Baixar para ler offline










![Amazon EMR + Jupyter
BootstrapActions=[
{
'Name': 'Jupyter Notebook',
'ScriptBootstrapAction': {
'Path': 's3://aws-bigdata-blog/artifacts/aws-blog-emr-jupyter/install-
jupyter-emr5.sh',
'Args': [
'--s3fs', '--python3',
'--python-packages', 'pandas matplotlib findspark boto3',
'--port', '8880', '--password' ,'jupyter',
'--cached-install',
'--notebook-dir', 's3://mybucket/notebooks/']
}
},
],
https://aws.amazon.com/pt/blogs/big-data/running-jupyter-notebook-and-jupyterhub-on-
amazon-emr/](https://image.slidesharecdn.com/trilhabigdatacomointegrarassoluesdostimesdedataengineeringedatascience-171127190403/85/TDC2017-POA-Trilha-BigData-Como-integrar-as-solucoes-dos-times-de-Data-Engineering-e-Data-Science-12-320.jpg)






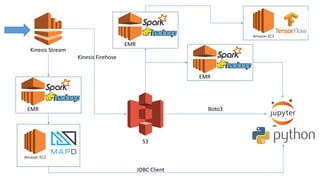





O documento discute como integrar times de Data Engineers e Data Scientists de forma efetiva. Ele propõe o uso de tecnologias como Python, Pyspark e MapD para análise e modelagem de dados, armazenados em HDFS e processados em clusters EMR na nuvem. A comunicação entre as equipes e o foco no objetivo comum de extrair insights dos dados são apontados como cruciais para o sucesso da colaboração.















































