29 SETTEMBRE 2021 – Aula Magna – Corso Duca degli Abruzzi, 24 – Politecnico di Torino
Ricerca, trasferimento tecnologico e supporto alle aziende sui temi fondamentali dei Big Data, Intelligenza Artificiale, la robotica e la rivoluzione digitale
Statistics notes ,it includes mean to index numbers
DATI, AI E ROBOTICA @POLITO
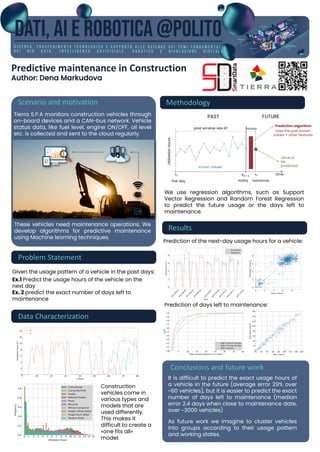
1. Predictive maintenance in Construction
Author: Dena Markudova
Methodology
Scenario and motivation
Problem Statement
Tierra S.P.A monitors construction vehicles through
on-board devices and a CAN-bus network. Vehicle
status data, like fuel level, engine ON/OFF, oil level
etc. is collected and sent to the cloud regularly.
Testo (Font Poppins 40)
Given the usage pattern of a vehicle in the past days:
Ex.1 Predict the usage hours of the vehicle on the
next day
Ex. 2 predict the exact number of days left to
maintenance
Construction
vehicles come in
various types and
models that are
used differently.
This makes it
difficult to create a
«one fits all»
model.
These vehicles need maintenance operations. We
develop algorithms for predictive maintenance
using Machine learning techniques.
Data Characterization
We use regression algorithms, such as Support
Vector Regression and Random Forest Regression
to predict the future usage or the days left to
maintenance.
Results
Prediction of the next-day usage hours for a vehicle:
Conclusions and future work
It is difficult to predict the exact usage hours of
a vehicle in the future (average error 29% over
~60 vehicles), but it is easier to predict the exact
number of days left to maintenance (median
error 2.4 days when close to maintenance date,
over ~3000 vehicles)
As future work we imagine to cluster vehicles
into groups according to their usage pattern
and working states.
Prediction of days left to maintenance:
2. Reconstruction of epidemic CASCADES with generative
Neural networks
Authors: Indaco Biazzo, Fabio Mazza, Luca Dall’Asta, Alfredo Braunstein
RESULTS
Conclusions and future work
Motivation and background
Materials and methods
Discrete-state stochastic compartmental models
have been traditionally used to model infectious
diseases, and provide a simple framework for a
variety of spreading processes in social and
technological systems.
The COVID-19 pandemic has highlighted the need to
track epidemics on an individual level, and has
pushed for the large scale collection of contact data
in order to contain the spread. The inference at the
individual level, however, becomes much more
challenging as the number of possible epidemic
realizations increases exponentially with the number
of individuals or the duration.
Different strategies have been devised to efficiently
solve this problem from statistical inference.
Algorithms based on Belief Propagation (BP) show
good results, but they may experience convergence
issues on some dense and very structured contact
networks.
We show that ANNs are able to learn to generate
epidemic cascades according to the epidemic
model, which are compatible with the
observations or evidence; if the model's
parameters are unknown, they are also capable
of inferring them during the overall learning
process.
The approach is flexible enough to be easily
used on various inference problems and with
different propagation models.
We apply the ANN method to two inference
problems:
➢ the patient zero, where we have observed the
final state and want to find the source of the
epidemic
In the Bayesian formulation of the inference, we
have a posterior distribution from which we need
to compute marginal probabilities.
We use Autoregressive Neural Networks (ANNs),
which are able to efficiently sample from a
probability distribution, and have already been
used for text or image generation tasks.
We train our ANNs by generating samples of
epidemic cascades and then evaluating the
(reversed) Kullback-Leibler divergence, from
which we have derived a loss function.
When this procedure ends, we are able to
generate samples from , easily computing
marginals.
time
Inference
➢ the risk inference problem, where we want to
find who is at most risk of being infected, given
some sparse observations on the ongoing
epidemic
We are also able to
use the Bayesian
framework to infer
the parameters of
the epidemic
3. DivExplorer - Explaining subgroups
Given a single prediction, we explain the reasons
behind it
Explainable AI and Fairness
Eliana Pastor, Elena Baralis, Luca de Alfaro
Try it aT DIVEXPLORER.ORG!
ON THE NEED OF XAI
EXPLAINING MODEL BEHAVIOR
Black box models ➙ hide from users the
reasons behind predictions
Explaining classifier behavior
● LACE - Individual prediction
● DivExplorer - Data subgroup
Model agnostic ➙ applicable for a generic classifier
POLITO POLITO UCSC
DEBUG &
ERROR ANALYSIS
FAIRNESS MODEL
VALIDATION
TRUST
Why Explainable AI?
LACE - EXPLAINING INDIVIDUAL PREDICTIONS
● Quantitative insight ➙ prediction difference
● Qualitative insight ➙ local rules
It can reveal if model predictions are based on
protected attributes
0 0.05 0.1 0.15 0.2
sex=Female
workclass=Private
education=Bachelors
race=White
marital-status=Never-Married
occupation=White-collar
relation=Not-in-family
capitalGain=low
capitalLoss=low
hourWeek<=39.5
age=34-41
LocalRule
dataset=adult model=NB
p(class=“≤50K”|x)=0.96 true class=“≤50K”
△ - target class= “≤50K”
{sex=Female, workclass=Private, capital-gain=low} ➝ class= “≤50K”
Evaluation typically considers overall performance
However, the model behavior can differ across
data subgroups
Dataset
FPR=0.2
→FPR=0.8
Higher FPR
Lower FPR
DivExplorer
● Automatic identification of subgroups with
divergent behavior
age<35,
income<30
● Local contribution
to divergence
● Global contribution
to divergence
4. -Anonymity & -MON:
how to protect users’ privacy
z α
Authors: Thomas Favale, Nikhil Jha
The practice
Is it feasible?
Conclusions and future work
Motivation and background
The theory behind
• With the advent of big data and the birth of the data
markets that sell personal information, individuals'
privacy is of utmost importance.
• The classical response is anonymization, i.e., sanitizing
the information that can directly or indirectly allow users'
re-identification.
• Starting from what we learned from -anonymity, we
have created a high-performance tool that
implements it: -MON
• Supports -anonymity to hide private
quasi-identifiers with custom and ∆T
• Flexible set of anonymization policies
• Scalable and deployable in high-speed links
• Support multiple legacy applications with different
anonymization requirements
z
α
z
z
• The most famous anonymization paradigm is
k-anonymity, which aims at assuring that every user in
the dataset has other k-1 users with identical quasi-
identifying attributes, by generalizing/suppressing the data
• Classic anonymization paradigms suffer the stream
scenario, hence the need of a zero-delay anonymization
technique
• ⍺-MON with a single core can sustain 10 Gbit/s with
a single consumer
• The performance is reduced when α-MON has to
feed multiple consumers
• A zero-delay algorithm to reduce the risk of re-
identification on a stream of data
• The only zero-delay algorithm which does not
require the injection of false data to protect users'
privacy
• Many possible improvements:
• auto-adjustment of
• generalizing private data instead of suppressing
z
• Network
measurements
must be
performed with
care to avoid
threatening
users’ privacy
POLITO
FACEBOOK
SMARTDATA
XXXX XXXX XXXX XXXX
…
………. ……….
…
Internet
Flow Meter
Campus/Enterprise Network
Security Network Monitoring
⍺-MON
1 2 3 4 5 6 7 8 9
Cores
0.0
2.5
5.0
7.5
10.0
Input
Speed
(Gb/s)
1 Output Feed
2 Output Feeds
4 Output Feeds
0 100 200 300 400
z
0.0
0.2
0.4
0.6
0.8
1.0
p
k°anon
Model, k = 2
Model, k = 3
Model, k = 4
Simulation, k = 2
Simulation, k = 3
Simulation, k = 4
100 101 102 103
Attribute rank
10°10
10°8
10°6
10°4
10°2
100
p
Y
a
z = 1 (original)
z = 50
z = 100
z = 200
• -anonymity tends
to protect rarest
attributes reducing
their probability of
being published
when occurring
( ), that could
easily bring to user
re-identification
z
pY
a
• Applying -anonymity
allows to k-anonymize
a user with a given
probability ,
which can be
evaluated analytically
z
pk−anon
Yes, it is feasible!
• The throughput
scales linearly with
the number of cores in
all cases
… …
5. Authors: G. Perna, D. Markudova, M. Trevisan, P. Garza, M. Meo, M. Munafò
Spazio per
QR Code
(cancellare
riquadro)
Comparison between Webex and Jitsi data collected,
analyzing the cumulative distribution functions
Develop a machine learning-based application to
classify traffic generated by RTC applications, in
order to improve the Quality of Experience (QoE) of
their users.
How?
1. Data collection, pcap from Webex and Jitsi
2. Feature extraction from the RTP flow
3. Feature selection (Correlation + RFECV)
4. Model training
5. Validation
We reach an overall accuracy of 96% for Webex and
95% for Jitsi, using a lightweight decision tree model
that makes decisions using only 1 second of real-
time traffic.
Our approach is conceived to operate as a
building block of a network management
system that optimizes traffic engineering for RTC
applications.
Our final goal is the measurement and
optimization of the QoE perceived by the users of
RTC applications and we release our code and
dataset to foster research in this direction.
In the last period, the use of specific video-
conferencing applications has seen a dizzying
increase, making it increasingly necessary to improve
the quality of experience, to make this new type of
communication ever more realistic and immediate.
Some data:
• 62 hours of call collected
• 127 features extracted per flow
• Around 10 features selected from the initial set
• Best model is Decision Tree classifier
• Using other 20 hours of calls
Focus on feature extraction
6. AI for Traffic Anomaly Detection
Author: Francesca Soro
Knowledge extraction pipeline
Results
Conclusions and future work
Motivation and background
Data collection infrastructure
Unsolicited traffic is a fundamental resource to
analyse for understanding cybersecurity threats.
In a single month (15th April – 15th May 2021) the
infrastructure received around 1.3 billion flows
from 600k unique sources.
Extracting significant information from unwanted
network traffic is a particularly challenging task, due
to the high volume of requests reaching the
monitoring infrastrucutures everyday. Creating a solid
data pipeline – enhanced with AI - is fundamental for
recognizing and preventing new threats.
The Internet traffic is continuously growing in both
volume and complexity, and a wider and wider
variety of connected devices is rising on the market
New cyber-attacks showing unseen fingerprints
are generated everyday, making the design of an
efficient automatic cybersecurity system
problematic
The large amount of available raw data calls for
big-data and artificial intelligence
approaches to help extract
knowledge
I use two types of infrastructures:
Darknets: IP addresses advertised without
hosting any service. They act as passive sensors
in monitoring activities to highlight phenomena
such as network scans (both malicious and
legitimate), and traffic due to bugs or
misconfigured machines.
They anyway allow an intrinsically limited
visibility, as they do not answer traffic requests.
X.X.0.1/24
X.X.0.2/24
X.X.0.3/24
X.X.0.4/24
X.X.0.5/24
Honeypots: active sensors
which answer unsolicited
traffic to obtain a deeper
insight on the attackers’
behaviour.
A large number of existing
honeypots only answer to
selected vertical services
(HTTP, SSH, RDP, etc.).
Darknet
Honeypot
Step 1: Passive traces collection
Capture traffic hitting the infrastructure is
captured as raw .pcap files.
Step 2: Traces processing and
log storage
Process raw data are to obtain a human-
readable log format, then store such files in
a high-end Hadoop cluster.
Step 4: Data analytics
Run graph mining algorithms to detect
communities among remote sources;
perform changepoint detection in traffic
flows.
Step 3: Events characterization
Aggregate logs in a meaningful way to
generate useful features from the
recorded events.
Community
detection
Anomaly
detection
AS 1
2323
23
1433
AS 2 445
Depicting the most
active sources as a
graph based on their
activity allows the
detection of coordinated
actions and possibly
malicious botnets.
New anomaly detection
techniques allow to
mark changepoints and
burst events on traffic
profiles, raising alerts on
new attacks
Date
Number
of
flows
Date
Number
of
flows
7. • Local Navigation with Deep Reinforcement
Learning based on lidar and depth cameras
• DeepWay: a global path planner for row crop
navigation from satellite imagery
• Image semantic segmentation for indoor robot
local path planning
• Person following based on pose estimation and
object detection from RGB-D data
Navigation
AI@PIC4SeR
Authors: Simone Angarano, Francesca Matrone, Vittorio Mazzia,
Francesco Salvetti
Testo (Font Poppins 40)
• Land cover and crops classification with Sentinel II
data
• Multi-image super-resolution of multi-temporal
remote sensing data
• Refinement of satellite-driven vegetation index
with UAV acquisition
• Domain generalization for land cover classification
model Optimization and Edge-ai
• Human Action Recognition with pose estimation
for indoor assistant robot
• Apple Detection and Counting for smart
agriculture
• Ultra-Wideband Positioning Error Correction
• Real-time Crop Segmentation
• Face Identification for access control
• Voice Assistant for human-robot interaction
REMOTE SENSING GEO-AI
• Deep semantic segmentation of cultural built
heritage point clouds for scan-to-BIM processes
• SEI project: spectral evidence of ice. Use of UAV
data for pre-flight inspection of aircraft
• Service robotics and ML with close-range remote
sensing data for precision agriculture
• Towards a FOSS automatic classification of defects
for bridges structural health monitoring
• Classification of riparian plant species
8. Denoise and Contrast for Category Agnostic
Shape Completion
Antonio Alliegro, Diego Valsesia, Giulia Fracastoro, Enrico Magli, Tatiana Tommasi
Point Cloud Completion aims to estimate the
complete geometry of object from partial observation
• Preserving details from the partial observation
• Modelling the missing part with realistic structure
Existing models fail to meet both these requirements:
• What about completion of Unknown Categories?
Motivation and background
Results
Method
• Denoise Pretext
• Accounting for local structures in the shape
topology
• Local features better generalize to Unknown classes
• Contrastive Pretext
• At a global level partial observations of the same
shape should encode similar information (same
semantic)
• Frame Regularization
• Intermediate strategy between whole shape
reconstruction and missing part prediction
• Better blend the generated part with the partial
observation
Conclusions
Unknown Categories
Known Categories
We propose DeCo for point cloud completion in
which:
• Local and global feature encoding is enforced by
specific architectural choices and the use of
tailored pretext tasks
• Framing strategy allows us to blend the
generated output with the partial observation
Achieve SOTA for both Known and Unknown classes
Project Page
antonio.alliegro@polito.it
Missing Part + Frame Decoding
Local ⊕ Global Encoding
Our Architecture
9. Contrastive Language-Image Pre-training for the Italian Language
Federico Bianchi, Giuseppe Attanasio, Raphael Pisoni, Silvia Terragni, Gabriele Sarti, Sri Lakshmi
CLIP: connecting Image and Text CLIP italian
Image retrieval
Challenge: bring CLIP to the Italian language
- "low resource" setting
HuggingFace Flax/JAX Community Week
- CLIP JAX implementation
- efficient TPU v3-8 training
Curated datasets and training
- MSCOCO-IT, Google CC, WIT, Il Post
- high quality translation (when needed)
- 1.4M image-text pairs
- OpenAI's ViT and dbmdz's Italian BERT
- backbone freezing, then unfreeze & fine-tune
Contrastive Language-Image Pre-Training is
OpenAI's latest multi-modal model:
- Learning visual concepts with natural language
supervision
- 400M image, text pairs from the web
- Impressive zero-shot capabilities, but...
- ... English only
"bandiera dell'Italia"
"bandiera della Spagna"
"un gatto"
"bandiera della Francia"
Find the "closest" image
given a text query
Images: Unsplash 25K dataset
zero-shot classification
Pick the "closest" text given a query image
Localization
What part of the image makes it "close" to text?
Based on image occlusion
Outperforms multilingual CLIP on zero-shot
ImageNet classification & IR on MSCOCO-IT Val
10. Today, robotics is undergoing an important
paradigm shift in the context of Industry 4.0, passing
from the main use of traditional industrial
manipulators, intended for multiple automation
tasks, to collaborative robots (cobots), capable of
working in proximity to human operators, as well as
to interact with them in novel ways. In this context,
technologies like Virtual Reality (VR), Augmented
Reality (AR) and Mixed Reality (MR) or, more in
general, eXtended Reality (XR) proved to be very
effective in supporting the mentioned shift and
associated challenges in various domains,
encompassing remote assistance, maintenance,
training and, more broadly, the wide field of Human-
Robot Interaction (HRI).
eXtended Reality Applied to Industrial
and Collaborative Robotics
Authors: F. Gabriele Pratticò and Davide Calandra
AR-powered Remote Assistance
for Robotics
VR Training Systems for Robot
Operators
Multi-user Cobot Programming in XR
Motivation and background
eXtended Reality Robotic Applications
AR has multiple applications in industry, but
remote assistance represents one of the most
widely studied use cases. Although the set of
functionalities supporting the communication
between remote experts and on-site operators
grew over time, the expert typically guides the
operator step-by-step, so the time invested in
the the assistance corresponds to the time
needed to execute the requested operations. In
this context, AR technology can be used to re-
organize the guidance workflow, with the aim
to increase the operator’s autonomy and, thus,
optimize the use of expert’s time.
Although the efficacy of Virtual Reality Training
Systems (VRTSs) as a fancy alternative to
traditional learning material used by trainers in
their lectures has already been proved, their
effectiveness as self-learning tools not
requiring human instructors is still controversial.
Moreover, training robot operators poses key
learning challenges that need to be addressed
such as: being educated on how to operate near
a potentially harmful moving robot in degraded
conditions, prevent equipment damage,
perform non-trivial error recovery procedures,
learn dedicated user-robot interfaces with
phygital controllers, and so forth.
The human direct involvement in cobots
programming can go far beyond the traditional
robot programming. A multi-user programming
scenario, for example, may greatly benefit from
the use of different XR technologies. Distant
users could need to share a common setting
including virtual reconstructions (i.e., Digital
Twins) of the elements that are physically
present only in one of the two environments and
their status/actions. Similarly, local users could
benefit from augmented visualizations of both
the cobot and the distant, tele-present user.
This project has received funding from
the European Union’s Horizon 2020
research and innovation programme
under grant agreement No 101015956.
The activities depicted above have been developed in the context of theVR@POLITO initiative, in collaboration with KUKA Roboter Italia Spa
11. CPSwarm - Design of autonomous
multi-robot systems embedding AI
Authors: E. Ferrera, C. Pastrone, G. Prato, D.Conzon
Scenarios
Partners
Relevant Publications
Vision & Objectives
CPSwarm workbench
Spazio per
QR Code
(cancellare
riquadro)
CPSwarm aims to advance large scale CPS
engineering by reducing development time and
costs, with a particular focus on autonomous
robotic vehicles and drones, freight vehicles and
smart logistics.
Drastically improve support for designing
complex, autonomous CPSs
Address real industrial needs in CPS design
Establish reference patterns and tools for
the integration of CPS artefacts
Reduce the complexity of CPS development
workflows
Define a complete library of swarm and
evolutionary algorithms for CPS design
Provide a self-contained, extensible
library of reusable models for CPSs
• Modeling Swarm Intelligence Algorithms for CPS
Swarms. Workshop on Challenges and new
Approaches for Dependable and Cyber-Physical
Systems Engineering – co-located with Ada-Europe
2019. Warsaw. Poland. June 2019
• Scalable Distributed Simulation for Evolutionary
Optimization of Swarms of Cyber-Physical Systems
International Journal On Advances in Systems and
Measurements. IARA. July 2019.
• The CPSwarm technology for designing swarms of
cyber physical system. Software Technologies:
Applications and Foundations . Eindhoven.
Netherlands. July 2019.
The CPSwarm Workbench provides a set of tools to
support engineering of CPS swarms. A user-
friendly GUI allows the user to access all the
Workbench functionalities and tools.
The CPSwarm Workbench supports the following
features:
Swarm modelling – it allows modelling several
swarm aspects using an extended UML/SysML
formalism.
Simulation & optimization - it allows to visualize
and verify the swarm behavior on external
simulation tools and also to optimize it.
Code generation - it allows to translate design-
level model behavior to executable code.
Swarm deployment – it allows to transfer the
source code and configuration files to the swarm
devices.
Monitor & command - it allows to configure the
swarm and to monitor its behavior during
operation.
Heterogeneous swarms of
ground robots/rovers and
UAVs to conduct missions
for the surveillance of
critical infrastructure.
Search And Rescue
Automotive CPS
Autonomous driving
support intended for freight
vehicles like trucks or vans
connected via kind of an
electronic drawbar
("Platoon").
Swarm Logistics
Robots and rovers that
collaboratively assist
humans in a logistics
domain.
This project has received funding from the European Union’s Horizon 2020 research and
innovation programme under grant agreement No 731946.
Project Coordinator:
Claudio Pastrone
claudio.pastrone@linksfoundation.com
Fondazione LINKS
Torino, Italy
WWW.CPSWARM.EU
@CPSWARM_EU
Contacts
@CPSWARM EU
@CPSWARM.EU