Baixado 55 vezes



![Descrição do Problema Original
Busca por padrão de Strings
O problema consiste em dado o texto T e o padrão P encontrar
todas as ocorrências de P dentro de T.
Todo s tal que T[s + 1…s + m] = P [1...m], onde s é o índice de cada
ocorrência e m é o tamanho do padrão P.
Busca em um texto dinâmico através de um algoritmo aquele que
não se tem informações prévias sobre ele.
Existem cinco algoritmos: Força Bruta, Rabin-Karp, busca por
Autômato, Knuth-Morris-Pratt e Boyer-Moore.](https://image.slidesharecdn.com/apresenta-c3-a7-c3-a3o-130621144121-phpapp01/85/Algoritmo-de-Rabin-Karp-3-320.jpg)




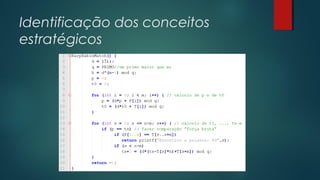
![Pseudocódigo
RABIN-KARP-MATCHER (T, P, d, q)
(1) n tamanho [T];
(2) m tamanho [P];
(3) h dm-1
mod q;
(4) p 0;
(5) t0 0
(6) for i 1 to m
(7) do p (dp + P[i]) mod q;
(8) t0 (dt0 + T[i]) mod q;
(9) for s 0 to n - m
(10) do if p = ts
(11) then if P[1..m] = T[s + 1..s + m]
(12) then “Encontrou a palavra”;
(13) if s < n – m
(14) then ts+1 (d(ts – T[s + 1]h) + T[s + m + 1]) mod q;](https://image.slidesharecdn.com/apresenta-c3-a7-c3-a3o-130621144121-phpapp01/85/Algoritmo-de-Rabin-Karp-8-320.jpg)
![Funcionamento do Algoritmo
Linhas[1-5]: inicialização das variáveis. É importante ressaltar que a
implementação da função hash é arbitraria;
Linhas [6-8]: iteração com índice relacionado à cardinalidade da palavra.
O bloco inicializa o hash(p) da palavra e do texto, hash(t);
Linhas [9-14]: iteração de comparação; na linha 10 em caso da
comparação ser valida tem a possibilidade da substring encontrada ser a
procurada. Observa-se que esta linha apresenta o caráter probabilístico
do algoritmo. Uma comparação extra é realizada para confirmar o
resultado; não comparando a hash como na anterior, mas os caracteres
da substring com a palavra.
Em caso negativo da comparação, temos um novo valor de hash(t) para
a substring, realizando a iteração ate encontrar a palavra(s) ou se esgotar
o texto.](https://image.slidesharecdn.com/apresenta-c3-a7-c3-a3o-130621144121-phpapp01/85/Algoritmo-de-Rabin-Karp-9-320.jpg)
![Complexidade
Pior Caso: é O((n – m + 1)m), podendo ser reduzida a O(nm), este
caso ocorreria quando o numero de colisões fosse elevado, o que
obrigaria o algoritmo a realizar um maior numero de comparações e
operações para se obter um novo valor de hash(t).
Nos casos médio e melhor: este algoritmo trabalha em O(m + n). A
prova para estes casos é complicada, devido principalmente ao
caráter probabilístico deste algoritmo, pode-se obter demonstração
em [Cor97].
Apesar de ser probabilístico este algoritmo não se apresenta eficiente
na busca de textos que estejam em constante mudança, já para
textos que não são modificados constantemente ele poderá
apresentar um desempenho melhor devido ao aproveitamento da
tabela hash, para encontrar estas palavras.](https://image.slidesharecdn.com/apresenta-c3-a7-c3-a3o-130621144121-phpapp01/85/Algoritmo-de-Rabin-Karp-11-320.jpg)

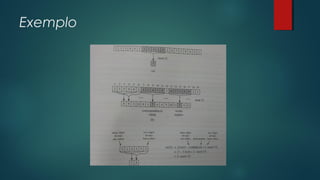
![Exemplo
Ao padrão P = 31415 corresponde o valor decimal p = 31.415
Seja T = 123141567, então:
T[1..5] = 12314 e t0 = 12314
T[2..6] = 23141 e t1 = 23141
T[3..7] = 31415 e t2 = 31415
T[4..8] = 14156 e t3 = 14156
T[5..9] = 41567 e t4 = 41567](https://image.slidesharecdn.com/apresenta-c3-a7-c3-a3o-130621144121-phpapp01/85/Algoritmo-de-Rabin-Karp-14-320.jpg)

![Trabalhos Similares/Futuros
Knuth-Morris-Pratt: considerado o algoritmo de “força bruta”, quando
ocorre uma diferença entre T[i] e P[j], evitar comparações
redundantes. Função de falha onde o pré-processamento em P
determina se seus prefixos aparecem como subsequência dele mesmo,
será definido também como o tamanho o maior prefixo de P[0..k] que
é sufixo de P[1..k].
É pré-calculado apenas o que pode ser reaproveitado da
comparação anterior, independente do próximo caracter .
Boyer-Moore: baseia-se na alta probabilidade de encontrar diferenças
em alfabetos grandes, por isso, P é comparado com T de trás para
frente, quando se encontra uma diferença em T[i], o padrão P dará um
salto à frente, considerando-se as comparações já realizadas](https://image.slidesharecdn.com/apresenta-c3-a7-c3-a3o-130621144121-phpapp01/85/Algoritmo-de-Rabin-Karp-16-320.jpg)




O documento descreve o algoritmo de Rabin-Karp para busca de padrões em strings. O algoritmo usa hashing para representar substrings do texto e a string padrão como valores numéricos, e compara esses valores em vez de comparar os caracteres diretamente. Isso reduz o número de comparações necessárias em média e no melhor caso para O(m+n). O documento também apresenta exemplos e compara o desempenho de Rabin-Karp com outros algoritmos de busca de padrão.





















![Aula de distribuição de probabilidade[1]](https://cdn.slidesharecdn.com/ss_thumbnails/auladedistribuiodeprobabilidade1-120719160104-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























