Baixar para ler offline


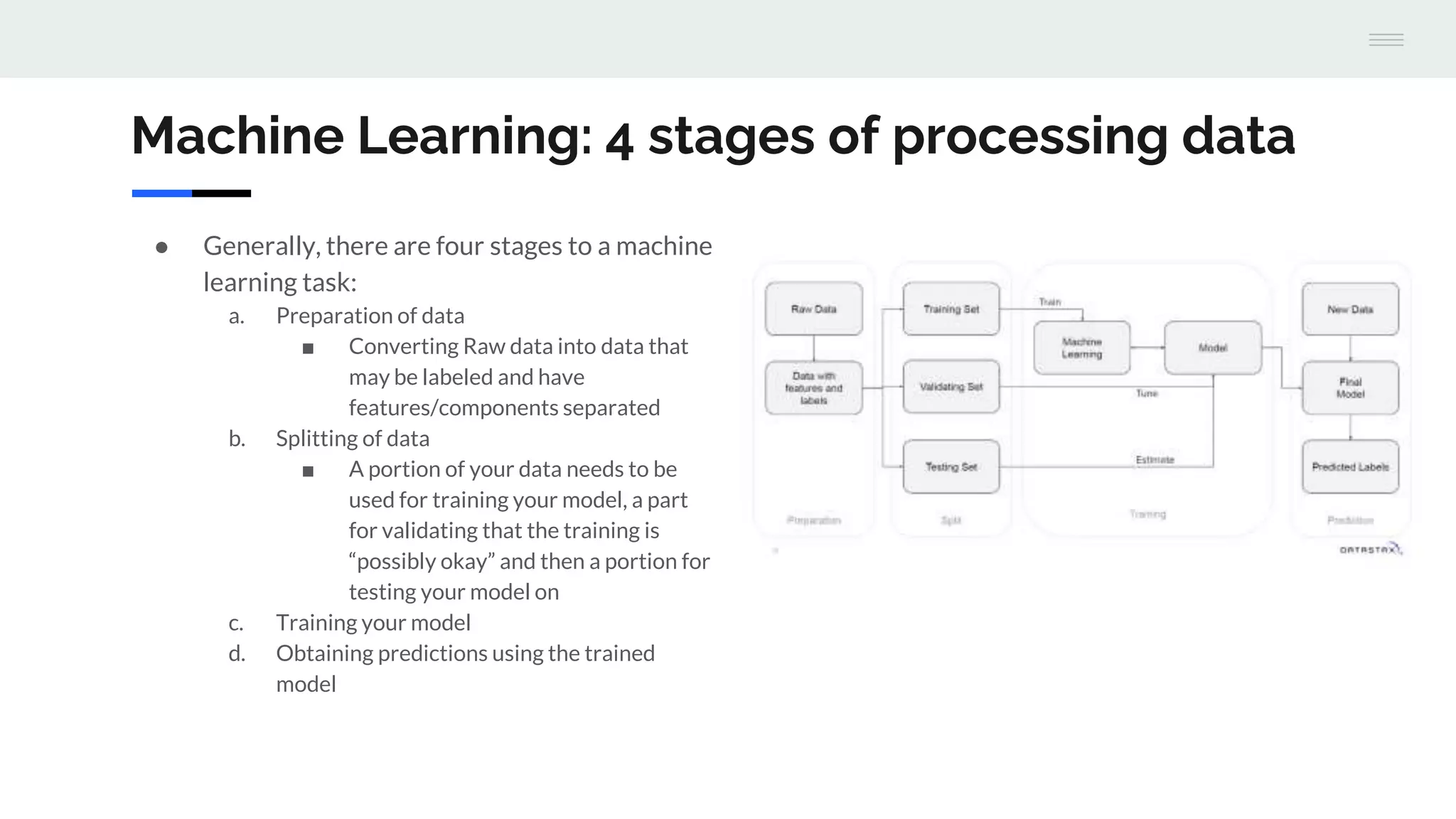

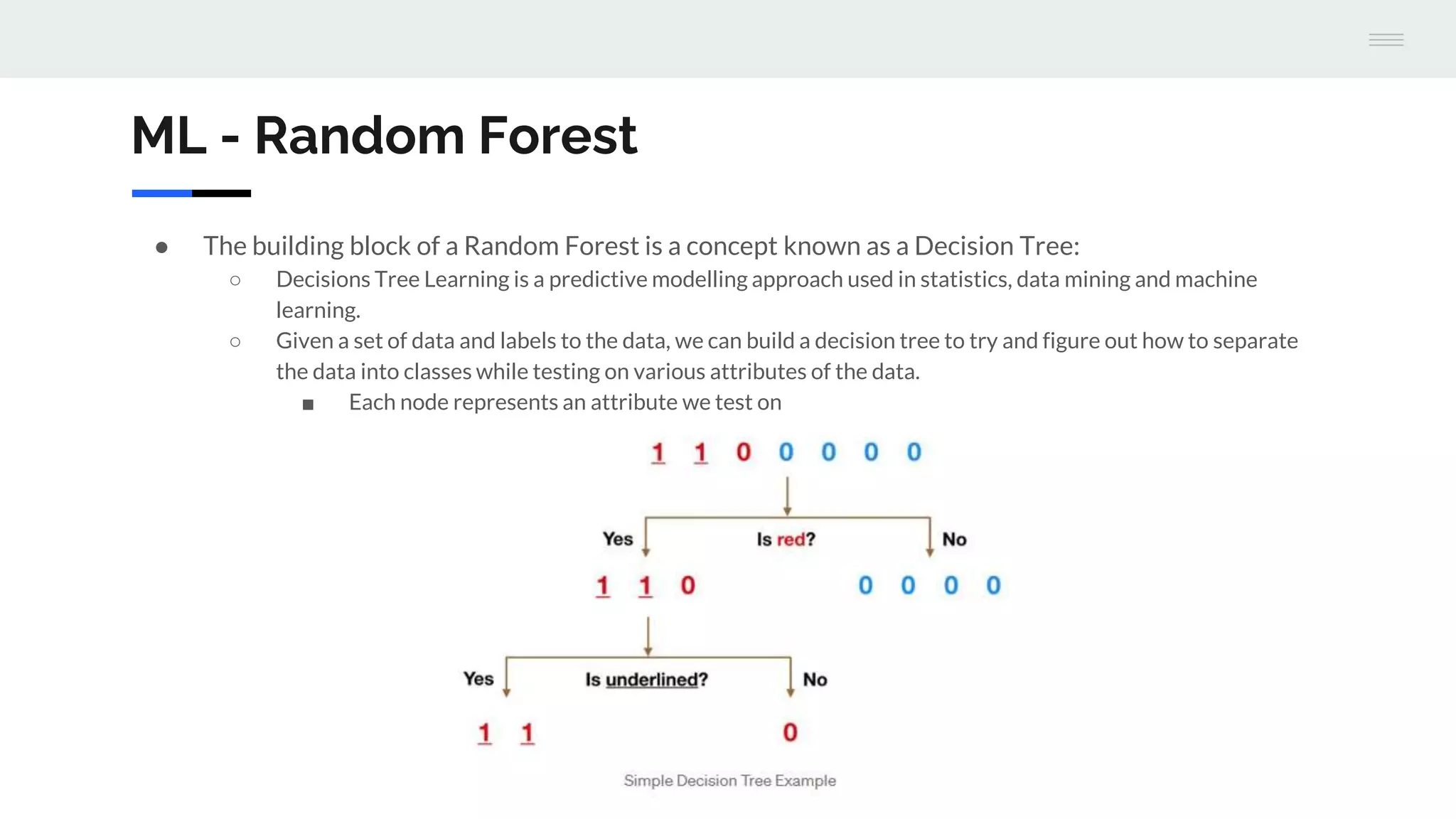

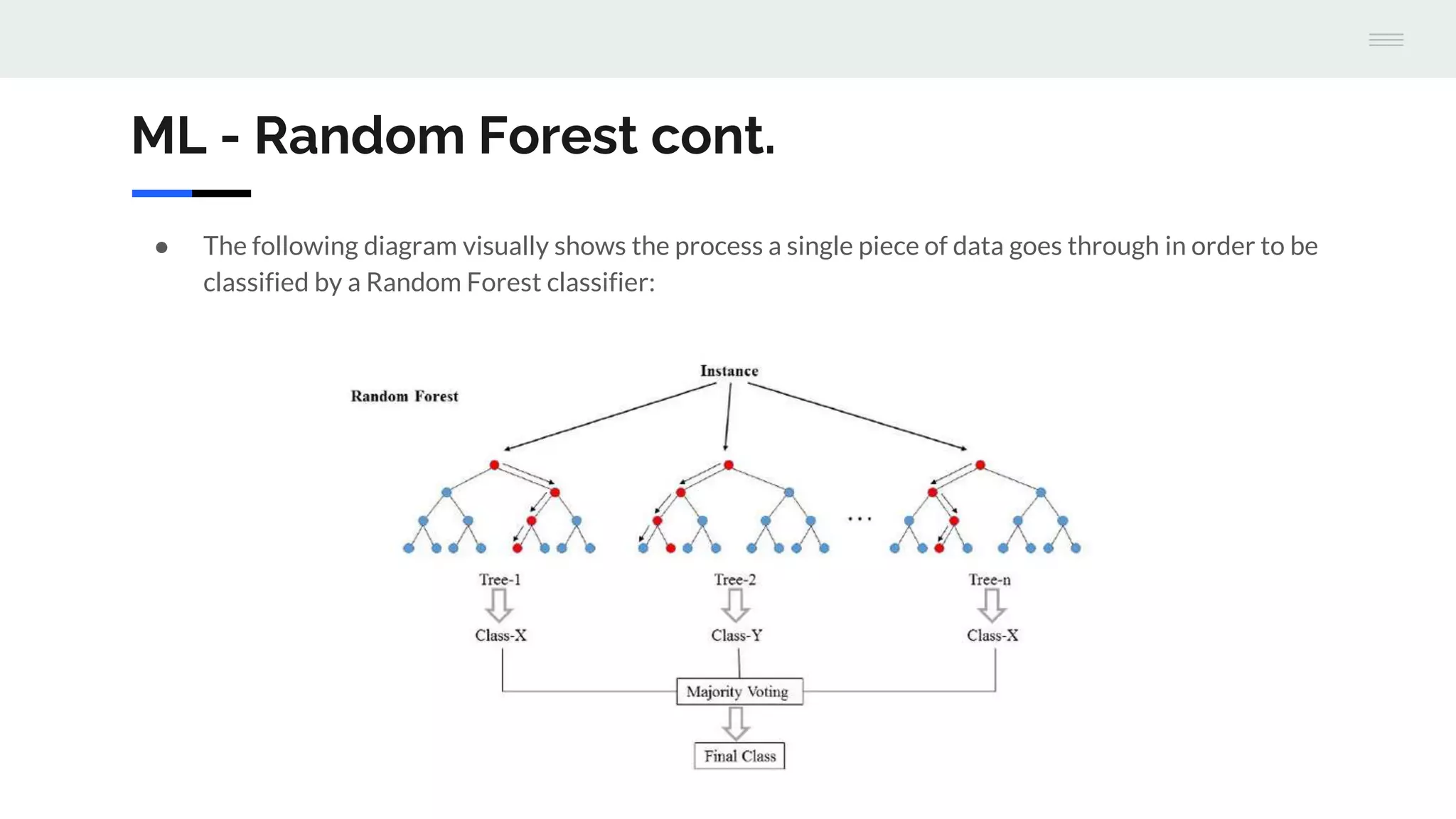
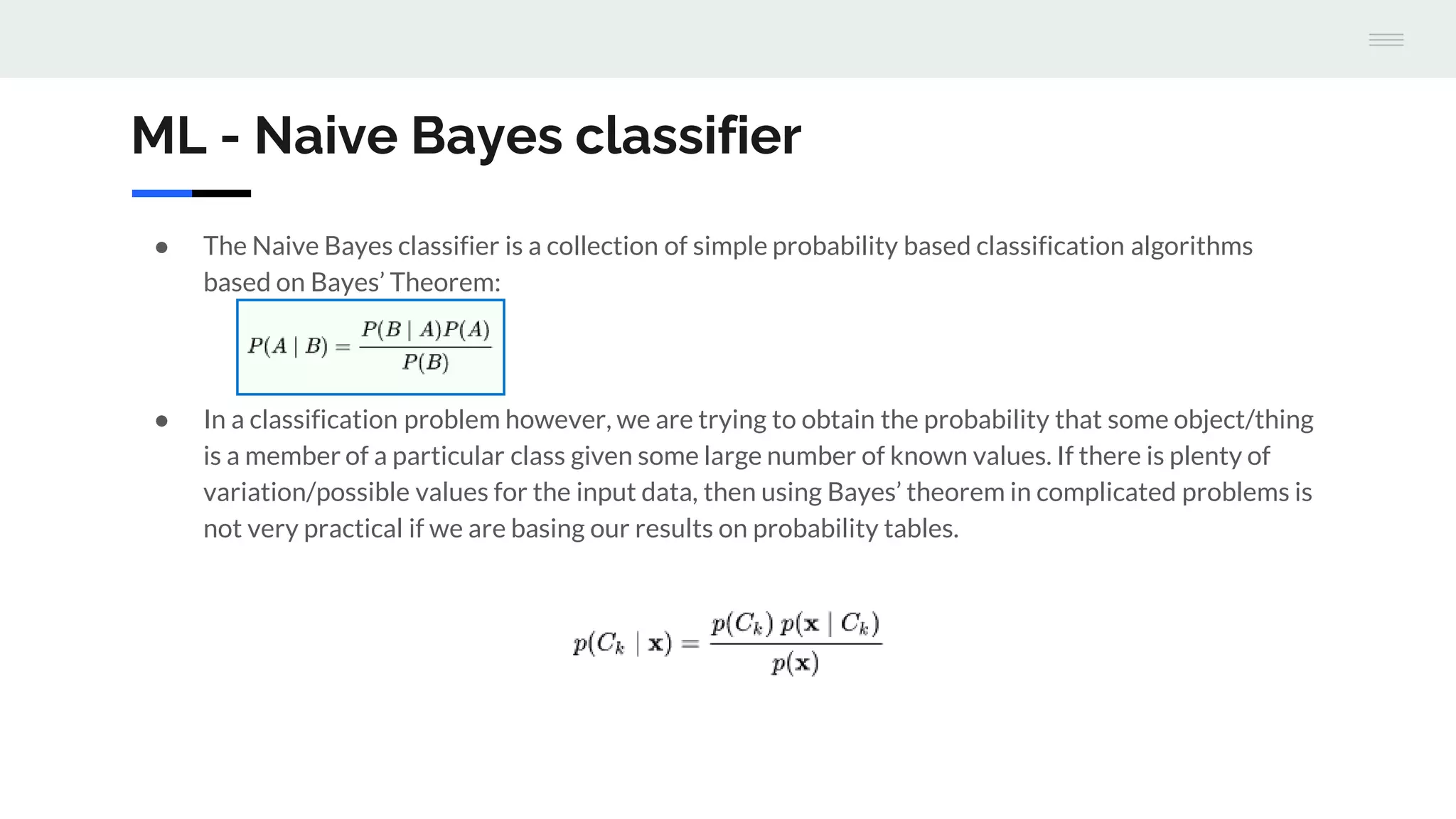








The document discusses the integration of machine learning with Apache Cassandra and Spark, highlighting the significance of machine learning as a subset of artificial intelligence and its various applications. It covers machine learning stages, the benefits of Cassandra for processing large datasets, and different machine learning algorithms such as random forests and naive Bayes classifiers. Additionally, it provides resources for further learning and a GitHub repository with examples and a demo project.























































































