsonString, string
path)
string Extrai de uma string JSON um objeto JSON
baseado no caminho
especificado.
Exemplo: get_json_object(src_json.json,
'$.store.fruit[0]')](https://image.slidesharecdn.com/rafaelsancheshive-200216212633/85/Introducao-ao-Hive-13-320.jpg)
















O documento discute o Hive, um sistema de armazenamento e processamento de dados para Hadoop. O Hive foi desenvolvido inicialmente pelo Facebook para lidar com grandes volumes de dados e permite consultas em SQL. Ele organiza os dados em tabelas e partições semelhantes a bancos de dados, mas é otimizado para análise em batch em clusters Hadoop de baixo custo.















































