Baixar para ler offline



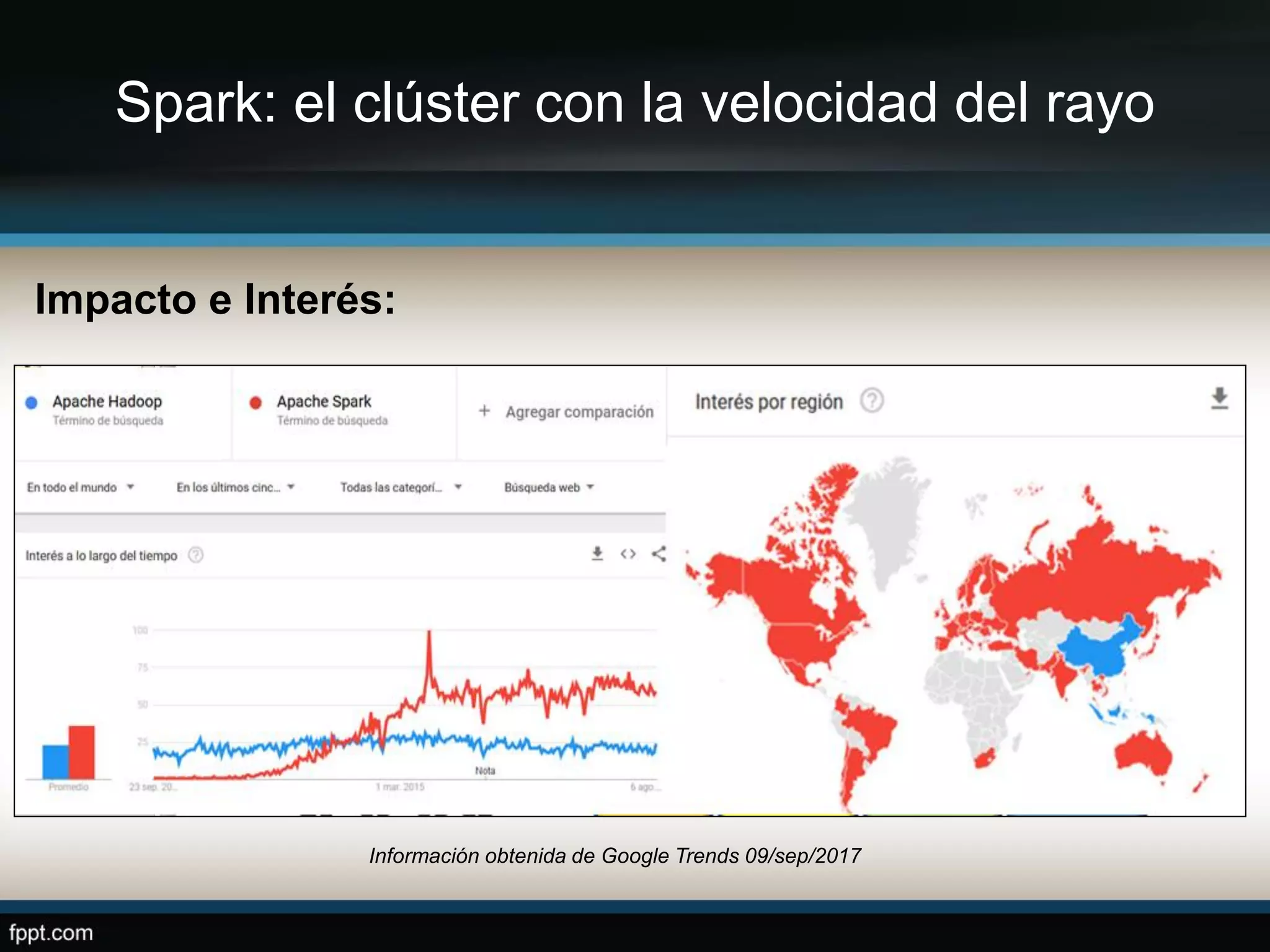

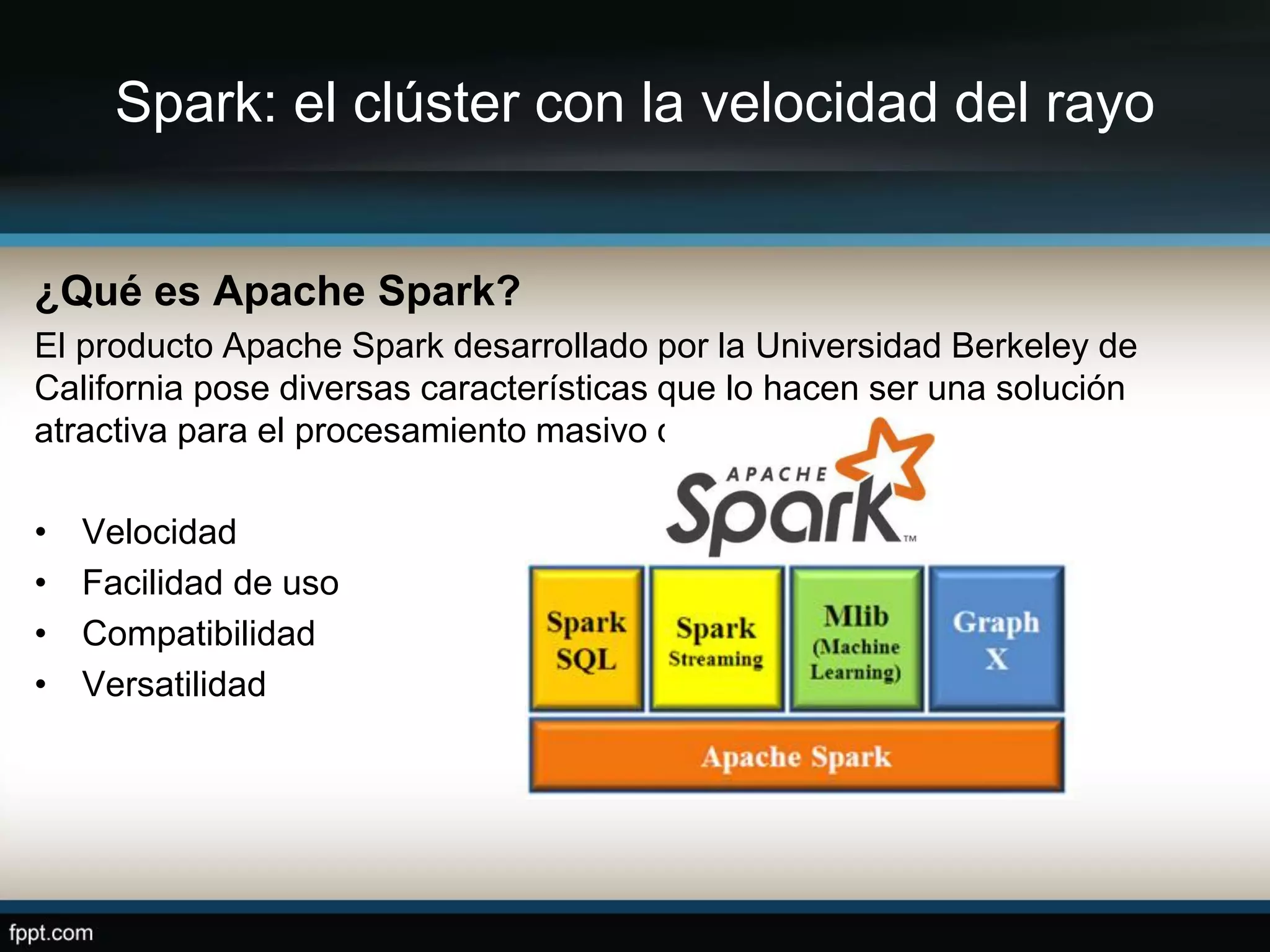

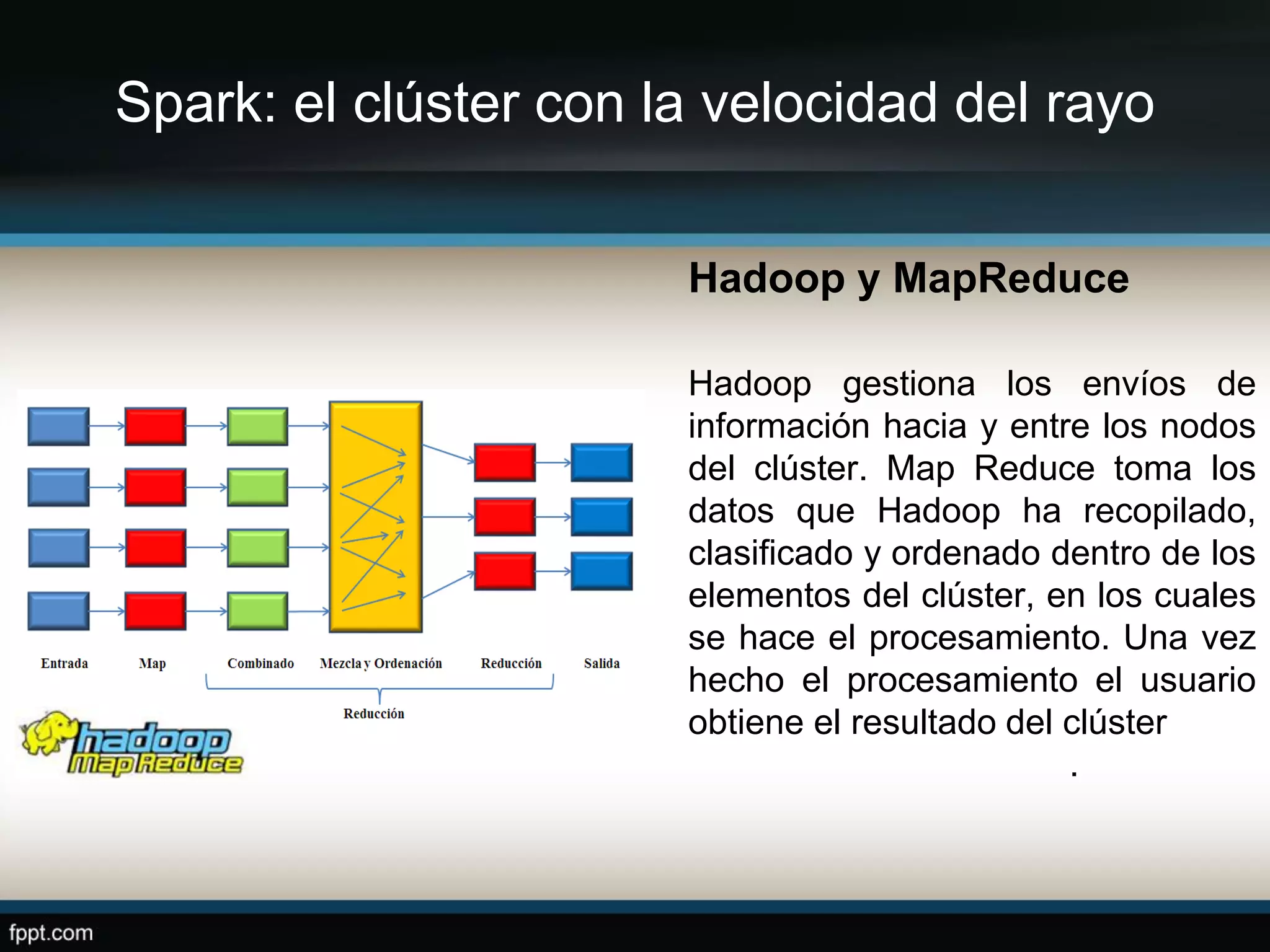
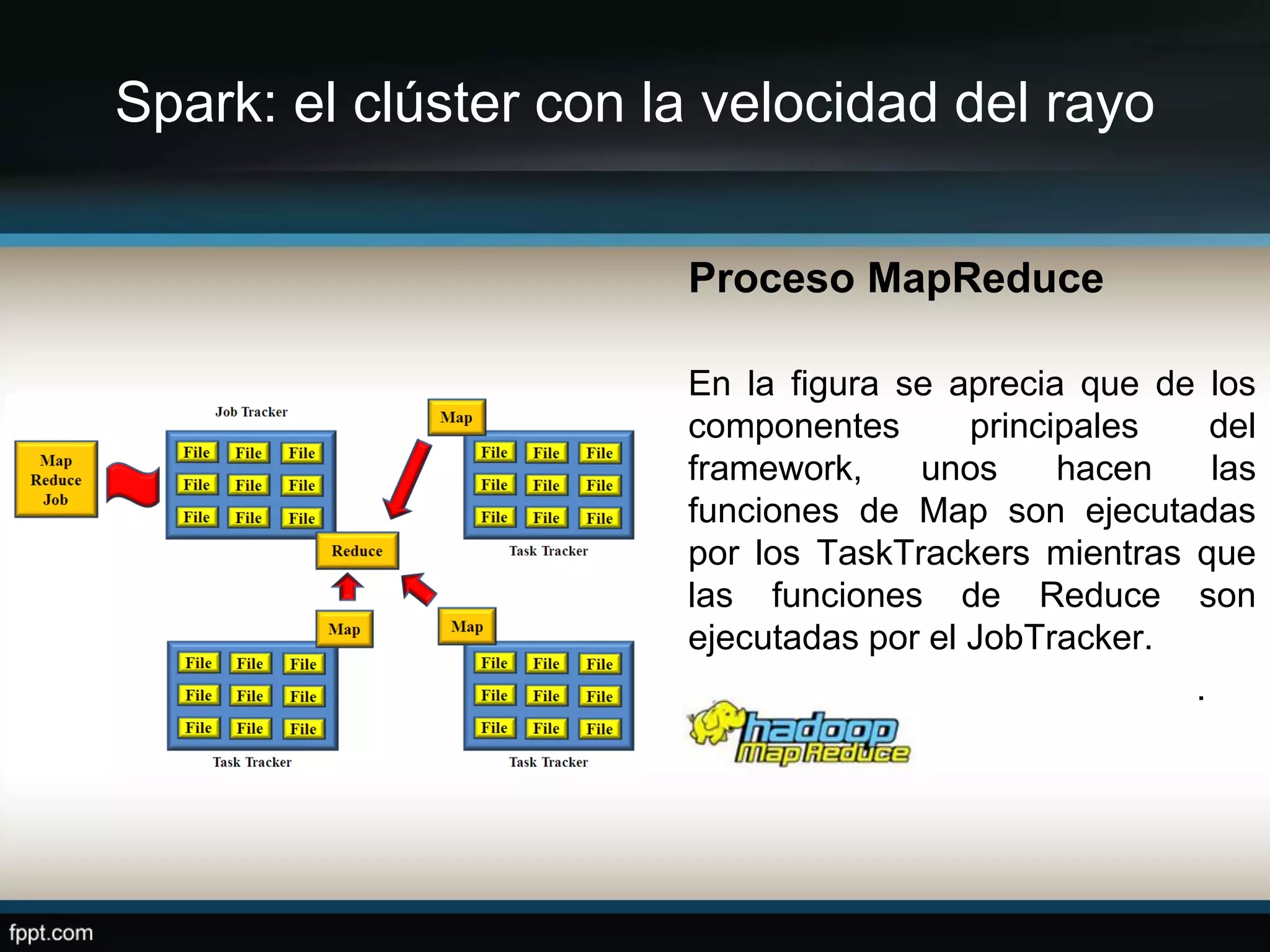
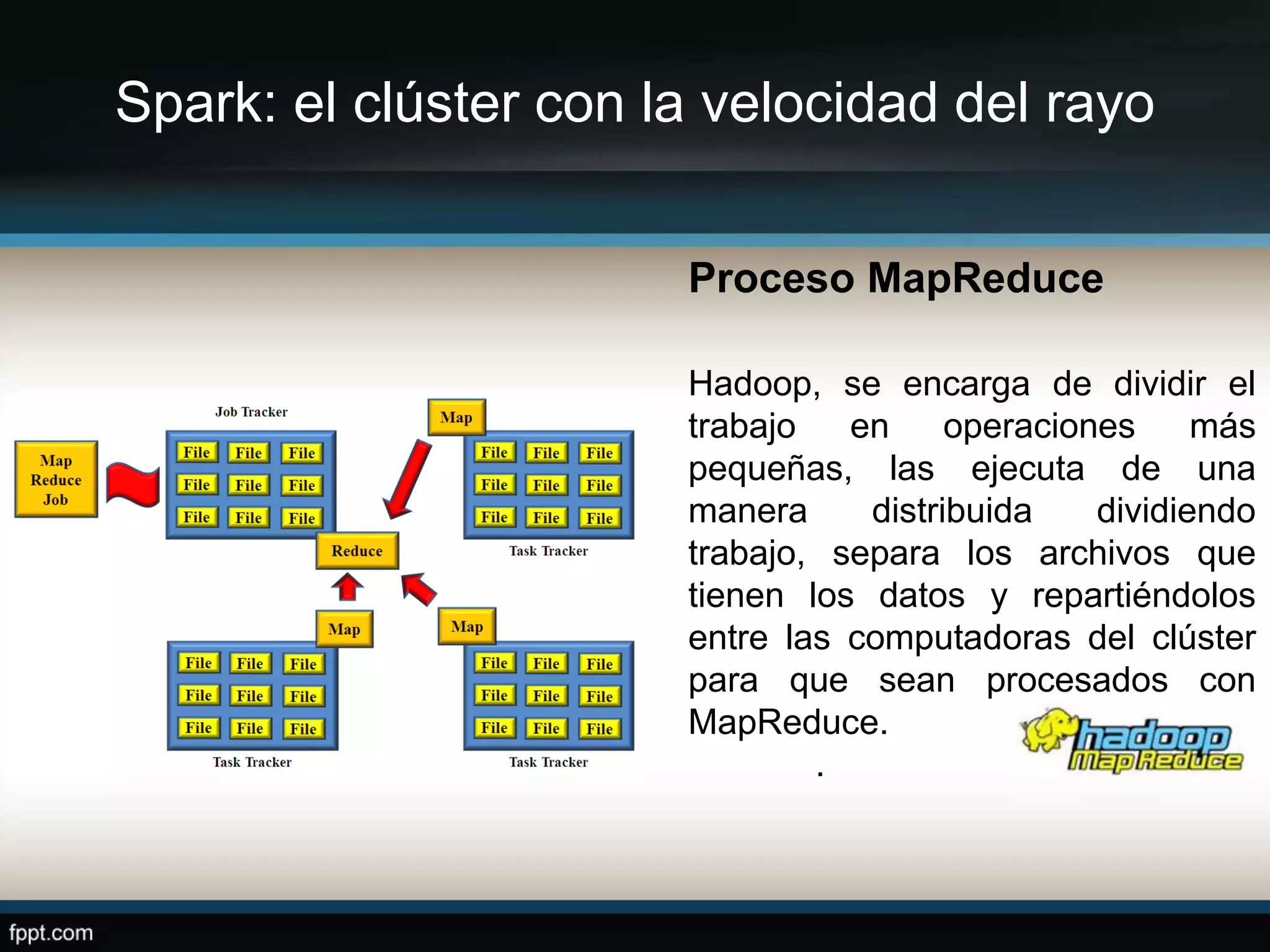
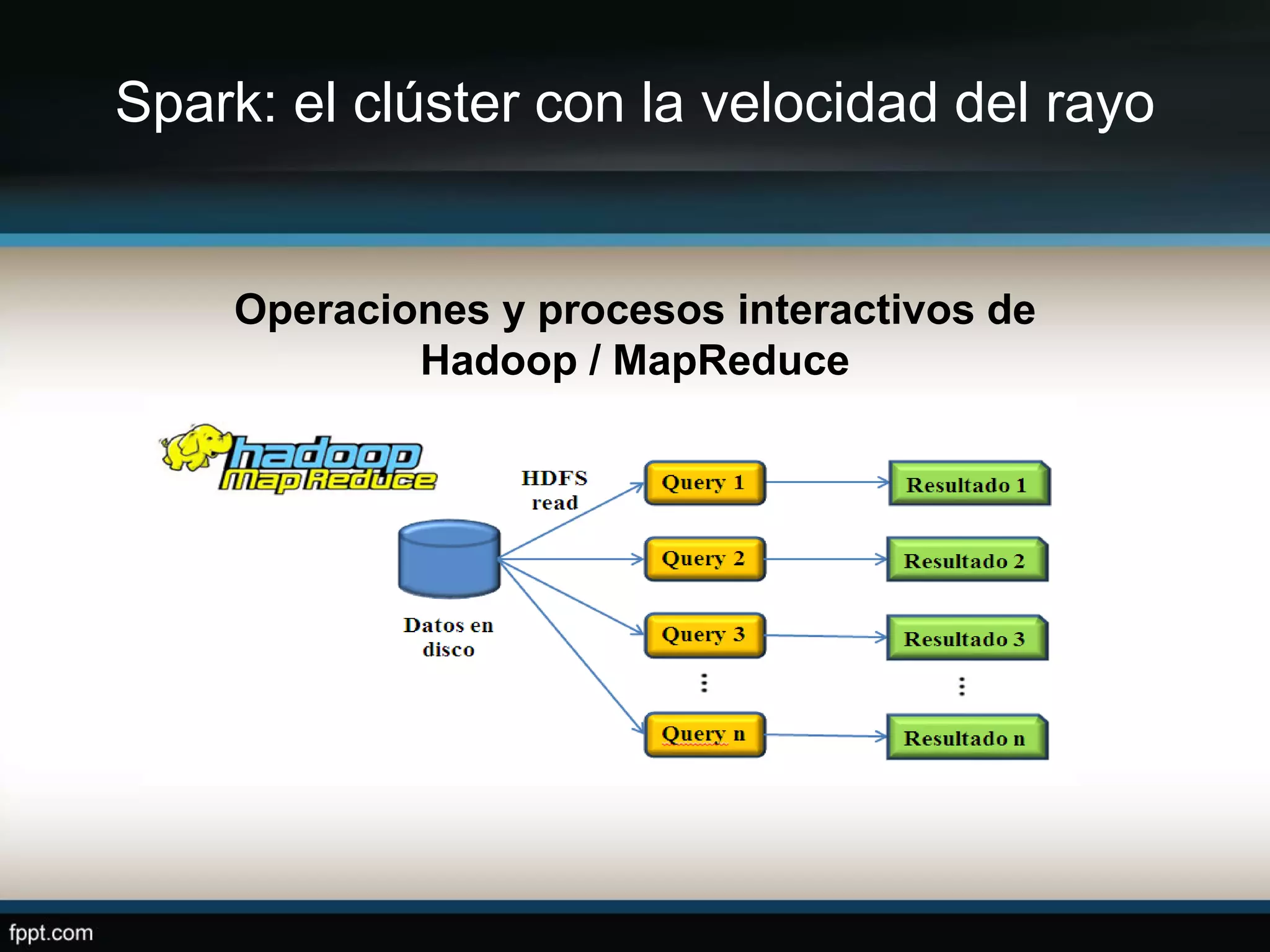

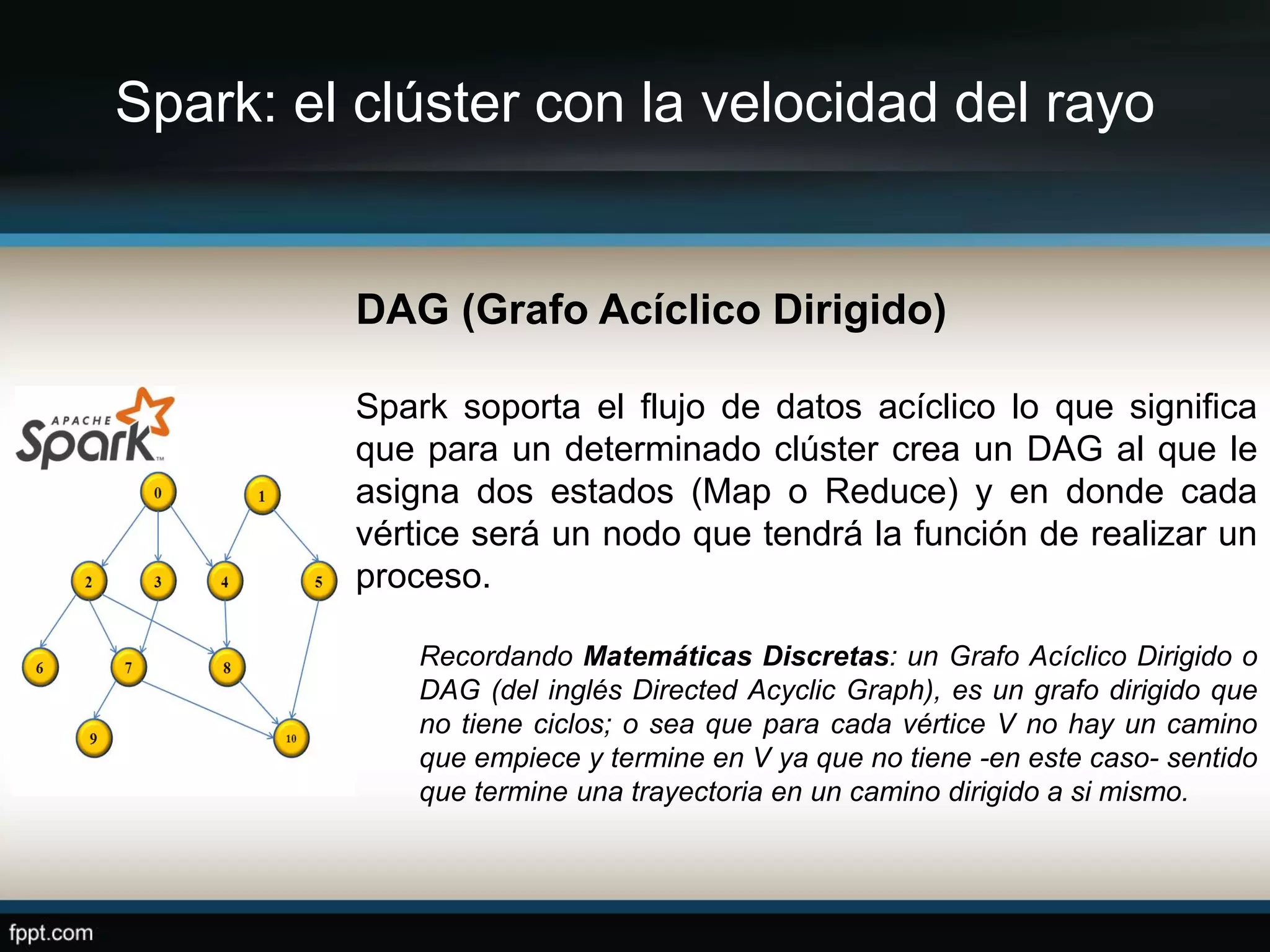

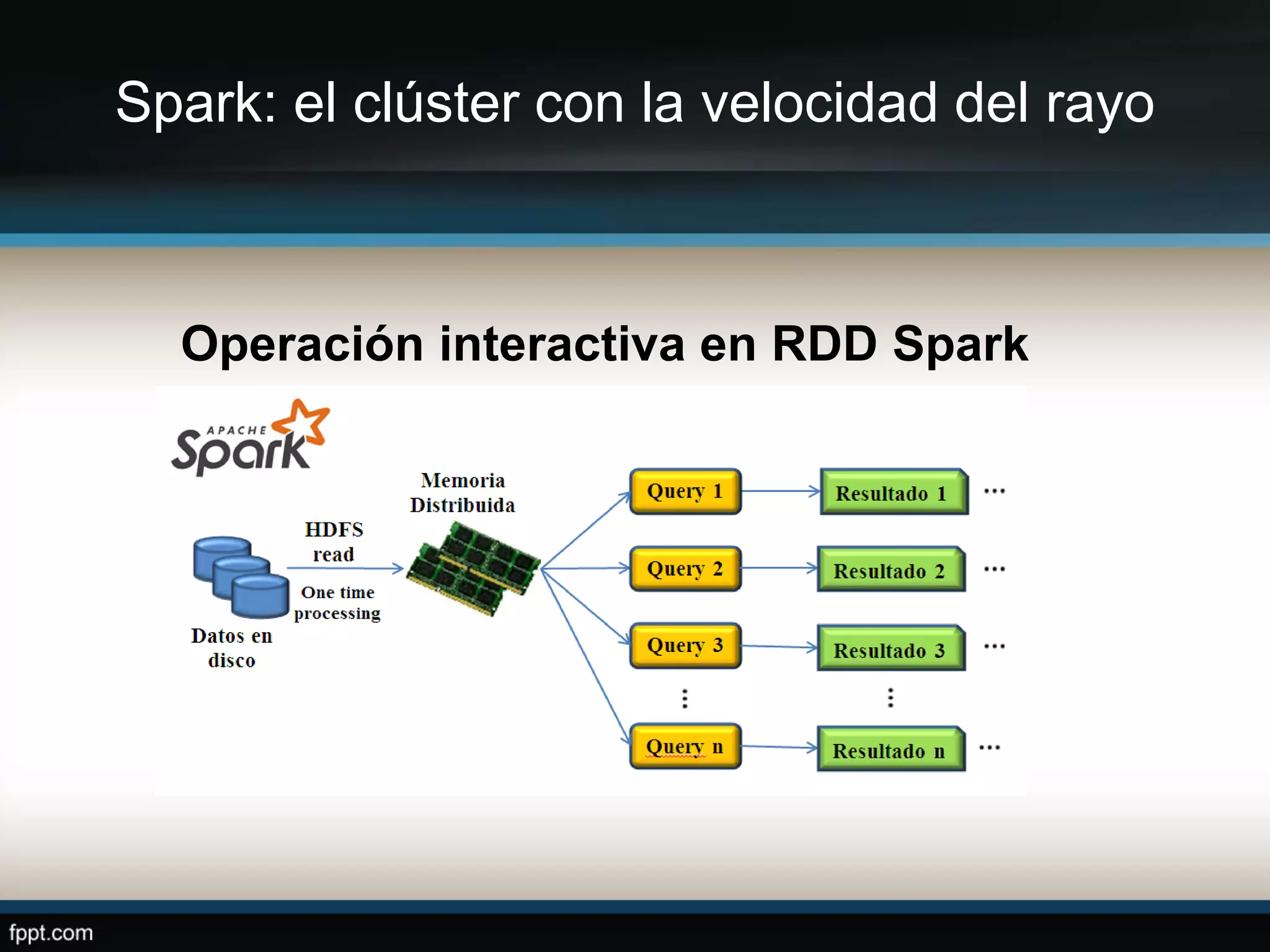
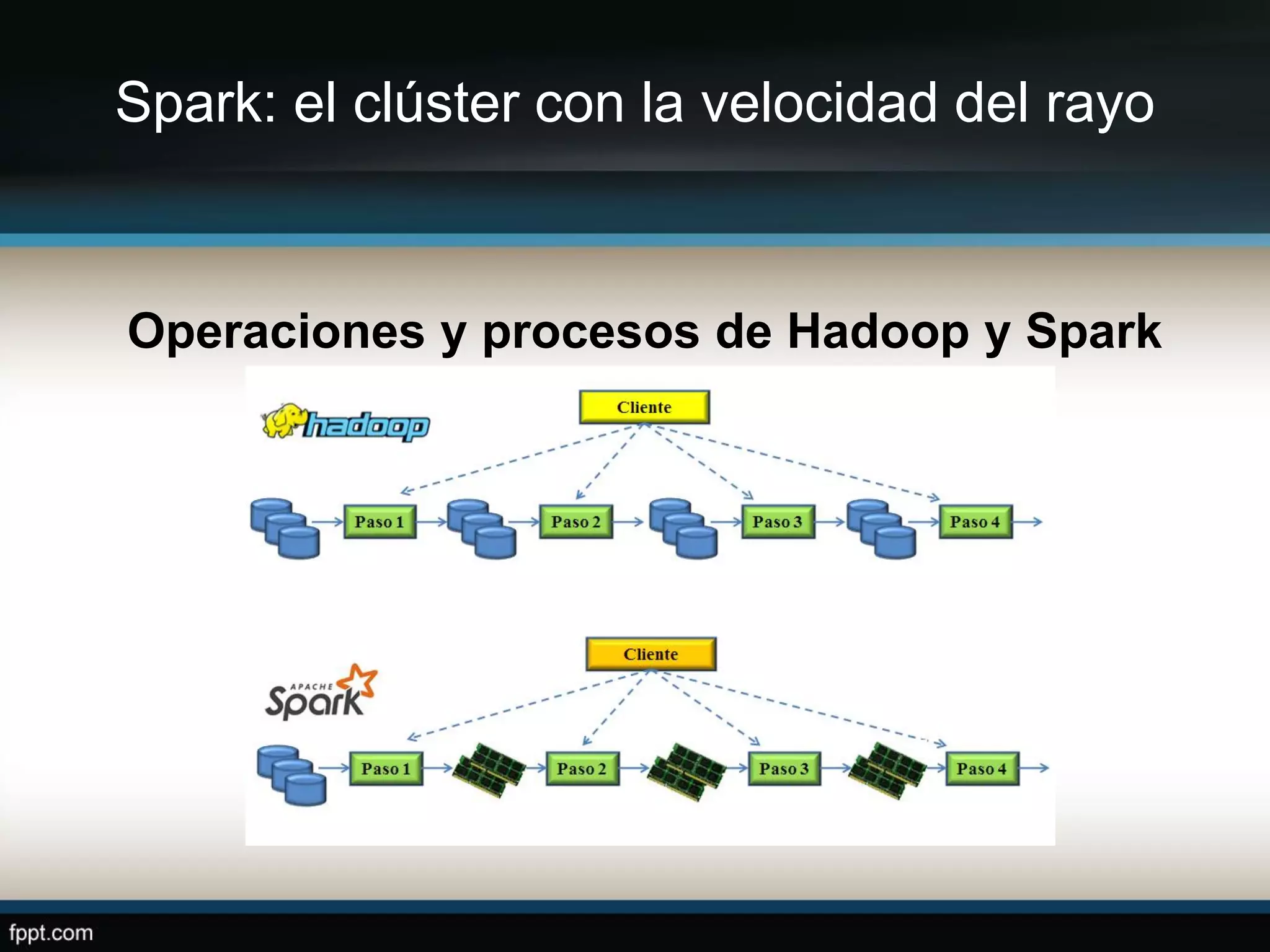




Este documento compara Apache Hadoop y Apache Spark, dos frameworks para procesar grandes cantidades de datos. Explica que Spark es más rápido que Hadoop debido a que usa memoria en lugar de disco, pero depende de Hadoop para almacenamiento. También describe las características clave de cada uno como RDDs, DAG y MapReduce. La conclusión es que ambos son complementarios y lo mejor es implementarlos juntos.





















































































