Mais conteúdo relacionado
正则表达式 贪婪与惰性
- 1. 1. 量词的贪婪与惰性
惰性是从左往右匹配,第一个不匹配就再加第二个...
贪婪是先匹配整个字符串,然后从右往左,不匹配就舍去一个 ...
如:
HTML code
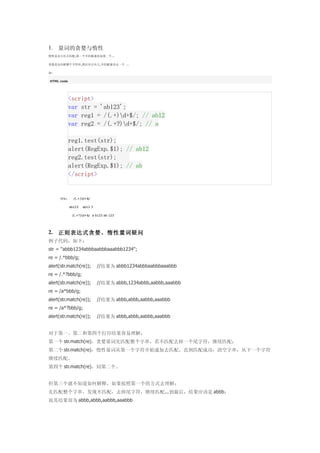
<script>
var str = 'ab123';
var reg1 = /(.+)d+$/; // ab12
var reg2 = /(.+?)d+$/; // a
reg1.test(str);
alert(RegExp.$1); // ab12
reg2.test(str);
alert(RegExp.$1); // ab
</script>
例如: /(.+)d+$/
ab123 ab12 3
/(.+?)d+$/ a b123 ab 123
2. 正则表达式贪婪、惰性量词疑问
例子代码,如下:
str = "abbb1234abbbaabbbaaabbb1234";
re = /.*bbb/g;
alert(str.match(re)); //结果为 abbb1234abbbaabbbaaabbb
re = /.*?bbb/g;
alert(str.match(re)); //结果为 abbb,1234abbb,aabbb,aaabbb
re = /a*bbb/g;
alert(str.match(re)); //结果为 abbb,abbb,aabbb,aaabbb
re = /a*?bbb/g;
alert(str.match(re)); //结果为 abbb,abbb,aabbb,aaabbb
对于第一、第二和第四个打印结果容易理解:
第一个 str.match(re),贪婪量词先匹配整个字串,若不匹配去掉一个尾字符,继续匹配;
第二个 str.match(re),惰性量词从第一个字符开始递加去匹配,直到匹配成功,清空字串,从下一个字符
继续匹配。
第四个 str.match(re),同第二个。
但第三个就不知道如何解释,如果按照第一个的方式去理解:
先匹配整个字串,发现不匹配,去掉尾字符,继续匹配...到最后,结果应该是 abbb;
而其结果却为 abbb,abbb,aabbb,aaabbb
- 2. 对 于 第 三 个 正 则 , 就 是 这 样 来 执 行 的 ;
首 先 清 楚 了 是 用 了 简 单 量 词 (*), 而 我 们 知 道 了 * 是 贪 婪 量 词 :
贪婪量词执行过程。正好楼主所说的那样。“先匹配整体,若不匹配则去掉尾字符继续匹配,直到成功或者
结 束 ”
这 样 说 应 说 只 能 得 到 第 一 被 匹 配 的 对 象 。
也 就 是 说 , 只 是 说 了 匹 配 第 一 个 。
(btw 如 C# 中 Regex 类中 match 方法是返回第一个匹配,而 matches 搜索正则表达式的所有匹配项)
对 于 javascript 中 的 match 来 说 。 正 如 C# 中 的 matches 一 样 , 返 回 所 有 匹 配 。
对 于 要 返 回 所 有 匹 配 。
它还有第二个步:就是匹配成功后,从最近的一个匹配后的下一个字符开始重新贪婪模式匹配。 重新执行
它 的 步 骤 ;
例 :
str = "abbb1234abbbaabbbaaabbb1234";
re = /a*bbb/g;
alert(str.match(re));
它 的 执 行 过 程 :
第 一 步 : 首 先 整 个 字 符 串 ("abbb1234abbbaabbbaaabbb1234") 匹 配 , 发 现 匹 配 不 成 功 ,
接 着 。 删 除 最 后 一 个 字 符 ("4"), 成 了 ("abbb1234abbbaabbbaaabbb123"), 这 样 依 次 执 行 下 去 ;
执 行。。 。 最 后 。 发 现 ("abbb") 可 以 被 匹 配 了。 。 所 以 生 成 第 一 个 匹 配 值 。
但 在 这 个 match 方 法 中 是 返 回 所 有 匹 配 。 所 以 ..
第二步:从最近的一个匹配(这里就是第一次匹配了)后的下一个字符开始重新贪婪模式匹配 .得到字符
串 是
("1234abbbaabbbaaabbb1234"), 然 后 。 就 按 第 一 步 执 行 。 。
执 行 完 第 一 步 后 。
然 后 就 从 最 近 一 次 ( 这 里 就 是 第 二 次 匹 配 了 )
....后面的过程就是重复一二步了 。
。