
Recomendados

Recomendados
Mais conteúdo relacionado
Mais de Eric Van Hensbergen
Mais de Eric Van Hensbergen (20)
Último
Último (20)
Push: A Dataflow Shell for Exascale Computing
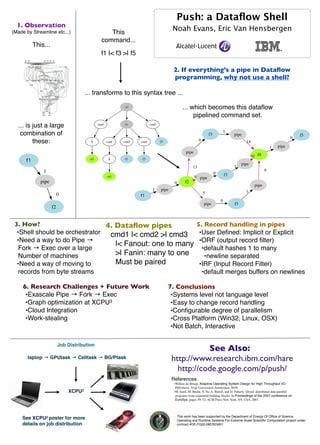
- 1. Push: a Dataflow Shell 1. Observation (Made by Streamline etc...) This Noah Evans, Eric Van Hensbergen command... This... f1 |< f3 >| f5 2. If everything’s a pipe in Dataflow programming, why not use a shell? ... transforms to this syntax tree ... >| ... which becomes this dataflow pipelined command set. ... is just a large cmd |< cmd 1 combination of f3 pipe f5 0 these: $ cmd cmd cmd f5 0 14 1 pipe pipe 10 f4 f1 irf $ f1 f3 pipe 13 1 1 6 0 f3 orf 9 pipe pipe 0 f2 pipe 1 pipe 1 0 5 f1 0 pipe f3 f2 3. How? 4. Dataflow pipes 5. Record handling in pipes •Shell should be orchestrator cmd1 |< cmd2 >| cmd3 •User Defined: Implicit or Explicit •Need a way to do Pipe → •ORF (output record filter) ! |< Fanout: one to many Fork → Exec over a large •default hashes 1 to many Number of machines ! >| Fanin: many to one •newline separated •Need a way of moving to ! Must be paired •IRF (Input Record Filter) records from byte streams •default merges buffers on newlines 6. Research Challenges + Future Work 7. Conclusions •Exascale Pipe → Fork → Exec •Systems level not language level •Graph optimization at XCPU3 •Easy to change record handling •Cloud Integration •Configurable degree of parallelism •Work-stealing •Cross Platform (Win32, Linux, OSX) •Not Batch, Interactive Job Distribution See Also: laptop → GPUtask → Celltask → BG/Ptask http://www.research.ibm.com/hare http://code.google.com/p/push/ References •Willem de Bruijn. Adaptive Operating System Design for High Throughput I/O. PhD thesis, Vrije Universiteit Amsterdam, 2010. XCPU3 •M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: distributed data-parallel programs from sequential building blocks. In Proceedings of the 2007 conference on EuroSys, pages 59–72. ACM Press New York, NY, USA, 2007. This work has been supported by the Department of Energy Of Office of Science See XCPU3 poster for more Operating and Runtime Systems For Extreme Scale Scientific Computation project under details on job distribution contract #DE-FG02-08ER25851