Reducing Cache Misses in Hash Join Probing Phase by Pre-sorting Strategy
•
1 gostou•1,823 visualizações

SIGMOD'12 poster
Recomendados

Recomendados
Mais conteúdo relacionado
Destaque
Destaque (10)
Semelhante a Reducing Cache Misses in Hash Join Probing Phase by Pre-sorting Strategy
Semelhante a Reducing Cache Misses in Hash Join Probing Phase by Pre-sorting Strategy (20)
Mais de Jaemyung Kim
Mais de Jaemyung Kim (6)
Reducing Cache Misses in Hash Join Probing Phase by Pre-sorting Strategy
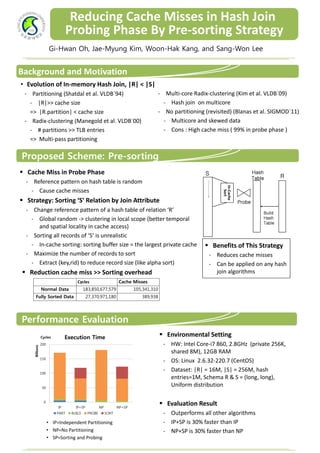
- 1. Reducing Cache Misses in Hash Join Probing Phase By Pre‐sorting Strategy Gi-Hwan Oh, Jae-Myung Kim, Woon-Hak Kang, and Sang-Won Lee Background and Motivation • Evolution of In‐memory Hash Join, |R| < |S| ‐ Partitioning (Shatdal et al. VLDB`94) ‐ Multi‐core Radix‐clustering (Kim et al. VLDB`09) ‐ |R|>> cache size ‐ Hash join on multicore => |R.partition| < cache size ‐ No partitioning (revisited) (Blanas et al. SIGMOD`11) ‐ Radix‐clustering (Manegold et al. VLDB`00) ‐ Multicore and skewed data ‐ # partitions >> TLB entries ‐ Cons : High cache miss ( 99% in probe phase ) => Multi‐pass partitioning Proposed Scheme: Pre-sorting Cache Miss in Probe Phase S Hash Table R ‐ Reference pattern on hash table is random In‐Cache ‐ Cause cache misses Sort Strategy: Sorting ‘S’ Relation by Join Attribute Probe ‐ Change reference pattern of a hash table of relation ‘R’ Build ‐ Global random ‐> clustering in local scope (better temporal Hash Table and spatial locality in cache access) ‐ Sorting all records of ‘S’ is unrealistic ‐ In‐cache sorting: sorting buffer size = the largest private cache Benefits of This Strategy ‐ Maximize the number of records to sort ‐ Reduces cache misses ‐ Extract (key,rid) to reduce record size (like alpha sort) ‐ Can be applied on any hash Reduction cache miss >> Sorting overhead join algorithms Cycles Cache Misses Normal Data 183,850,677,579 105,341,310 Fully Sorted Data 27,370,971,180 389,938 Performance Evaluation Cycles Execution Time Environmental Setting 200 ‐ HW: Intel Core‐i7 860, 2.8GHz (private 256K, Billions shared 8M), 12GB RAM 150 ‐ OS: Linux 2.6.32‐220.7 (CentOS) 100 ‐ Dataset: |R| = 16M, |S| = 256M, hash entries=1M, Schema R & S = (long, long), 50 Uniform distribution 0 IP IP+SP NP NP+SP Evaluation Result PART BUILD PROBE SORT ‐ Outperforms all other algorithms • IP=Independent Partitioning ‐ IP+SP is 30% faster than IP • NP=No Partitioning ‐ NP+SP is 30% faster than NP • SP=Sorting and Probing