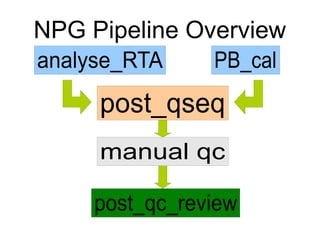
4. post_qseq
Produce per lane fastq
(qseq2fastq.pl)
Produce per lane srf
(illumina2srf & srf_index_hash)
Split out nonconsented data
Split fastqs by multiplex tag
qX_yield insert_size adapter sequence_error gc_fraction
8. Additional Notes
● Spider runs at the start and finish at the end of
all the pipelines.
● Spider caches web pages which are used
throughout the pipeline and sets an
environment variable, so that all launched jobs
can access them.
● Finish is very important, as it ties off the log
files, and writes a json string of the processes
launched, which is needed for the schema
generation.
9. Additional Notes
● Status changes have been left out, along with
some file checking and creation of tag specific
lane files which occur at the start of the primary
analysis pipelines. These happen, but are not
responsible directly for the files and qc that you
see.
● The production version of the primary pipeline
launches a version of the secondary pipeline
which creates a Latest_Summary link to it's
archival files and QC.
10. Additional Notes
● Status changes have been left out, along with
some file checking and creation of tag specific
lane files which occur at the start of the primary
analysis pipelines. These happen, but are not
responsible directly for the files and qc that you
see.
● The production version of the primary pipeline
launches a version of the secondary pipeline
which creates a Latest_Summary link to it's
archival files and QC.