Baixar para ler offline



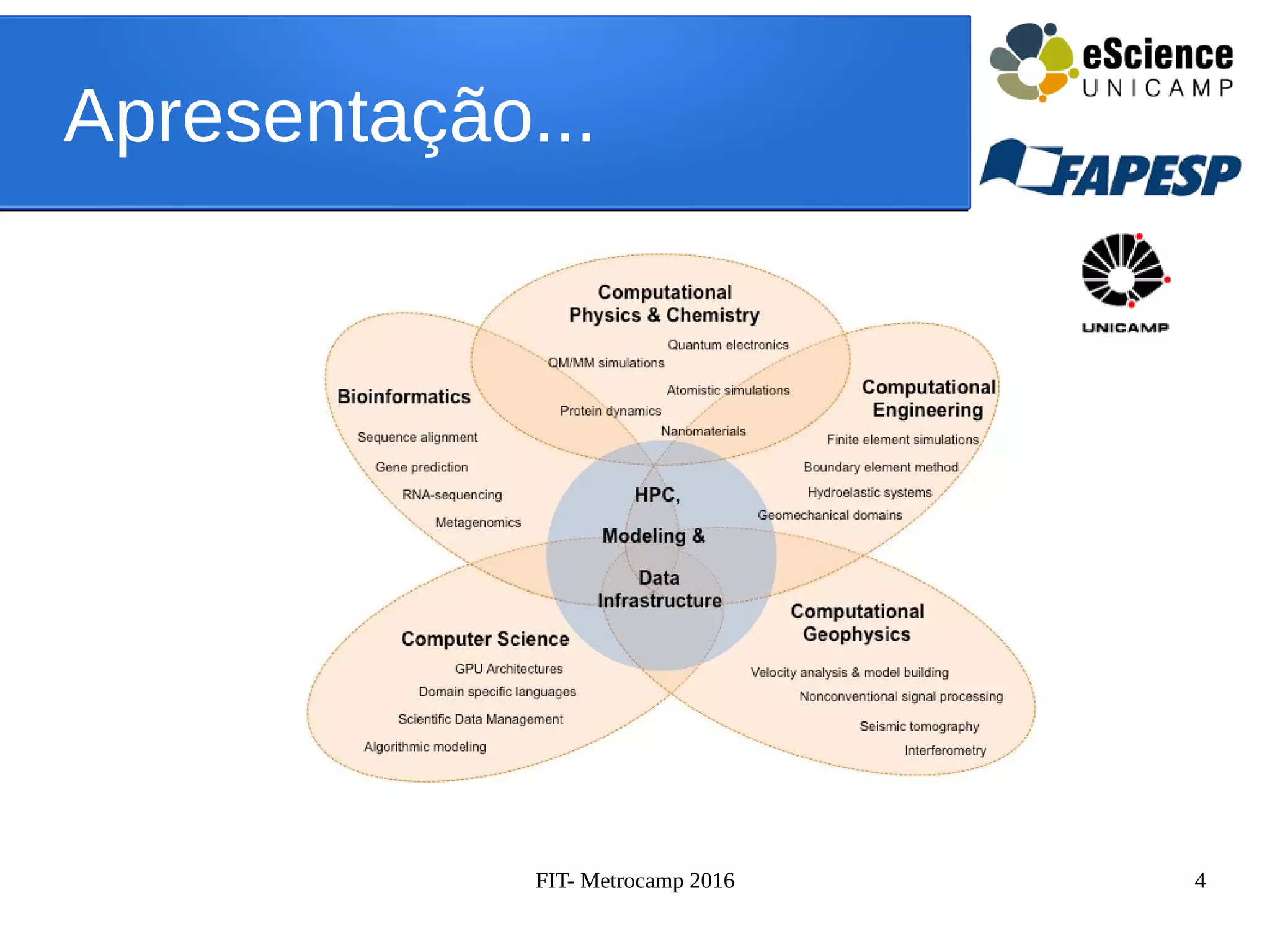












![FIT- Metrocamp 2016 17
OpenMP
SAXPY z = Ax + y
#include <stdio.h>
#define N 1000000
#define A 10
int main () {
int i, z[N], x[N], y[N];
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
return 0;
}
Serial](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-17-2048.jpg)
![FIT- Metrocamp 2016 18
OpenMP
SAXPY z = Ax + y
#include <stdio.h>
#define N 1000000
#define A 10
int main () {
int i, z[N], x[N], y[N];
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
return 0;
}
Serial
#pragma omp parallel for
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
Paralelo](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-18-2048.jpg)
![FIT- Metrocamp 2016 19
OpenMP
Pool de Threads
int main () {
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
for(i = 0; i < N; i++){
z[i] = A * x[i] / y[i];
}
return 0;
}
Serial](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-19-2048.jpg)
![FIT- Metrocamp 2016 20
OpenMP
Pool de Threads
int main () {
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
for(i = 0; i < N; i++){
z[i] = A * x[i] / y[i];
}
return 0;
}
Serial
#pragma omp parallel
{
#pragma omp for
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
#pragma omp for
for(i = 0; i < N; i++){
z[i] = A * x[i] / y[i];
}
}
Paralelo](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-20-2048.jpg)

![FIT- Metrocamp 2016 22
OpenMP
Scheduling - Static
Divide o loop em pedaços de tamanhos iguais ou quanto possivel no caso do numero de
iterações não serem divisíveis pelo número de threads multiplicados pelo tamanho do
pedaço.
#pragma omp parallel for schedule(static)
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
T0 T1 T2 T3
T0 T1 T2 T3 T0 T1 T2 T3 T0 T1 T2 T3
static,1
static,3](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-22-2048.jpg)
![FIT- Metrocamp 2016 23
OpenMP
Scheduling - Dynamic
Usa a fila de trabalho interna para dar o tamanho do pedaço do bloco das iterações de
cada thread. Quando uma thread termina, ele pega o próximo bloco de iterações do loop
do topo da fila.
#pragma omp parallel for schedule(dynamic)
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
T0 T1T2 T3 T0T1T2 T3 T0T1 T2 T3
dynamic,3](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-23-2048.jpg)
![FIT- Metrocamp 2016 24
OpenMP
Scheduling - Guided
Similar ao dynamic scheduling, porém o tamanho começa em um tamanho maior e vai
diminuindo para lidar com o desbalanceamento entre as iterações.
#pragma omp parallel for schedule(guided)
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
}
T0 T1T2 T3 T0T1T2 T3 T0T1 T2 T3
guided,3](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-24-2048.jpg)
![FIT- Metrocamp 2016 25
OpenMP
Reduction
A redução consiste em realizar uma operação em todos os elementos de um vetor.
#pragma omp parallel for reduction(+:sum)
for(i = 0; i < N; i++){
sum += A * x[i] + y[i];
}
5 4 36
11 7
18
+ + +
+](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-25-2048.jpg)
![FIT- Metrocamp 2016 26
OpenMP
Private – Shared – Atomic
#pragma omp parallel for private(w)
for(i = 0; i < N; i++){
w = x[i] * y[i];
z[i] = A * x[i] + y[i];
}
Private
#pragma omp parallel for private(z)
for(i = 0; i < N; i++){
z[i] = A * x[i] + y[i];
#pragma omp atomic
sum++;
}
Atomic
#pragma omp parallel for shared(A)
for(i = 0; i < N; i++){
z = x[i] * y[i];
z[i] = A * x[i] + y[i];
}
Shared](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-26-2048.jpg)




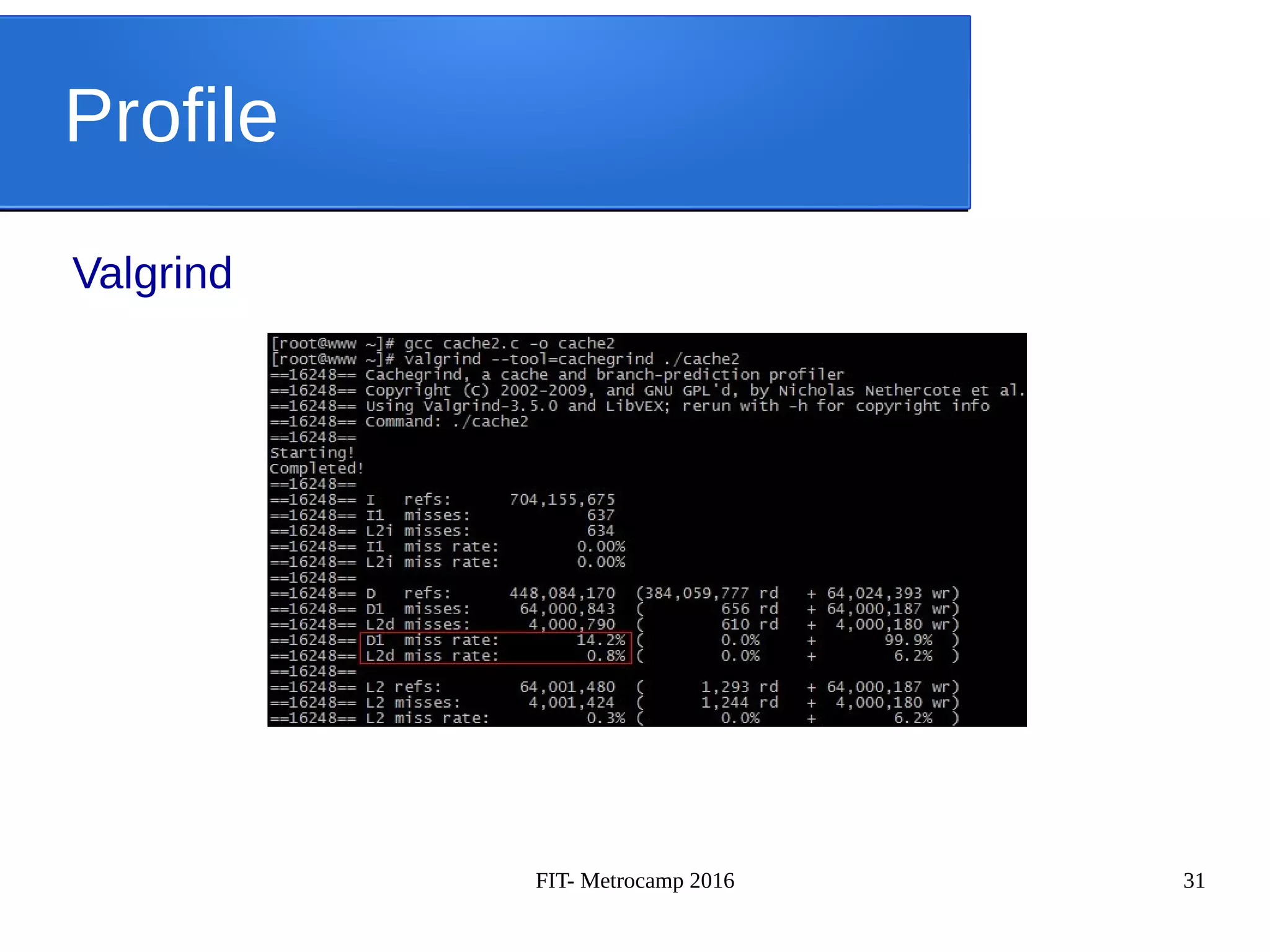






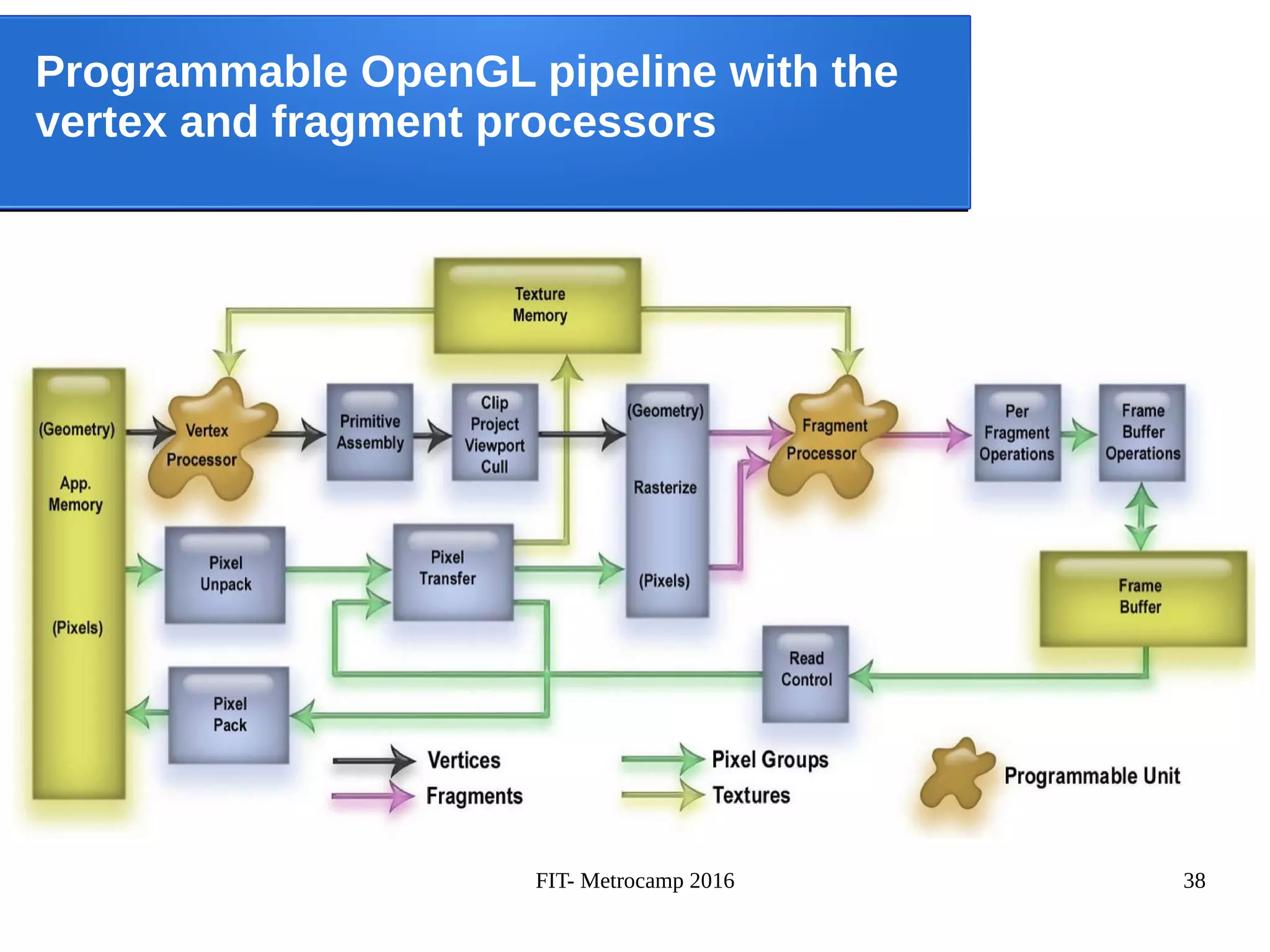

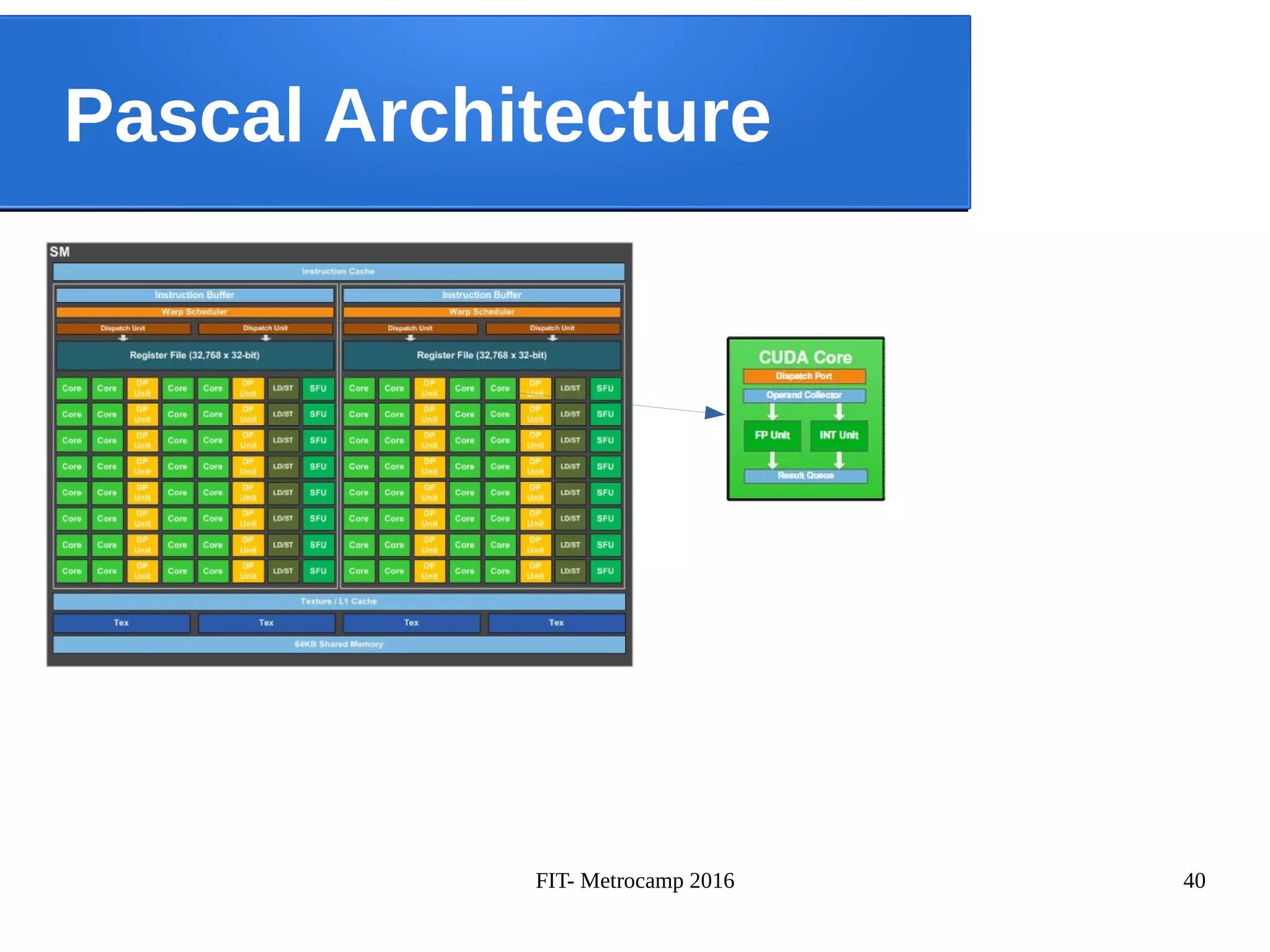

![FIT- Metrocamp 2016 42
Programação com CUDA
void saxpy(int n, float a, float *x, float *y, float *z)
{
for(int i = 0; i < n; i++){
z[i] = a * x[i] + y[i];
}
Serial
SAXPY z = Ax + y](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-42-2048.jpg)
![FIT- Metrocamp 2016 43
Programação com CUDA
__global__ void saxpy(int n, float a, float *x, float *y, float *z)
{
tid = threadIdx.x + blockDim.x * blockIdx.x ;
if (tid < n) {
z[tid] = a * x[tid] + y[tid];
}
}
CUDA
SAXPY z = Ax + y](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-43-2048.jpg)


![FIT- Metrocamp 2016 46
Programação com CUDA
Um CUDA Kernel em um Grid que possui um conjunto de threads
__global__ void saxpy(int n, float a, float *x, float *y, float *z)
{
tid = threadIdx.x + blockDim.x * blockIdx.x ;
if (tid < n) {
z[tid] = a * x[tid] + y[tid];
}
}
...0 1 2 3 254 255](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-46-2048.jpg)
![FIT- Metrocamp 2016 47
Programação com CUDA
Thread Blocks
...0 1 2 3 254 255
__global__ void saxpy(int n, float a, float *x, float *y, float *z)
{
tid = threadIdx.x + blockDim.x * blockIdx.x ;
if (tid < n) {
z[tid] = a * x[tid] + y[tid];
}
}
Thread Block 0
...0 1 2 3 254 255
__global__ void saxpy(int n, float a, float *x, float *y, float *z)
{
tid = threadIdx.x + blockDim.x * blockIdx.x ;
if (tid < n) {
z[tid] = a * x[tid] + y[tid];
}
}
Thread Block N - 1...](https://image.slidesharecdn.com/fitmetrocamp2016-160602163536/75/Fit-Metrocamp-2016-47-2048.jpg)

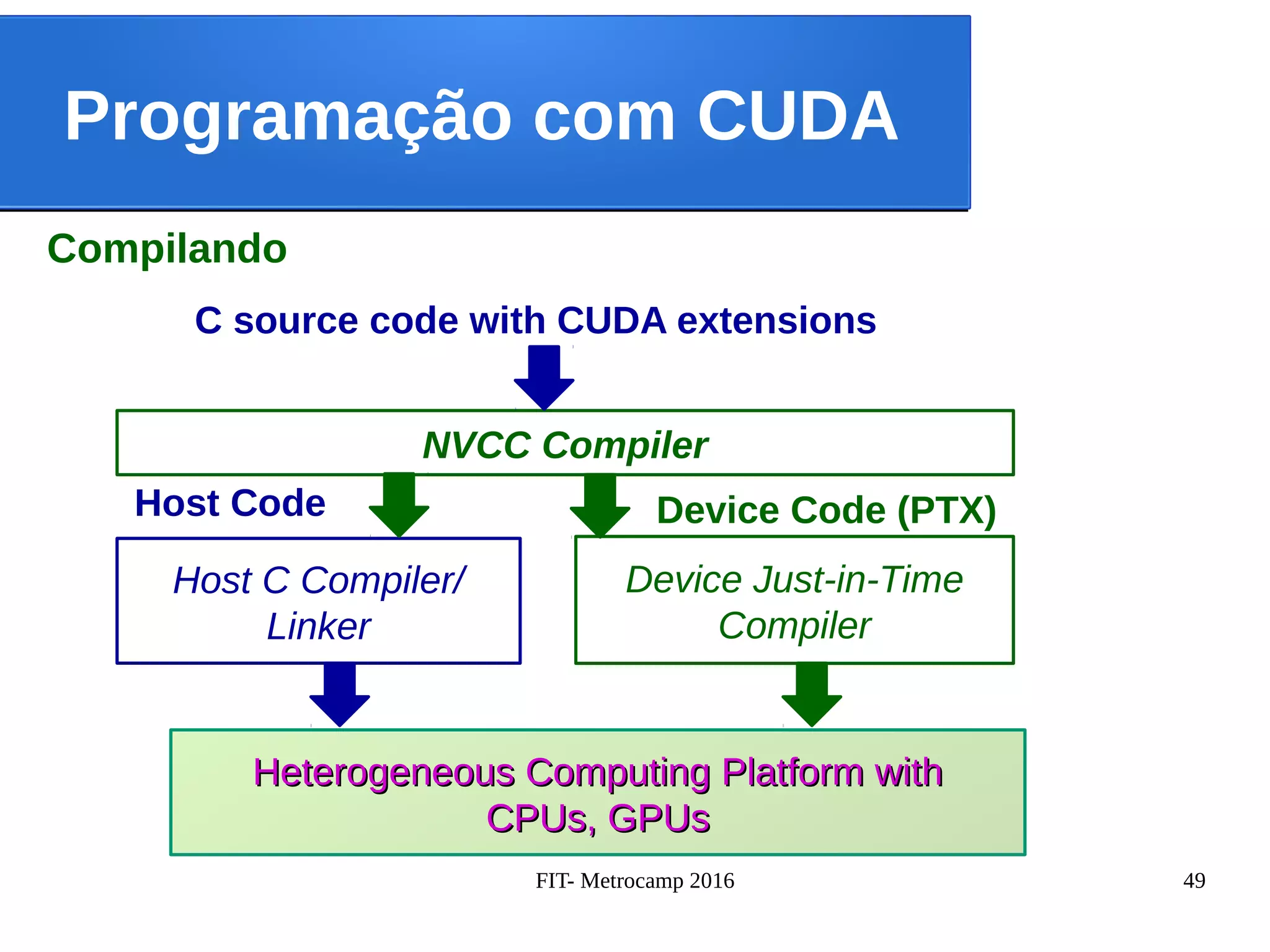


O documento apresenta conceitos de paralelização com OpenMP e CUDA. Resume os principais pontos da apresentação sobre o desenvolvimento de software para HPC no Centro de Engenharia e Ciências Computacionais da Unicamp, introduz os conceitos de multicore e motivação para paralelização, e descreve brevemente os modelos de programação OpenMP e CUDA.




![(2013-05-20) [DevInSampa] AudioLazy - DSP expressivo e em tempo real para o P...](https://cdn.slidesharecdn.com/ss_thumbnails/20130520devinsamparevisedptbr-130520113224-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[Ottoni micro05] resume](https://cdn.slidesharecdn.com/ss_thumbnails/ottonimicro05resume-111220195110-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










