Baixar para ler offline









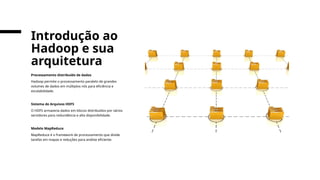
























Uma introdução essencial aos Fundamentos de Big Data usando o ecossistema Python. Descubra os conceitos-chave (3 Vs), os desafios do processamento em larga escala e por que o Pandas sozinho não é suficiente. Apresenta as principais ferramentas como Dask e PySpark para processamento distribuído.




![[DTC21] Lucas Gomes - Do 0 ao 100 no Big Data](https://cdn.slidesharecdn.com/ss_thumbnails/dtc21lucasgomes-do0ao100embigdata-210316214734-thumbnail.jpg?width=640&height=640&fit=bounds)



































