DataEngConf SF16 - Spark SQL Workshop
•
3 gostaram•808 visualizações

Spark SQL for Java/Scala Developers. Workshop by Aaron Merlob, Galvanize. To hear about future conferences go to http://dataengconf.com

Recomendados
Recomendados
Mais conteúdo relacionado
Mais procurados
Mais procurados (20)
Destaque
Destaque (20)
Semelhante a DataEngConf SF16 - Spark SQL Workshop
Semelhante a DataEngConf SF16 - Spark SQL Workshop (20)
Mais de Hakka Labs
Mais de Hakka Labs (20)
Último
Último (20)
DataEngConf SF16 - Spark SQL Workshop
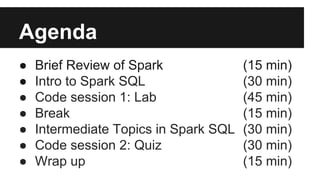
- 1. Agenda ● Brief Review of Spark (15 min) ● Intro to Spark SQL (30 min) ● Code session 1: Lab (45 min) ● Break (15 min) ● Intermediate Topics in Spark SQL (30 min) ● Code session 2: Quiz (30 min) ● Wrap up (15 min)
- 2. Spark Review By Aaron Merlob
- 3. Apache Spark ● Open-source cluster computing framework ● “Successor” to Hadoop MapReduce ● Supports Scala, Java, and Python! https://en.wikipedia.org/wiki/Apache_Spark
- 4. Spark Core + Libraries https://spark.apache.org
- 5. Resilient Distributed Dataset ● Distributed Collection ● Fault-tolerant ● Parallel operation - Partitioned ● Many data sources Implementation... RDD - Main Abstraction
- 7. Lazily Evaluated How Good Is Aaron’s Presentation? Immutable Lazily Evaluated Cachable Type Inferred
- 9. Type Inferred (Scala) Immutable Lazily Evaluated Cachable Type Inferred
- 11. Cache & Persist Transformed RDDs recomputed each action Store RDDs in memory using cache (or persist)
- 12. SparkContext. ● Your way to get data into/out of RDDs ● Given as ‘sc’ when you launch Spark shell. For example: sc.parallelize() SparkContext
- 13. Transformation vs. Action? val data = sc.parallelize(Seq( “Aaron Aaron”, “Aaron Brian”, “Charlie”, “” )) val words = data.flatMap(d => d.split(" ")) val result = words.map(word => (word, 1)). reduceByKey((v1, v2) => v1 + v2) result.filter( kv => kv._1.contains(“a”) ).count() result.filter{ case (k, v) => v > 2 }.count()
- 14. Transformation vs. Action? val data = sc.parallelize(Seq( “Aaron Aaron”, “Aaron Brian”, “Charlie”, “” )) val words = data.flatMap(d => d.split(" ")) val result = words.map(word => (word, 1)). reduceByKey((v1, v2) => v1 + v2) result.filter( kv => kv._1.contains(“a”) ).count() result.filter{ case (k, v) => v > 2 }.count()
- 15. Transformation vs. Action? val data = sc.parallelize(Seq( “Aaron Aaron”, “Aaron Brian”, “Charlie”, “” )) val words = data.flatMap(d => d.split(" ")) val result = words.map(word => (word, 1)). reduceByKey((v1, v2) => v1 + v2) result.filter( kv => kv._1.contains(“a”) ).count() result.filter{ case (k, v) => v > 2 }.count()
- 16. Transformation vs. Action? val data = sc.parallelize(Seq( “Aaron Aaron”, “Aaron Brian”, “Charlie”, “” )) val words = data.flatMap(d => d.split(" ")) val result = words.map(word => (word, 1)). reduceByKey((v1, v2) => v1 + v2) result.filter( kv => kv._1.contains(“a”) ).count() result.filter{ case (k, v) => v > 2 }.count()
- 17. Transformation vs. Action? val data = sc.parallelize(Seq( “Aaron Aaron”, “Aaron Brian”, “Charlie”, “” )) val words = data.flatMap(d => d.split(" ")) val result = words.map(word => (word, 1)). reduceByKey((v1, v2) => v1 + v2).cache() result.filter( kv => kv._1.contains(“a”) ).count() result.filter{ case (k, v) => v > 2 }.count()
- 18. Spark SQL By Aaron Merlob
- 19. Spark SQL RDDs with Schemas!
- 20. Spark SQL RDDs with Schemas! Schemas = Table Names + Column Names + Column Types = Metadata
- 21. Schemas ● Schema Pros ○ Enable column names instead of column positions ○ Queries using SQL (or DataFrame) syntax ○ Make your data more structured ● Schema Cons ○ ?? ○ ?? ○ ??
- 22. Schemas ● Schema Pros ○ Enable column names instead of column positions ○ Queries using SQL (or DataFrame) syntax ○ Make your data more structured ● Schema Cons ○ Make your data more structured ○ Reduce future flexibility (app is more fragile) ○ Y2K
- 23. HiveContext val sqlContext = new org.apache.spark.sql. hive.HiveContext(sc)
- 24. HiveContext val sqlContext = new org.apache.spark.sql. hive.HiveContext(sc) FYI - a less preferred alternative: org.apache.spark.sql.SQLContext
- 25. DataFrames Primary abstraction in Spark SQL Evolved from SchemaRDD Exposes functionality via SQL or DF API SQL for developer productivity (ETL, BI, etc) DF for data scientist productivity (R / Pandas)
- 26. Live Coding - Spark-Shell Maven Packages for CSV and Avro org.apache.hadoop:hadoop-aws:2.7.1 com.amazonaws:aws-java-sdk-s3:1.10.30 com.databricks:spark-csv_2.10:1.3.0 com.databricks:spark-avro_2.10:2.0.1 spark-shell --packages $SPARK_PKGS
- 27. Live Coding - Loading CSV val path = "AAPL.csv" val df = sqlContext.read. format("com.databricks.spark.csv"). option("header", "true"). option("inferSchema", "true"). load(path) df.registerTempTable("stocks")
- 28. Caching If I run a query twice, how many times will the data be read from disk?
- 29. Caching If I run a query twice, how many times will the data be read from disk? 1. RDDs are lazy. 2. Therefore the data will be read twice. 3. Unless you cache the RDD, All transformations in the RDD will execute on each action.
- 30. Caching Tables sqlContext.cacheTable("stocks") Particularly useful when using Spark SQL to explore data, and if your data is on S3. sqlContext.uncacheTable("stocks")
- 31. Caching in SQL SQL Command Speed `CACHE TABLE sales;` Eagerly `CACHE LAZY TABLE sales;` Lazily `UNCACHE TABLE sales;` Eagerly
- 32. Caching Comparison Caching Spark SQL DataFrames vs caching plain non-DataFrame RDDs ● RDDs cached at level of individual records ● DataFrames know more about the data. ● DataFrames are cached using an in-memory columnar format.
- 33. Caching Comparison What is the difference between these: (a) sqlContext.cacheTable("df_table") (b) df.cache (c) sqlContext.sql("CACHE TABLE df_table")
- 34. Lab 1 Spark SQL Workshop
- 35. Spark SQL, the Sequel By Aaron Merlob
- 36. Live Coding - Filetype ETL ● Read in a CSV ● Export as JSON or Parquet ● Read JSON
- 37. Live Coding - Common ● Show ● Sample ● Take ● First
- 38. Read Formats Format Read Parquet sqlContext.read.parquet(path) ORC sqlContext.read.orc(path) JSON sqlContext.read.json(path) CSV sqlContext.read.format(“com.databricks.spark.csv”).load(path)
- 39. Write Formats Format Write Parquet sqlContext.write.parquet(path) ORC sqlContext.write.orc(path) JSON sqlContext.write.json(path) CSV sqlContext.write.format(“com.databricks.spark.csv”).save(path)
- 40. Schema Inference Infer schema of JSON files: ● By default it scans the entire file. ● It finds the broadest type that will fit a field. ● This is an RDD operation so it happens fast. Infer schema of CSV files: ● CSV parser uses same logic as JSON parser.
- 41. User Defined Functions How do you apply a “UDF”? ● Import types (StringType, IntegerType, etc) ● Create UDF (in Scala) ● Apply the function (in SQL) Notes: ● UDFs can take single or multiple arguments ● Optional registerFunction arg2: ‘return type’
- 42. Live Coding - UDF ● Import types (StringType, IntegerType, etc) ● Create UDF (in Scala) ● Apply the function (in SQL)
- 43. Live Coding - Autocomplete Find all types available for SQL schemas +UDF Types and their meanings: StringType = String IntegerType = Int DoubleType = Double
- 44. Spark UI on port 4040