Data modelling interview question
•
5 gostaram•583 visualizações

Data Modelling One best Collection I used For interiview Questions

Recomendados
Mais conteúdo relacionado
Mais procurados
Mais procurados (20)
Semelhante a Data modelling interview question
Semelhante a Data modelling interview question (20)
Mais de Sandeep Sharma IIMK Smart City,IoT,Bigdata,Cloud,BI,DW
Mais de Sandeep Sharma IIMK Smart City,IoT,Bigdata,Cloud,BI,DW (20)
Último
Último (20)
Data modelling interview question
- 3. Question #1) What do you understand by Data Modelling?
- 4. Ans) Data Modelling is the diagrammatic representation showing how the entities are related to each other. It is the initial step towards database design. We first create the conceptual model, then logical model and finally move to the physical model. Generally, the data models are created in data analysis & design phase of software development life cycle. Question #2) Explain your understanding of different data models? Ans) There are three types of data models – conceptual, logical and physical. The level of complexity and detail increases from conceptual to logical to a physical data model. The conceptual model shows a very basic high level of design while the physical data model shows a very detailed view of design. The conceptual model will be just portraying entity names and entity relationships. Figure 1 shown in the later part of this article depicts a conceptual model. The logical model will be showing up entity names, entity relationships, attributes, primary keys and foreign keys in each entity. Figure 2 shown inside question#4 in this article depicts a logical model. The physical data model will be showing primary keys, foreign keys, table names, column names and column data types. This view actually elaborates how the model will be actually implemented in the database. Question #3) Throw some light on your experience in Data Modelling with respect to projects you have worked on till date? Note: This was the very first question in one of my Data Modelling interviews. So, before you step into the interview discussion, you should have a very clear picture of how data modeling fits into the assignments you have worked upon. Ans) I have worked on a project for a health insurance provider company where we have interfaces build in Informatica that transforms and process the data fetched from Facets database and sends out useful information to vendors. Note: Facets is an end to end solution to manage all the information for health care industry. The facets database in my project was created with SQL server 2012. We had different entities that were linked together. These entities were subscriber, member, healthcare provider, claim, bill, enrollment, group, eligibility, plan/product, commission, capitation, etc. Below is the conceptual data model showing how the project looked like on a high-level Figure 1:
- 5. Each of the data entities has their own data attributes. For example, a data attribute of the provider will be provider identification number, few data attributes of the membership will be subscriber ID, member ID, one of the data attribute of claim will claim ID, each healthcare product or plan will be having a unique product ID and so on. Question #4) What are the different design schemas in Data Modelling? Explain with the example? Ans) There are two different kinds of schemas in data modeling Star Schema Snowflake Schema Now I will be explaining each of these schemas one by one. The simplest of the schemas is star schema where we have a fact table in the center which references multiple dimension tables around it. All the dimension tables are connected to the fact table. The primary key in all dimension tables acts as a foreign key in the fact table. The ER diagram (see Figure 2) of this schema resembles the shape of a star and that is why this schema is named as a star schema. Figure 2: The star schema is quite simple, flexible and it is in de-normalized form. In a snowflake schema, the level of normalization increases. The fact table here remains the same as in star schema. However, the dimension tables are normalized. Due to several layers of dimension tables, it looks like a snowflake and thus it is named as snowflake schema. Figure 3:
- 6. Question #5) Which scheme did you use in your project & why? Question #6) Which schema is better – star or snowflake? Ans (Combined for Q# 5&6): The choice of a schema always depends upon the project requirements & scenarios. Since star schema is in de-normalized form, you require fewer joins for a query. The query is simple and runs faster in a star schema. Coming to the snowflake schema, since it is in normalized form, it will require a number of joins as compared to a star schema, the query will be complex and execution will be slower than star schema. Another significant difference between these two schemas is that snowflake schema does not contain redundant data and thus it is easy to maintain. On the contrary, star schema has a high level of redundancy and thus it is difficult to maintain. Now, which one to choose for your project? If the purpose of your project is to do more of dimension analysis, you should go for snowflake schema. For example, if you need to find out that “how many subscribers are tied to a particular plan are currently active?” – go with snowflake model. If the purpose of your project is to do more of metrics analysis, you should go with a star schema. For example, if you need to find out that “what is the claim amount paid to a particular subscriber?” – go with a star schema. In my project, we used snowflake schema because we had to do analysis across several dimensions and generate summary reports for the business. Another reason for using snowflake schema was it is less memory consumption. Question#7) What do you understand by dimension and attribute? Ans) Dimensions represent qualitative data. For example– plan, product, class are all dimensions. A dimension table contains descriptive or textual attributes. For example, product category & product name are the attributes of product dimension. Question #8) What is a fact & a fact table? Ans) Facts represent quantitative data. For example – net amount due is a fact. A fact table contains numerical data and foreign keys from related dimensional tables. An example of the fact table can be seen from Figure 2 shown above. Question #9) What are the different types of dimensions you have come across? Explain each of them in detail with an example? Ans) There are typically five types of dimensions. 1) Conformed dimensions: A Dimension that is utilized as a part of different areas is called as conformed dimension. It might be utilized with different fact tables in a single
- 7. database or over numerous data marts/warehouses. For example, if subscriber dimension is connected to two fact tables – billing and claim then the subscriber dimension would be treated as conformed dimension. 2) Junk Dimension: It is a dimension table comprising of attributes that don’t have a place in the fact table or in any of the current dimension tables. Generally, these are the properties like flags or indicators. For example, it can be member eligibility flag set as ‘Y’ or ‘N’ or any other indicator set as true/false, any specific comments, etc. if we keep all such indicator attributes in the fact table then its size gets increased. So, we combine all such attributes and put in a single dimension table called as junk dimension having unique junk IDs with a possible combination of all the indicator values. 3) Role Playing Dimension: These are the dimensions which are utilized for multiple purposes in the same database. For example, a date dimension can be used for “Date of Claim”, “Billing date” or “Plan Term date”. So, such a dimension will be called as Role playing dimension. The primary key of Date dimension will be associated with multiple foreign keys in the fact table. 4) Slowly Changing Dimension (SCD): These are most important amongst all the dimensions. These are the dimensions where attribute values vary with time. Below are the varies types of SCDs Type-0: These are the dimensions where attribute value remains steady with time. For example, Subscriber’s DOB is a type-0 SCD because it will always remain the same irrespective of the time. Type-1: These are the dimensions where previous value of the attribute is replaced by the current value. No history is maintained in Type-1 dimension. For example, Subscriber’s address (where the business requires to keep the only current address of subscriber) can be a Type-1 dimension. Type-2: These are the dimensions where unlimited history is preserved. For example,Subscriber’s address (where the business requires to keep a record of all the previous addresses of the subscriber). In this case, multiple rows for a subscriber will be inserted in the table with his/her different addresses. There will be some column(s) that will identify the current address. For example, ‘start date’ and ‘End date’. The row where ‘End date’ value will be blank would contain subscriber’s current address and all other rows will be having previous addresses of the subscriber. Type-3: These are the type of dimensions where limited history is preserved. And we use an additional column to maintain the history. For example, Subscriber’s address (where the business requires to keep a record of current & just one previous address). In this case, we can dissolve the ‘address’ column into two different columns – ‘current address’ and ‘previous address’. So, instead of having multiple rows, we will be having just one row showing current as well as the previous address of the subscriber. Type-4: In this type of dimension, the historical data is preserved in a separate table. The main dimension table holds only the current data. For example, the main dimension table will have only one row per subscriber holding its current address. All other previous addresses of the subscriber will be kept in the separate history table. This type of dimension is hardly ever used. 5) Degenerated Dimension: A degenerated dimension is a dimension which is not a fact but presents in the fact table as a primary key. It does not have its own dimension table. We can also call it as a single attribute dimension table. But, instead of keeping it separately in a dimension table and putting an additional join, we put this attribute in the fact table directly as a key. Since it does not have its own dimension table, it can never act a foreign key in fact table. Question#10) Give your idea regarding factless fact? And why do we use it? Ans) Factless fact table is a fact table that contains no fact measure in it. It has only the dimension keys in it.
- 8. At times, certain situations may arise in the business where you need to have factless fact table. For example, suppose you are maintaining an employee attendance record system, you can have a factless fact table having three keys. Employee_ID Department_ID Time_ID You can see that the above table does not contain any measure. Now if you want to answer below question, you can do easily using the above single factless fact table rather than having two separate fact tables: “How many employees of a particular department were present on a particular day?” So, factless fact table offers flexibility to the design. Question #11) Distinguish between OLTP and OLAP? Ans) OLTP stands for Online Transaction Processing system & OLAP stands for Online Analytical processing system. OLTP maintains the transactional data of the business & is highly normalized generally. On the contrary, OLAP is for analysis and reporting purpose & it is in de-normalized form. This difference between OLAP and OLTP also gives you the way to choosing the design of schema. If your system is OLTP, you should go with star schema design and if your system is OLAP, you should go with snowflake schema. Question #12) What do you understand by data mart? Ans) Data marts are for the most part intended for a solitary branch of business. They are designed for the individual departments. For example, I used to work for a health insurance provider company which had different departments in it like Finance, Reporting, Sales and so forth. We had a data warehouse that was holding the information pertaining to all these departments and then we have few data marts built on top of this data warehouse. These DataMart were specific to each department. In simple words, you can say that a DataMart is a subset of a data warehouse. Question #13) What are the different types of measures? Ans) We have three types of measures Non- additive measures Semi-additive measures Additive measures Non-additive measures are the ones on top of which no aggregation function can be applied. For example, a ratio or a percentage column; a flag or an indicator column present in fact table holding values like Y/N, etc. is a non-additive measure. Semi-additive measures are the ones on top of which some (but not all) aggregation functions can be applied. Example – fee rate or account balance. Additive measures are the ones on top of which all aggregation functions cab be applied. Example- units purchased. Question # 14) What is a Surrogate key? How is it different from a primary key? Ans) Surrogate key is a unique identifier or a system generated sequence number key that can act as a primary key. It can be a column or a combination of columns. Unlike a primary key, it is not picked up from the existing application data fields.
- 9. Question # 15) Is this true that all databases should be in 3NF? Ans) It is not mandatory for a database to be in 3NF. However, if your purpose is an easy maintenance of data, less redundancy, and efficient access then you should go with a de-normalized database. Question # 16) Have you ever came across the scenario of recursive relationships? If yes, how did you handle it? Ans) A recursive relationship occurs in the case where an entity is related to itself. Yes, I have come across such scenario. Talking about health care domain, it is a possibility that a health care provider (say, a doctor) is a patient to any other health care provider. Because, if the doctor himself falls ill and needs a surgery, he will have to visit some other doctor for getting the surgical treatment. So, in this case, the entity – health care provider is related to itself. A foreign key of the health insurance provider’s number will have to present in each member’s (patient) record. Question # 17) List out few common mistakes encountered during Data Modelling? Ans) Below are the few common mistakes encountered during Data Modelling Building massive data models: Large data models are like to have more design faults. Try to restrict your data model to not more than 200 tables. Lack of purpose: If you do not know that what is your business solution is intended for, you might come up with an incorrect data model. So having clarity on the business purpose is very important to come up with a right data model. Inappropriate use of surrogate keys: Surrogate key should not be used unnecessarily. Use surrogate key only when the natural key cannot serve the purpose of a primary key. Unnecessary de-normalization: Don’t denormalize until and unless you have a solid & clear business reason to do so because de-normalization creates redundant data which is difficult to maintain. Question #18) What is the number of child tables that can be created out from a single parent table? Ans) The number of child tables that can be created that can be created out of the single parent table is equal to the number of fields/columns in the parent table that are non-keys. Question #19) Employee health details are hidden from his employer by the health care provider. Which level of data hiding is this? Conceptual, physical or external? Ans) This is the scenario of an external level of data hiding. Question #20) What is the form of fact table & dimension table? Ans) Generally, the fact table is in normalized form and dimension table is in de- normalized form. Question # 21) What particulars you would need to come up with a conceptual model in a health care domain project? Ans) For a health care project, below details would suffice the requirement to design a basic conceptual model Different categories of health care plan and products. Type of subscription (group or individual). Set of health care providers. Claim and billing process overview. Question # 22) Tricky one: If a unique constraint is applied to a column then will it throw an error if you try to insert two nulls into it? Ans) No, it will not throw any error in this case because a null value is unequal to another null value. So, more than one null will be inserted in the column without any error. Question # 23) Can you quote an example of sub-type and super-type entity? Ans) Yes, let’s say we have these different entities – vehicle, car, bike, Economy car, family car, sports car. Here, a vehicle is a super type entity. Car and bike are its sub- type entities. Furthermore, economy car, sports car, and family car are sub-type entities
- 10. of its super-type entity- car. A super-type entity is the one which is at a higher level. Sub-type entities are ones which are grouped together on the basis of certain characteristics. For example, all bikes are two-wheelers and all cars are four wheelers. And since both are vehicles, so their super-type entity is ‘vehicle’. A super-type entity is the one which is at a higher level. Sub-type entities are ones which are grouped together on the basis of certain characteristic s. For example, all bikes are two-wheelers and all cars are four wheelers. And since both are vehicles, so their super-type entity is ‘vehicle’. Question # 24) What is the significance of metadata? Ans) Metadata is data about data. It tells you that what kind of data is actually stored in the system, what is its purpose and for whom it is intended for. To Summarize: Practical understanding of Data Modelling concept and how it fits into the assignments done by you is much needed to crack a data modeling interview. Most commonly asked topics in Data Modelling interview are – different types of data models, types of schemas, types of dimensions and normalization. Be well prepared for scenario based questions as well. I would suggest that whenever you are answering a question to the interviewer, it’s better that you explain the idea through an example. This would show that you have actually worked into that area and you understand the core of the concept very well.
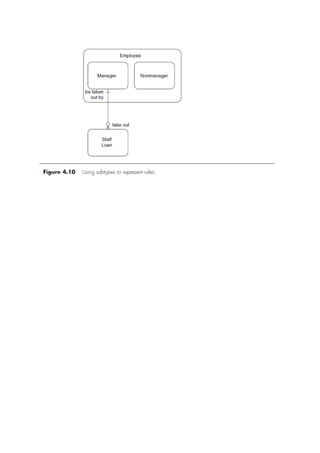
- 12. LookupFor ID , VsRefrence What is a “Lookup Relationship”? Up to 25 allowed for object Parent is not a required field. No impact on a security and access. No impact on deletion. Can be multiple layersdeep. Lookup field is not required. What is “Master-Detail Relationship”?
- 13. Master Detail relationship is the Parent child relationship. In which Master representsParent and detail representsChild. IfParent is deleted then Child also getsdeleted. Rollup summaryfields can only be created on Master records which will calculate the SUM, AVG, MIN of the Child records. Up to 2 allowed to object. Parent field on child is required. Access to parent determinesaccess to children. Deletingparent automaticallydeleteschild. A child of one master detail relationship cannot be the parent of another. Lookup field on page layout is required. ---------------------------------------------- Actual InterviewQuestions Question 1a: Sequence SQL query is executed. Answer: SQL Query is made into prase tree by parser which Then Execute Each of these Datasets in Temp table using parse tree of SQL. Question 1b: Sequence in which SQL Query keywords is executed internally : Query Select from Where Having Group by Answer: Select From [table name] Where [restrict rows hence optimizes] Then Group By [ To aggregate ] Having to filter on aggregation (sum(salary) > 10,000); Question 2:What are Types of clustering in data modelling Dominance Grouping Abstraction Grouping Continous Grouping Relationship grouping
- 14. Question 3: What for Group insurance Policy What type of clustering used Horizontal or Vertical? My : Since group ploicy is generally same for all in department it may horizontal Grouping. But Since if implementation is dependent on designation or levels in organisation So In that case it is vertical My anwer is wrong based Question 4:What is surrogate Key how its used. ? My Answer: Key made up by combination of Foreign Keys from Primary Tables by combination of many such ids jointly. Surrogate key reduces time required to fetch records from database as only ID fetched and matched which are alphanumeric is very fast compared with join o whole ccolumn Question 5: We are developing one claim portal. Claims are fetched using surrogate key [from many tables like [policy details, insurance details, Other details, etc...]. Problem: if claim submitted is not successful then surrogate key lost What might be problem how can we solved it. Answer Each time claim is submitted then maintain flag to show claim was sussesfull/not sucess Flag is Stored separate in table with claim details. Question 6: Filled Claim of previous data. Question 7 : Question What are benefit driven of VLDB how dos it help? Answer : Very Large Database VLDB optimizes the Data Fetching due to query can be achieved by querying subset of partition maintained by partition
- 15. Question 8: MAster table Child table 2 Child table 1 Is This Star Schema or Snowflake schema. Answer : Master and two slave under comes into SNOWFLAKE SCHEMA. All Oracle Datwarehouse fact table is 3NF , £rd Normal form say: All non prime atttribte dependent on prime atributs and no Transitive Dependency. Here MAster and Child relation exists on in snowflake schema where each dimension od futer broken into child dimenssion. Question 10. What is normalized Form? Answer: 1st normal for : no multivalued attributes 2nd Normal form: All non prome attributes Dependent on Prime attributes. 3rd normal form which was 2nd Normal form+ No Trasitive dependency. Question 11: Did you work with Health Insurance companies?. Answer: world's largst Blue cross blue shield BCBS , awe terms like term insurance, ., Anthem... Question 12 :Did you knw healthcase insurance.. Question 13: How well you know life insurance ? p Answer: I did studied for LOMA, Certified on statisticla I have decent eposure.. to heath care acturial science, Claim processing, Machines needs more intellignce., under writing. As avg dtd. Also I Certified on 5 ETL Datahouse and 5 BI Tools, certified om Many of my presentation like SQL, 1. My These Data modelling presentation are viewed 17,000 view per year since 2012. https://www.slideshare.net/SandeepSharma65/oracle-complete-interview-questions 2. https://www.slideshare.net/SandeepSharma65/oracle-security-ols-vs-vpd 3. data modelling semantic layer on BI data modelling https://www.slideshare.net/SandeepSharma65/data-modelling-qlikview-45572297 4. Casandra data modelling https://www.slideshare.net/SandeepSharma65/cassandra-data-modelling-best-practices-45571733 5. https://www.slideshare.net/SandeepSharma65/cassandra-data-modelling-best-practices Attribute Generalization Resulting from
- 16. Entity Generalization Surrogate KeyPerformance The two arguments most commonly advanced against surrogate keys are programming complexity and performance. Frequently, we need to access a reference table to find the corresponding natural identifier. This situation
- 17. occurs often enough that programmers are frequently opponents of surrogate keys. However, performance is not usually a problem if the reference tables are small and can reside in primary storage. The more common performance-related issue with surrogate keys is the need for additional access mechanisms such as indexes to support access on both the surrogate and natural keys. In databases handling high volumes of new data, problems may also arise with contention for “next available numbers.” However, many DBMSs provide mechanisms specifically to generate unique key values efficiently Self Refrencing Relationship SELECT * /*This is the outer query part */ FROM Employee Emp1 WHERE (N-1) = ( /* Subquery starts here */ SELECT COUNT(DISTINCT(Emp2.Salary)) FROM Employee Emp2 WHERE Emp2.Salary > Emp1.Salary) SELECT id, COUNT(id) FROM table1 GROUP BY id HAVING COUNT(id)>1;