
Recomendados
Mais conteúdo relacionado
Mais procurados
Mais procurados (20)
Semelhante a もろもろの AI ツールを Windows のローカル環境にインストールする手順
Semelhante a もろもろの AI ツールを Windows のローカル環境にインストールする手順 (20)
Mais de Hide Koba
もろもろの AI ツールを Windows のローカル環境にインストールする手順
- 1. 2022 年 10 月 11 日 (火) 小林 秀章 資料 もろもろの AI ツールをローカル環境に インストールする手順
- 2. 概要
- 3. 概要 このところ次から次へとリリースされているもろもろの AI ツールの うちでも、パソコンのローカル環境で走らせることができる形で 提供されているものがいくつかある。 ここでは、それらのうち下記 3 本について、ローカル環境へ インストールする手順を解説する。 (1) テキストから画像を生成する Stable Diffusion (2) 日本語テキストから画像を生成する Japanese Stable Diffusion (3) 人のしゃべった言葉をテキストに書き起こす Whisper インストール手順の途中までは共通するので、 ひとつの AI ツールについて環境構築しておくと、 他への展開がラクにできるようになる。
- 4. システム構成
- 5. ハードウェア構成例 (1/5) どこのマシン? → 池袋の漫画喫茶の → けっこうスペック高い → けど、GPU のメモリが 足りない 経過: ・ GPU のメモリ不足で、 Diffusers 上での Stable Diffusion が 走らない ・ 同じ理由で、 rinna の Japanese Stable Diffusion も 走らない
- 6. ハードウェア構成例 (2/5) どこのマシン? → 池袋の漫画喫茶の 別の部屋の → CPU のスペックはやや低め → だが、GPU のメモリが 8GB ある! 経過: ・ GPU のメモリ不足で、 Diffusers 上での Stable Diffusion が 走らない ・ 同じ理由で、 rinna の Japanese Stable Diffusion も 走らない
- 7. ハードウェア構成例 (3/5) どこのマシン? → 秋葉原の漫画喫茶の ゲーム部屋の → スペックはじゅうぶん 経過: ・ Diffusers 上での Stable Diffusion、および、 rinna の Japanese Stable Diffusion が走った
- 8. ハードウェア構成例 (4/5) どこのマシン? → 池袋の漫画喫茶の 多機能部屋の → スペックはじゅうぶん 経過: ・ Diffusers 上での Stable Diffusion、および、 rinna の Japanese Stable Diffusion が走った
- 9. 経過: ・ Diffusers 上での Stable Diffusion が 走った ・ rinna の Japanese Stable Diffusion が 走らない (たぶん、git が Proxy を越えられないせい) ハードウェア構成例 (5/5) どこのマシン? → オレさま専用マシン (会社の自席に設置) → これならスペック じゅうぶんなはず
- 10. システム要件 • Windows 10 マシン + NVIDIA GPU (本例では) • NVIDIA の GPU で、GTX 10 シリーズかそれより新しいものが 搭載されている • 8 GB 以上の VRAM • 12 GB 以上の VRAM がない場合、出力画像サイズを 512 × 512 画素以下に設定して Stable Diffusion を利用すべし • CUDA を通じて GPU にアクセスできる (CUDA はこれからインストールする) • pip コマンド (Python のパッケージ・マネージャ) が Proxy サーバを越えて外部インターネットにアクセスできる • git コマンドが Proxy サーバを越えて外部インターネットに アクセスできる
- 11. システム要件 (ぎりぎりセーフ) • 漫画喫茶などでは、パソコンを再起動すると、ハードディスクに 書き込んだデータがすべて消去されるようになっている。 なので、パソコンを再起動できない。 → しかし、これは問題ない。 Visual Studio のインストールで再起動を推奨されるが、 無視して続行してよい • ユーザ名の文字列が日本語文字を含んでいると、 rinna の Japanese Stable Diffusion の実行時にエラー終了する。 → しかし、これは関数呼び出しの際に引数を付加することで 解決する 画像生成の実行中、待っている間に、暇だからといって、 YouTube 動画などを見にいってはいけない! ハングアップするぞ! [Control] + [Alt] + [Delete] も効かなくなり、 最後の手段で電源ボタンを長押しして落とすしかなくなる。 漫画喫茶では、すべてが消える!
- 12. AI 環境構築方法
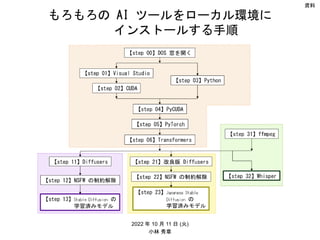
- 13. インストールのフロー 【step 00】DOS 窓を開く 【step 13】Stable Diffusion の 学習済みモデル 【step 02】CUDA 【step 03】Python 【step 01】Visual Studio 【step 04】PyCUDA 【step 05】PyTorch 【step 06】Transformers 【step 11】Diffusers 【step 21】改良版 Diffusers 【step 23】Japanese Stable Diffusion の 学習済みモデル 【step 12】NSFW の制約解除 【step 22】NSFW の制約解除 【step 31】ffmpeg 【step 32】Whisper
- 14. 参考になるウェブサイト • 【簡単】ローカル環境でStable Diffusionを実行する方法 • https://self- development.info/%e3%80%90%e7%b0%a1%e5%8d%98%e3%80%91%e3%83%ad%e3%83%bc%e3 %82%ab%e3%83%ab%e7%92%b0%e5%a2%83%e3%81%a7stable- diffusion%e3%81%a7%e5%ae%9f%e8%a1%8c%e3%81%99%e3%82%8b%e6%96%b9%e6%b3%95/ ジコログ
- 15. 参考になるウェブサイト • 【日本語を呪文に使える】Japanese Stable Diffusionのインストール • https://self- development.info/%E3%80%90%E6%97%A5%E6%9C%AC%E8%AA%9E%E3%82%92%E5%91%AA%E6 %96%87%E3%81%AB%E4%BD%BF%E3%81%88%E3%82%8B%E3%80%91japanese-stable- diffusion%E3%81%AE%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%AB/ ジコログ
- 16. 参考になるウェブサイト • ほぼ完璧な文字起こしができる AI 音声認識 Whisper のインストール • https://self- development.info/%E3%81%BB%E3%81%BC%E5%AE%8C%E7%92%A7%E3%81%AA%E6%96%87%E5 %AD%97%E8%B5%B7%E3%81%93%E3%81%97%E3%81%8C%E3%81%A7%E3%81%8D%E3%82%8Bai%E9 %9F%B3%E5%A3%B0%E8%AA%8D%E8%AD%98whisper%E3%81%AE%E3%82%A4%E3%83%B3/ ジコログ
- 18. 【step 00】 コマンド・プロンプト (DOS 窓) を開く • コマンド・プロンプト (DOS 窓) を 管理者権限モードで (← ここ、大事!) 立ち上げる – [Windows] - [Windows システムツール] - [コマンド プロンプト] で右ボタン、 [その他] - [管理者として実行]
- 19. 【ワンポイント】 path の通しかた • ツール類をインストールした後、どのフォルダにいても 実行可能ファイル “*.exe”が見えるように path を通しておく 必要が生じることがしばしばある • 環境変数 %path% に、セミコロン (;) 区切りで、path の リストを書いておけばよい。具体的には、次のようにする • コマンド・プロンプト (DOS 窓) を 管理者権限モードで (← ここ、大事!) 立ち上げる – [Windows] - [Windows システムツール] - [コマンド プロンプト] で右ボタン、 [その他] - [管理者として実行] • path を通す – コマンド・プロンプトで set path=%path%;… – たとえば set path=%path%;C:¥Program Files¥NVIDIA GPU Computing Toolkit¥CUDA¥v11.6¥bin – この方法は、このコマンドプロンプト内でのみ有効な、その場かぎりのもの • 別のコマンド・プロンプトを立ち上げても生きるようにするには – [コントロールパネル] - [システムとセキュリティ] - [システム] - [設定の変更] [詳細設定] - [環境変数] – システム変数 Path を書き換える。; 区切りの文字列に上記を付記 • 以下では、まず最初にコマンド・プロンプトが立ち上げてある ものとして、その場かぎりの方法で行く
- 21. 【step 01】 Visual Studio • Visual Studio が必要な理由 (1) CUDA をインストールする際に警告メッセージの表示を 抑止したいなら Visual Studio が必要。 しかし、必須ではなさそう (2) PyCUDA をインストールするために必要。
- 22. 【step 01】 Visual Studio (つづき) • もし、Visual Studio がインストールされていない状態で CUDA をインストールしようとすると、上図のような警告が表示される。 その場合でも、チェックを入れて続行すれば、後の工程になんら支障を きたさないようだ。 つまり、Visual Studio のインストールは必須ではないようだ
- 23. 【step 01】 Visual Studio (つづき) • もし、Microsoft C++ Build Tools が インストールされていない状態で PyCUDA をインストールしようとすると、 上図のようなエラーメッセージが表示され、 エラー終了してしまう。 なので、これを通過させるために、 Microsoft C++ Build Tools は必須 • Visual Studio をインストールすれば解決するが、 代わりに Microsoft C++ Build Tools だけを インストールするのでも解決する error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
- 24. 【step 01】 Visual Studio (つづき) • Visual Studio のどのエディションをインストールするかについて、 下記 4 つの選択肢がある。 (1) Build Tools for Visual Studio 2022 (2) Visual Studio (2-1) Community 2022 (2-2) Professional 2022 (有料) (2-3) Enterprise 2022 (有料) • (1) Build Tools for Visual Studio 2022 がいちばん軽い。 しかし、CUDA のインストール中に表示される警告は消えない。 これで行くなら、下記 Microsoft C++ Build Tools の ウェブサイトへ行く https://visualstudio.microsoft.com/visual-cpp-build-tools/ • (2-1) Visual Studio Community 2022 なら、CUDA の警告が表示されず、 いちばん安心できる。 これで行くなら、下記 Visual Studio のウェブサイトへ行く https://visualstudio.microsoft.com/ja/ 以下では、こっちについて説明する
- 25. 【step 01】 Visual Studio (つづき) • Microsoft Visual Studio のウェブサイトへ行く https://visualstudio.microsoft.com/ja/ • [Visual Studio のダウンロード] – [Community 2022] を選ぶ • 下記ファイルがダウンロードされる “VisualStudioSetup.exe”
- 26. 【step 01】 Visual Studio (つづき) • ダウンロードした EXE ファイルを実行する
- 27. 【step 01】 Visual Studio (つづき) これだけ チェック これを押す
- 28. 【step 01】 Visual Studio (つづき) 待つ
- 29. 【step 01】 Visual Studio (つづき) 漫画喫茶などでは、パソコンを再起動すると、 初期状態に戻ってしまう。 そのような環境では、再起動せずに作業を続けても問題ない。
- 30. 【step 01】 Visual Studio (つづき) 右上の [×] でウィンドウを閉じてよい
- 31. 【step 01】 Visual Studio (つづき) • DOS 窓で、“cl.exe”へ path を通す – DOS 窓 (コマンド・プロンプト) で set path=%path%;C:¥Program Files¥Microsoft Visual Studio¥2022¥Community¥VC¥Tools¥MSVC¥14.33.31629¥bin¥HostX86¥x86 • 動作チェック: DOS 窓で cl –help と打ち、バージョンと使い方が表示されればOK
- 32. 【step 02】CUDA
- 33. 【step 02】 CUDA 11.6.2 • 下記サイト https://developer.nvidia.com/cuda-toolkit-archive へ行くと、CUDA Toolkit のいろいろなバージョンが選べるようになっている。 最新版は CUDA Toolkit 11.8.0 (October 2022) だが、 あとでインストールするツールとの兼ね合いで、 CUDA Toolkit 11.6.2 (March 2022) を選ぶ これ
- 34. 【step 02】 CUDA 11.6.2 • 条件を選択 [Windows], [x86_64], [10], [exe (local)] → [Download (2.5GB)] “cuda_11.6.2_511.65_windows.exe”
- 35. 【step 02】 CUDA 11.6.2 • その exe ファイルを実行
- 36. 【step 02】 CUDA 11.6.2 • [カスタム] を選択して [次へ] を押す
- 37. 【step 02】 CUDA 11.6.2 • [CUDA] だけチェックを残し、それ以外のチェックを外し、 [次へ] を押す
- 38. 【step 02】 CUDA 11.6.2 • 何もせず [次へ] を押す
- 39. 【step 02】 CUDA 11.6.2 • Microsoft Visual Studio がインストールしてあれば、 この画面は表示されないはず • Build Tools for Visual Studio をインストールした場合は、 この画面が表示されるが、チェックを入れて進めば問題なさそう
- 40. 【step 02】 CUDA 11.6.2 • ステータスのことは、あんまり気にせず、[閉じる] を押す
- 41. • 下記ファイルができているはず “C:¥Program Files¥NVIDIA GPU Computing Toolkit¥CUDA¥v11.6¥bin¥nvcc.exe” DOS 窓で、そこへ PATH を通す set path=%path%;C:¥Program Files¥NVIDIA GPU Computing Toolkit¥CUDA¥v11.6¥bin • DOS 窓で、さらに CUDA_PATH を通す set CUDA_PATH=C:¥Program Files¥NVIDIA GPU Computing Toolkit¥CUDA¥v11.6 • 動作確認: DOS 窓で、 nvcc –V と打つと、下記のように返ってくる nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Tue_Mar__8_18:36:24_Pacific_Standard_Time_2022 Cuda compilation tools, release 11.6, V11.6.124 Build cuda_11.6.r11.6/compiler.31057947_0 【step 02】 CUDA 11.6.2 (つづき)
- 42. 【step 03】Python
- 43. 【step 03】 Python • 下記サイト https://www.python.org/ へ行き、[Downloads] – [Windows] を選ぶ。 もろもろのバージョンが選べるようになっている。 2022年10月11日(火) 時点での最新版は 3.10.7。 初めてインストールするなら最新バージョンを入れるのが望ましい。 私は、普段使いの都合上、 Python 3.7.9 – Aug. 17, 2020 Download Windows x86-64 executable installer を選んだ。 “python-3.7.9-amd64.exe 3.7.9 でも問題なく走る。 rinna の Japanese Stable Diffusion の実行時にエラー終了する問題は、 Python のバージョンを最新に上げることでは解決しない。
- 44. 【step 03】 Python (つづき) 実行ファイルがダウンロードされる。 “python-3.10.7-amd64.exe” それを実行する。
- 45. チェックを入れる こっちを選ぶ 【step 03】 Python (つづき)
- 46. ぜんぶにチェック (デフォルトのまま) 【step 03】 Python (つづき)
- 47. チェックを入れる チェックがつく 【step 03】 Python (つづき) これを押す
- 48. 【step 03】 Python (つづき) 待つ
- 49. 【step 03】 Python (つづき) これを押す これをつついておく
- 50. 【step 03】 Python (つづき) • DOS 窓で path を通す set path=C:¥Program Files¥Python310¥Scripts¥;%path% set path=C:¥Program Files¥Python310¥;%path% • 下記のコマンドで、exe ファイルへのフルパスが表示されればOK。 where pip3 where python
- 51. 【step 04】PyCUDA
- 52. 【step 04】 PyCUDA • CUDA は C/C++ のプログラムから呼び出すのが基本の形。 なので、Python のプログラムから直接に CUDA を呼び出すことはできない。 そこを仲介するのが PyCUDA • これをインストールするために、先ほどの【step 01】の Visual C++ Build Tools が必要 • DOS 窓で、 python -m pip install pycuda と打つ
- 53. 【step 4】 PyCUDA (つづき) • 動作確認: 下記の Python プログラムを走らせ、何ごともなく終了すればOK # -*- coding: cp932 -*- # GPUにデータを転送するプログラム # PyCudaのインポート import pycuda.driver as cuda import pycuda.autoinit from pycuda.compiler import SourceModule # numpy配列用 import numpy # 4x4の乱数のnumpy配列を作成 a = numpy.random.randn(4,4) # nVidiaデバイス(GPU)は単精度のみサポート→変換 a = a.astype(numpy.float32) # GPU上に送信データ用のメモリを割り当てる a_gpu = cuda.mem_alloc(a.nbytes) # GPUにデータを転送 cuda.memcpy_htod(a_gpu, a) ジコログ「PyCUDA のインストール」 https://self-development.info/pycuda%E3%81%AE%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%AB%E3%80%90python-on-windows%E3%80%91/
- 54. 【step 4】 PyCUDA (つづき) • 動作確認: もし、numpy がないという理由でエラー終了した場合は、 python –m pip install numpy
- 55. 【step 05】PyTorch
- 56. 【step 05】 PyTorch 1.12.1 + cu116 • PyTorch とは、Facebookが開発を主導した Python 向けの 機械学習 (Deep Learning) ライブラリ • 下記サイト https://pytorch.org/ へ行く。 設定項目を選択すると、 コマンド・ラインが 表示される (※) • 先ほどの管理者権限の DOS 窓で、下記を実行。 pip3 がないと言われたら、pip で代用してもよい python -m pip install --upgrade setuptools pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116 → 3 分ほど待たされるが、正常に完了する ※ Compute Platform の選択肢に CUDA 11.7 がないので、 CUDA をインストールする際、11.6 を選んだ
- 57. 【step 05】 PyTorch 1.12.1 + cu116 (つづき) • 動作確認: 先ほどの管理者権限の DOS 窓で Python を走らせ、 コマンドを打つ python >>> import torch >>> print(torch.__version__) 1.12.1+cu116 >>> print(torch.cuda.is_available()) True CUDA を呼び出せる形で PyTorch がちゃんと インストールできている、ということらしい
- 59. 【step 6】 HuggingFace の Transformers • Transformersとは、米国の Hugging Face 社が開発して公開している 自然言語処理ライブラリ。 • 先ほどの管理者権限の DOS 窓で、下記を実行 python -m pip install transformers いろいろ拾ってくるけど、20 秒ほどで完了する
- 60. 【step 6】 HuggingFace の Transformers from transformers import pipeline classifier = pipeline('sentiment-analysis') results = classifier([ ¥ "We are very happy to show you the ?? Transformers library.", ¥ "We hope you don't hate it."]) for result in results: print(f"label: {result['label']}, with score: {round(result['score'], 4)}") The cache for model files in Transformers v4.22.0 has been updated. Migrating your old cache. This is a one-time only operation. You can interrupt this and resume the migration later on by calling `transformers.utils.move_cache()`. Moving 0 files to the new cache system 0it [00:00, ?it/s] No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english and revision af0f99b (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english). Using a pipeline without specifying a model name and revision in production is not recommended. Downloading: 100%|████████████████████████████████████████████████████████████████████| 629/629 [00:00<00:00, 40.3kB/s] Downloading: 100%|██████████████████████████████████████████████████████████████████| 268M/268M [00:03<00:00, 82.8MB/s] Downloading: 100%|██████████████████████████████████████████████████████████████████████████| 48.0/48.0 [00:00<?, ?B/s] Downloading: 100%|███████████████████████████████████████████████████████████████████| 232k/232k [00:00<00:00, 371kB/s] label: POSITIVE, with score: 0.9996 label: NEGATIVE, with score: 0.5309 • 動作確認: 先ほどの管理者権限の DOS 窓で、 下記の Python プログラムを走らせる • 結果、下記のように表示されればOK ジコログ「HuggingfaceのTransformersをインストールする」 https://self-development.info/huggingface%E3%81%AEtransformers%E3%82%92%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%AB%E3%81%99%E3%82%8B/
- 61. rinna の Japanese Stable Diffusion をインストールする場合は、 次の【step 7】~【step 9】を飛ばして、 【step 10】へ進んでよい。
- 63. • Diffusers とは、米国の Hugging Face 社が開発して公開している 機械学習用の便利ツール。 画像や音声に対応した事前学習済みの拡散モデルを提供している Diffusers を使えば、モデルのダウンロードも簡単にできる。 • 先ほどの管理者権限の DOS 窓で、下記を実行 python -m pip install diffusers いろいろ拾ってくるけど、あっという間に完了する 【step 11】 HuggingFace の Diffusers
- 64. 【step 11】 HuggingFace の Diffusers (つづき) • 動作確認: 先ほどの管理者権限の DOS 窓で、 下記の Python プログラムを走らせる • 結果、なんとっ! もうすでに絵が描けている! from diffusers import DiffusionPipeline model_id = "CompVis/ldm-text2im-large-256" # load model and scheduler ldm = DiffusionPipeline.from_pretrained(model_id) # run pipeline in inference (sample random noise and denoise) prompt = "A painting of a squirrel eating a burger" images = ldm([prompt], num_inference_steps=50, eta=0.3, guidance_scale=6)["sample"] # save images for idx, image in enumerate(images): image.save(f"squirrel-{idx}.png") ジコログ「最先端の機械学習モデルを利用できる Diffusers の インストール」 https://self- development.info/%E6%9C%80%E5%85%88%E7%AB%AF%E3%81%AE%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%8 3%A2%E3%83%87%E3%83%AB%E3%82%92%E5%88%A9%E7%94%A8%E3%81%A7%E3%81%8D%E3%82%8Bdiffusers%E3%81%AE %E3%82%A4%E3%83%B3%E3%82%B9/
- 66. 【step 12】 NSFW の制約解除 • 判定にひっかかった画像は全面黒塗りで出力される、 あるいは何も出力されない • それを解除する裏ワザ: Python のソースをいじって、判定処理部分をコメント・アウトしてしまう • ソースは、これ。 C:¥Program Files¥Python37¥Lib¥site-packages¥diffusers¥pipelines¥stable_diffusion¥ safety_checker.py • テキスト・エディタを管理者モードで立ち上げ、エディットする
- 67. … has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result] for idx, has_nsfw_concept in enumerate(has_nsfw_concepts): if has_nsfw_concept: images[idx] = np.zeros(images[idx].shape) # black image if any(has_nsfw_concepts): logger.warning( "Potential NSFW content was detected in one or more images. A black image will be returned instead." " Try again with a different prompt and/or seed." ) return images, has_nsfw_concepts … … has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result] for idx, has_nsfw_concept in enumerate(has_nsfw_concepts): if has_nsfw_concept: # images[idx] = np.zeros(images[idx].shape) # black image print("image[{:3d} / {:3d}]: potentially NFSW" ¥ .format(idx, len(has_nsfw_concepts))) if any(has_nsfw_concepts): logger.warning( "Potential NSFW content was detected in one or more images. A black image will be returned instead." " Try again with a different prompt and/or seed." ) has_nsfw_concepts = [False for has_nsfw_concept in has_nsfw_concepts] return images, has_nsfw_concepts … True または False が生成画像の 枚数分だけ並んだ配列。True: 問題あり 問題のある画像を全面真っ黒な画像で 置き換えている どの画像に問題があったかの情報を呼び出し側に返していて、 上位の関数でも、ファイル出力の抑制をしている 全面真っ黒な画像で置き換えるところを コメント・アウトして、実行しなくする すべて False からなる配列に 書き換える (上位関数をだます) 修正前 修正後
- 68. 英文プロンプト: (自粛) 自粛
- 69. 【step 13】Stable Diffusion の学習済みモデル
- 70. 【step 13】 Stable Diffusion の学習済みモデル • HuggingFace にアカウントを作成 https://huggingface.co/join 必要事項を記入してアカウントを作成すると、メールが届くので、 リンク先へアクセスする • 利用規約を読んで、同意する https://huggingface.co/CompVis/stable-diffusion-v1-4 読んだ確認にチェックを入れ、[Access repository] ボタンを押す • Access Token を管理する https://huggingface.co/settings/tokens [New Token] ボタンを押す Create a new access token Name: Stable Diffusion Role: read [Generate a token] → 長い文字列が与えられる → [Copy]
- 71. 【step 13】 Stable Diffusion の学習済みモデル (つづき) • 動作確認: 先ほどの管理者権限の DOS 窓で、 下記の Python プログラムを走らせる import torch from diffusers import StableDiffusionPipeline from torch import autocast MODEL_ID = "CompVis/stable-diffusion-v1-4" DEVICE = "cuda" YOUR_TOKEN = "(Access Token の文字列)" pipe = StableDiffusionPipeline.from_pretrained(MODEL_ID, revision="fp16", ¥ torch_dtype=torch.float16, use_auth_token=YOUR_TOKEN) pipe.to(DEVICE) prompt = "a dog painted by Katsuhika Hokusai" with autocast(DEVICE): image = pipe(prompt, guidance_scale=7.5)["sample"][0] image.save("test.png") ジコログ「【簡単】ローカル環境でStable Diffusionを実行する方法」 https://self- development.info/%E3%80%90%E7%B0%A1%E5%8D%98%E3%80%91%E3%83%AD%E3%83%BC%E3%82%AB%E3%83%AB%E7%92%B0%E5%A2%8 3%E3%81%A7stable-diffusion%E3%81%A7%E5%AE%9F%E8%A1%8C%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95/
- 72. 【step 13】 Stable Diffusion の学習済みモデル (つづき) • GPU のメモリ不足でうまくいかなかったとき:
- 73. 【step 13】 Stable Diffusion の学習済みモデル (つづき) • うまくいったとき:
- 74. 【step 21】rinna の改良版 Diffusers
- 75. 【step 21】 rinna の改良版 Diffusers • Git をインストール – Git の公式サイトへ行く https://git-scm.com/ – “*.exe” 形式のインストーラをダウンロードしてくる “Git-2.38.0-64-bit.exe” – それを実行する。設定の選択肢はぜんぶデフォルトでよい – “git.exe”が見えるよう、path を張っておく set path=%path%;C:¥Program Files¥Git¥bin • 次のコマンドを実行して、rinna の改良版 Diffusers をインストール python -m pip install git+https://github.com/rinnakk/japanese-stable-diffusion 改良版における変更点は、おそらく関数を増やしただけであり、 これの上で、ふつうの英語版の Stable Diffusion を 走らせることもできる。実際、ちゃんと走った。 【step 12】 で、“safety_checker.py” をエディットしていたとしても、 上記のコマンドを実行すると上書きされて、元に戻っちゃうので注意。
- 77. 【step 22】 NSFW の制約解除 • 【step 12】 とまったく同じ。再掲。 • 判定にひっかかった画像は全面黒塗りで出力される、 あるいは何も出力されない • それを解除する裏ワザ: Python のソースをいじって、判定処理部分をコメント・アウトしてしまう • ソースは、これ。 C:¥Program Files¥Python37¥Lib¥site-packages¥diffusers¥pipelines¥stable_diffusion¥ safety_checker.py • テキスト・エディタを管理者モードで立ち上げ、エディットする
- 78. … has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result] for idx, has_nsfw_concept in enumerate(has_nsfw_concepts): if has_nsfw_concept: images[idx] = np.zeros(images[idx].shape) # black image if any(has_nsfw_concepts): logger.warning( "Potential NSFW content was detected in one or more images. A black image will be returned instead." " Try again with a different prompt and/or seed." ) return images, has_nsfw_concepts … … has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result] for idx, has_nsfw_concept in enumerate(has_nsfw_concepts): if has_nsfw_concept: # images[idx] = np.zeros(images[idx].shape) # black image print("image[{:3d} / {:3d}]: potentially NFSW" ¥ .format(idx, len(has_nsfw_concepts))) if any(has_nsfw_concepts): logger.warning( "Potential NSFW content was detected in one or more images. A black image will be returned instead." " Try again with a different prompt and/or seed." ) has_nsfw_concepts = [False for has_nsfw_concept in has_nsfw_concepts] return images, has_nsfw_concepts … True または False が生成画像の 枚数分だけ並んだ配列。True: 問題あり 問題のある画像を全面真っ黒な画像で 置き換えている どの画像に問題があったかの情報を呼び出し側に返していて、 上位の関数でも、ファイル出力の抑制をしている 全面真っ黒な画像で置き換えるところを コメント・アウトして、実行しなくする すべて False からなる配列に 書き換える (上位関数をだます) 修正前 修正後
- 79. 【step 23】Japanese Stable Diffusion の学習済みモデル
- 80. 【step 23】 Japanese Stable Diffusion の学習済みモデル • HuggingFace にアカウントを作成 https://huggingface.co/join 必要事項を記入してアカウントを作成すると、メールが届くので、 リンク先へアクセスする • 利用規約を読んで、同意する (先ほどとは URL が異なる) https://huggingface.co/rinna/japanese-stable-diffusion 読んだ確認にチェックを入れ、[Access repository] ボタンを押す • Access Token を管理する https://huggingface.co/settings/tokens [New Token] ボタンを押す Create a new access token Name: Stable Diffusion Role: read [Generate a token] → 長い文字列が与えられる → [Copy] rinna の規約に同意する作業を、あらためて 1 回だけおこなう 必要があるが、返ってくる文字列は、先ほどの【step 8】と まったく同一。
- 81. 【step 11】 Japanese Stable Diffusion の学習済みモデル (つづき) • 動作確認: 先ほどの管理者権限の DOS 窓で、 次ページの Python プログラムを走らせる
- 82. # -*- coding: cp932 -*- import torch from torch import autocast from diffusers import LMSDiscreteScheduler from japanese_stable_diffusion import JapaneseStableDiffusionPipeline import os model_id = "rinna/japanese-stable-diffusion" device = "cuda" your_token = "(Access Token の文字列)" prompt = "勉強する高校生" dst_filename = "test_jsd01_02.png" scheduler = LMSDiscreteScheduler(beta_start = 0.00085, beta_end = 0.012, ¥ beta_schedule = "scaled_linear", num_train_timesteps = 1000) pipe = JapaneseStableDiffusionPipeline.from_pretrained( ¥ model_id, ¥ torch_dtype = torch.float16, ¥ scheduler = scheduler, ¥ use_auth_token = your_token, ¥ cache_dir = "C:¥¥Users¥¥hoge¥¥.cache") pipe = pipe.to(device) with autocast(device): image = pipe( ¥ prompt, ¥ width = 512, height = 512, ¥ guidance_scale = 7.5, ¥ num_inference_steps = 500 ¥ )["sample"][0] image.save(dst_filename) ジコログ「【日本語を呪文に使える】Japanese Stable Diffusionのインストール」 https://self- development.info/%E3%80%90%E6%97%A5%E6%9C%AC%E8%AA%9E%E3%82%92%E5%91%AA%E6%96%87%E3%81%AB%E4%BD%BF%E3%81%88%E3%82%8B%E3%8 0%91japanese-stable-diffusion%E3%81%AE%E3%82%A4%E3%83%B3%E3%82%B9%E3%83%88%E3%83%BC%E3%83%AB/
- 83. 勉強する高校生
- 84. 実行時エラーへの対策 (1): GPU のメモリ不足 • GPU のメモリが不足していると、実行時にエラー終了する • 実は、さきほどのプログラムで手を打ってある RuntimeError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 8.00 GiB total capacity; 5.82 GiB already allocated; 291.25 MiB free; 5.83 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
- 85. # -*- coding: cp932 -*- import torch from torch import autocast from diffusers import LMSDiscreteScheduler from japanese_stable_diffusion import JapaneseStableDiffusionPipeline import os model_id = "rinna/japanese-stable-diffusion" device = "cuda" your_token = "(Access Token の文字列)" prompt = "勉強する高校生" dst_filename = "test_jsd01_02.png" scheduler = LMSDiscreteScheduler(beta_start = 0.00085, beta_end = 0.012, ¥ beta_schedule = "scaled_linear", num_train_timesteps = 1000) pipe = JapaneseStableDiffusionPipeline.from_pretrained( ¥ model_id, ¥ torch_dtype = torch.float16, ¥ scheduler = scheduler, ¥ use_auth_token = your_token, ¥ cache_dir = "C:¥¥Users¥¥hoge¥¥.cache") pipe = pipe.to(device) with autocast(device): image = pipe( ¥ prompt, ¥ width = 512, height = 512, ¥ guidance_scale = 7.5, ¥ num_inference_steps = 500 ¥ )["sample"][0] image.save(dst_filename) GPU での計算精度を下げることにより、 割り付けるメモリ量を少なく済むようにしている
- 86. 実行時エラーへの対策 (2): ファイル読み込みエラー • ユーザ名の文字列が日本語文字を含んでいると、実行時に ファイルが見つからないというエラーになる • しかし、実際には、ファイルはちゃんと存在している • ホームディレクトリの下にキャッシュ用のディレクトリ “.cache” を作り、 その下にモデルファイルなどを置いておいて、2 度目以降に実行する 際にはファイルをダウンロードしてくる処理を省略している。 このキャッシュの path が日本語文字を含んでいると、トラブる。 バグっぽい • 実は、さきほどのプログラムで手を打ってある。 OSError: Not found: “C:¥Users¥(ユーザ名 )/.cache¥huggingface¥diffusers¥models--rinna--japanese-stable- diffusion¥snapshots¥f54150d0a231ffcca20b93643ca485695f182282¥tokenizer ¥spiece.model": No such file or directory Error #2 エラーが発生する直前に実行しているのは、 Google の tokenizer「T5 (Text-to-Text Transfer Transformer)」。 しかし、ソースがコンパイルしてあって、たどれない。
- 87. # -*- coding: cp932 -*- import torch from torch import autocast from diffusers import LMSDiscreteScheduler from japanese_stable_diffusion import JapaneseStableDiffusionPipeline import os model_id = "rinna/japanese-stable-diffusion" device = "cuda" your_token = "(Access Token の文字列)" prompt = "勉強する高校生" dst_filename = "test_jsd01_02.png" scheduler = LMSDiscreteScheduler(beta_start = 0.00085, beta_end = 0.012, ¥ beta_schedule = "scaled_linear", num_train_timesteps = 1000) pipe = JapaneseStableDiffusionPipeline.from_pretrained( ¥ model_id, ¥ torch_dtype = torch.float16, ¥ scheduler = scheduler, ¥ use_auth_token = your_token, ¥ cache_dir = "C:¥¥Users¥¥hoge¥¥.cache") pipe = pipe.to(device) with autocast(device): image = pipe( ¥ prompt, ¥ width = 512, height = 512, ¥ guidance_scale = 7.5, ¥ num_inference_steps = 500 ¥ )["sample"][0] image.save(dst_filename) path が日本語文字を含まないように、 cache ディレクトリを明示的に 割り当てなおしている
- 88. 【step 31】FFmpeg
- 89. 【step 31】 Ffmpeg • FFmpeg (エフエフエムペグ) は動画と音声を記録・変換・再生するための フリーソフトウェア • 【step 6】までに構築してきた環境とはまったく独立なので、 いつインストールしてもよい • FFmpeg 公式サイトのダウンロードページへ行く https://www.ffmpeg.org/download.html • [Windows] を選ぶ。[Windows builds by BtbN] を選ぶ • ダウンロード可能なファイルのリストの中から、下記を選ぶ。 "ffmpeg-master-latest-win64-gpl.zip" • 圧縮ファイルを解凍する。 "ffmpeg-master-latest-win64-gpl" フォルダができていて、 その下にファイルが展開されている。 • このフォルダをリネームしておこう。"ffmpeg" • それを、"C:¥Program Files" の下に移動する。 • それの "bin" の下へ path を通す。 set path=%path%;C:¥Program Files¥ffmpeg¥bin
- 90. 【step 6】 FFmpeg (つづき) • 動作確認: ffmpeg –version • もっと念入りに動作確認するなら、動画ファイルから 音声だけを切り離して、音声ファイルとしてセーブしてみよう ffmpeg -i input.mp4 output.mp3
- 91. 【step 32】Whisper
- 92. 【step 7】 Whisper • Git をインストール – Git の公式サイトへ行く https://git-scm.com/ – “*.exe” 形式のインストーラをダウンロードしてくる “Git-2.37.3-64-bit.exe” – それを実行する。設定の選択肢はぜんぶデフォルトでよい – “git.exe”が見えるよう、path を張っておく set path=%path%;C:¥Program Files¥Git¥bin • 次のコマンドを実行して、Whisper をインストール pip install git+https://github.com/openai/whisper.git • なんと、“whisper.exe” ができていて、そこへ path が通っている。 自作の Python プログラムから呼び出せるモジュールも用意されている ようだけど、ふつうに文字起こしするだけなら、コマンドを 呼び出しちゃったほうが簡単だ • 動作確認: whisper –h • 実行 whisper (入力音声ファイル) --language Japanese --model medium