DP-SYMPTOM-IDENTIFIER: UMA ESTRATÉGIA
PARACLASSIFICAR SINTOMAS DE DEPRESSÃO
UTILIZANDO UM CONJUNTO DE DADOS
TEXTUAIS NA LÍNGUA PORTUGUESA
Autores: Vinicius Casani
Rafael Mantovani
Alinne Souza
Francisco Carlos Souza
STIL 2021 - Symposium in Information and Human Language Technology
Depressão no Mundoe no
Brasil
“A depressão afeta 4,4% da
população mundial, no Brasil a
parcela da população afetada é
de 5,8%”
● Sintomas:
○ Psíquicos
○ Fisiológicos
○ Comportamentais
● Períodos Temporais Fonte: Organização Mundial da Saúde
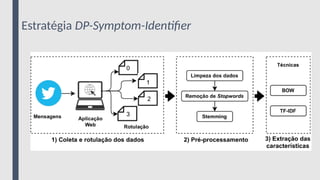
Etapa 1 -Coleta e rotulação dos dados
● Coleta de dados: Aplicação de Coleta
de Dados (ACD)
○ API do Twitter
○ Sentenças pré-selecionadas (200
exemplos)
Sentença Categoria
Eu quero morrer Comportamental
Não desejo sair de casa Comportamental
Tenho dificuldade para dormir Fisiológico
Estou sempre cansado Fisiológico
Me sinto inútil Psíquico
Sou infeliz Psíquico
8.
Etapa 1 -Coleta e rotulação dos dados
● Rotulação
○ Aplicação web
○ Auxílio de uma psicóloga
9.
Etapa 2 -Pré-processamento
● Base de dados de Treinamento
○ 2008 tweets de 1988 usuários
1. Limpeza dos dados
a. Caracteres minúsculos;
b. Números;
c. Emojis;
d. Pontuações;
e. Espaços desnecessários;
f. Citações e retweets;
2. Remoção de Stopwords
a. Palavras sem informações relevantes;
3. Stemming
a. Redução ao radical da palavra ou termo
10.
Etapa 3 -Extração de Características
● Term Frequency-Inverse Document
Frequency (TF-IDF)
○ Relevância de um termo em um
corpus
○ Mais de 10 mil atributos descritivos
○ Remoção dos atributos
correlacionados em mais de 95%
○ Overfiting
● Bag-of-Words (BoW)
○ Frequência de cada termo na base
○ 4650 atributos descritivos
○ Remoção dos atributos com
frequencia menor que 10 (340
atributos restantes)
11.
Avaliação da qualidadedo conjunto de dados
● Base de treinamento anteriormente criada
● Validação cruzada de 10 partições
● Algoritmos
○ Support Vector Machines (SVMs)
○ Naive Bayes (NB)
○ Multilayer Perceptron (MLP)
○ Random Forest (RF)
● Desempenho dos modelos mensurados por
meio da AUC
○ Representa a medida de separabilidade, ou
seja, mostra até que ponto o modelo
avaliado é capaz de separar corretamente
as classes (Flach et al. 2011).
● Resultados obtidos:
Algoritmo AUC sd
RF 0.935 0.015
SVM 0.927 0.013
MLP 0.900 0.009
NB 0.725 0.020
12.
Contribuições
● Estratégia DP-Symptom-Identifierpara coletar e analisar mensagens
compartilhadas em português no Twitter a fim de identificar um dos três tipos de
sintomas da depressão;
● Criação de uma base de dados em português, rotulada por uma psicóloga, a qual
pode ser utilizada por modelos de aprendizado de máquina no contexto de
problemas psicológicos;
13.
Trabalhos Futuros
● Expandiro conjunto de dados, adicionando mais tweets;
● Rotula-los usando as ferramentas desenvolvidas;
● Incrementar os experimentos com os algoritmos preditivos; e
● Expandir a coleta de dados para outras redes sociais.
Notas do Editor
#3
Psiquico, redução da capacidade de concentração, humor deprimido (sentimento de vazio), sentimento de culpa e inutilidade
Fisiológicos: sono perturbado (insonia ou hipersonia) e alteração de apetite
Comportamentais: retraimento social, ideação suicida, retardo ou agitação psicomotora
Considerada o mal do século pela OMS. A depressão atinge pessoas de todas as idades, classes sociais e nacionalidades, e é o principal motivo de incapacitação mental e fisica da população mundial
falar sobre o perido temporal indiicado pelo DSM
Um dos principais motivadores para que a depressão atinja números alarmantes é a desinformação, pois a maioria dos sintomas da depressão podem ser vistos como problemas rotineiros, como insonia, falta de apetite, introversão, e como os quadros depressivos são caracterizados quando existem os 3 tipos de sintomas por um determinado periodo de tempo, essa desinformação pode fazer com que as pessoas venham a ter conhecimento deste quadro quando a doença ja atingiu estágios mais avançados
#4 Falar da desinformação
somado a depressão a manipulação de textos e linguagem natural também são problemas, pois existem ambiguidades, figuras de linguagem e inconsistências..
No entanto, com o atual avanço da tecnologia e o desenvolvimento de areas ´ como Aprendizado de Maquina (AM) e Processamento de Linguagem Natural (PLN); ´ e uma grande quantidade e disponibilidade de dados gerados por redes sociais, foruns e paginas na Web, ´ e possivel extrair informacoes riquıssimas e relevantes de dados textuais.
#5 . Desta forma, em comparação aos trabalhos descritos,o principal diferencial neste artigo e a exploracão de uma analise considerando tres categorias de textos depressivos na l´ıngua portuguesa: sintomas psíquicos, comportamentais e fisiologicos. Segundo o DSM-5 [APA 2013], os sintomas ps íquicos e comportamentais sao mais relevantes para indicar um quadro depressivo do que os fisiologicos
#10 Term Frequency-Inverse Document Frequency (TF-IDF)
Relevância de um termo em um corpus
Mais de 10 mil atributos descritivos
Remoção dos atributos correlacionados em mais de 95%
Overfiting
#11 Os resultados iniciais obtidos sugerem que a estratégia elaborada é descritiva e efetiva, pois as caracter´ısticas textuais extraidas sao mapeadas corretamente para as categorias sintomaticas da depressao. Isso é visivelmente corroborado pelos valores médios ´ de AUC acima de 0.9, obtidos pelos algoritmos RF, SVM e MLP.