

Recomendados
Mais conteúdo relacionado
Semelhante a Big Data Analytics
Semelhante a Big Data Analytics (20)
Big Data Analytics
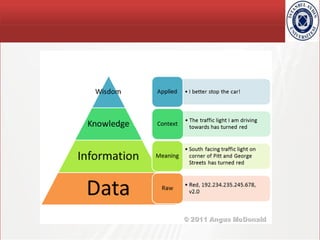
- 2. TÜBİTAK Data – Information – Knowledge - Wisdom
- 4. TÜBİTAK Büyük Veri Every minute of the day: YouTube receives 48 hours of uploaded video (~15 GB) Over 2 million search queries hit Google Twitter users post about 100,000 tweets 571 new websites are created Over 200,000,000 email messages are created and sent Estimates place the size of digital data the world over to be approaching 1.2 zettabytes; TB -> PB -> EB -> ZB -> YB .......... ?
- 7. TÜBİTAK Hadoop • Hadoop, sıradan sunuculardan (commodity hardware) oluşan küme (cluster) üzerinde büyük verileri işlemek amaçlı uygulamaları çalıştıran ve Hadoop Distributed File System (HDFS) olarak adlandırılan bir dağıtık dosya sistemi ile Hadoop MapReduce özelliklerini bir araya getiren, Java ile geliştirilmiş açık kaynaklı bir kütüphanedir • Daha yalın bir dille anlatmak gerekirse, Hadoop, HDFS ve MapReduce bileşenlerinden oluşan bir yazılımdır.
- 8. TÜBİTAK Hadoop HDFS • HDFS sayesinde sıradan sunucuların diskleri bir araya gelerek büyük, tek bir sanal disk oluştururlar. • Bu sayede çok büyük boyutta bir çok dosya bu dosya sisteminde saklanabilir. • Bu dosyalar bloklar halinde birden fazla farklı sunucular üzerine dağıtılarak RAID benzeri bir yapıyla yedeklenir. • Bu sayede veri kaybı önlenmiş olur.
- 9. TÜBİTAK Hadoop HDFS • Ayrıca HDFS çok büyük boyutlu dosyalar üzerinde okuma işlemi (streaming) imkanı sağlar. • Ancak rastlantısal erişim (random access) özelliği bulunmaz. • HDFS, NameNode ve DataNode proseslerinden oluşmaktadır.
- 10. TÜBİTAK Hadoop HDFS - NameNode • NameNode ana (master) proses olarak blokların sunucular üzerindeki dağılımınından, yaratılmasından, silinmesinden, bir blokta sorun meydana geldiğinde yeniden oluşturulmasından ve her türlü dosya erişiminden sorumludur. • Kısacası HDFS üzerindeki tüm dosyalar hakkındaki bilgiler (metadata) NameNode tarafından saklanır ve yönetilir. • Her kümede yalnızca bir adet NameNode olabilir.
- 11. TÜBİTAK Hadoop HDFS - DataNode • DataNode ise işlevi blokları saklamak olan işçi (slave) prosestir. Her DataNode kendi yerel diskindeki veriden sorumludur. • Ayrıca diğer DataNode’lardaki verilerin yedeklerini de barındırır. DataNode’lar küme içerisinde birden fazla olabilir.
- 12. TÜBİTAK Hadoop MapReduce • Hadoop MapReduce HDFS üzerindeki büyük dosya verilerini işleyebilmek amacıyla kullanılan bir yöntemdir. • İstediğiniz verileri filtrelemek için kullanılan Map fonksiyonu ve bu verilerden sonuç elde etmenizi sağlayan Reduce fonksiyonlarından oluşan program yazıldıktan sonra Hadoop üzerinde çalıştırılır. • Hadoop Map ve Reduce’lerden oluşan iş parçacıklarını küme üzerinde dağıtarak aynı anda işlenmesini ve bu işler sonucunda oluşan verilerin tekrar bir araya getirilmesinden sorumludur.
- 13. TÜBİTAK Hadoop MapReduce • Hadoop’un gücü işlenen dosyaların her zaman ilgili düğümün (node) yerel diskinden okunması ile ağ trafiğini meşkul etmemesinden ve birden fazla işi aynı anda işleyerek doğrusal olarak ölçeklenmesinden geliyor diyebiliriz.
- 14. TÜBİTAK Hadoop
- 15. TÜBİTAK Hadoop MapReduce • Aşağıdaki grafikte olduğu gibi Hadoop kümesindeki düğüm sayısı arttıkça performansı da doğrusal olarak artmaktadır.
- 16. TÜBİTAK Hadoop • Hadoop şu anda Yahoo, Amazon, eBay, Facebook, Linkedin gibi birçok lider firmada büyük verileri analiz etmek amacıyla kullanılıyor. • Hadoop projesi aynı zamanda büyük verileri işleme konusundaki diğer projelere bir çatı görevi görüyor.
- 17. TÜBİTAK Hadoop Alt Projeleri • Hadoop projesinin altında • Avro (veri dizileştirme (serialization) sistemi), • Cassandra (yüksek erişilebilir, ölçeklenebilir NoSQL veritabanı), • HBase (Hadoop üzerinde çalışan, büyük veriler için ölçeklenebilir, dağıtık NoSQL veritabanı), • Hive (büyük veriler üzerinde iş zekası sistemi),
- 18. TÜBİTAK Hadoop Alt Projeleri • Hadoop projesinin altında • Mahout (ölçeklenebilir yapay öğrenme (machine learning) ve veri madenciliği kütüphanesi), • Pig (paralel hesaplamalar için yüksek düzeyli bir veri akışı dil ve yürütme kütüphanesi), • ZooKeeper(dağıtık uygulamalar için yüksek ölçekli koordinasyon uygulaması) projeleri geliştiriliyor.
- 19. TÜBİTAK Hadoop
- 21. TÜBİTAK Büyük Veri • Büyük veri bir ürün değildir • Belli bir plana göre icra edilen işlemler bütünüdür
- 22. TÜBİTAK Hacking/Cracking • Büyük veri işlemleri kimi zaman mahremiyete saldırı amacıyla da kullanılabilir
- 23. TÜBİTAK Profil Çıkarımı / Öngörü Modellemesi
- 24. TÜBİTAK Derin Öğrenme / Deep Learning İnsan Beyninde 86 milyar nörön, 1.000-5.000 sinapsis
- 25. TÜBİTAK Riskler • Paradokslar • Şeffaflık Paradoksu • Kimlik Paradoksu • Güç Paradoksu • Önleyici öngörü problemleri • Nötr sınıflandırma yanılsaması
- 26. TÜBİTAK Riskler • Paradokslar • Şeffaflık Paradoksu • Büyük verinin girdilerini oluşturan veriler küçük/sınırlı veriler olup pahalı/güvenli alt yapılarda çoğunlukla da kapalı tutulurken, büyük veri işlemlerinin şeffaflık gereksinimi nedeniyle daha düşük maliyetli alt yapılarda işlenirler. • Büyük resmin daha net ortaya konabilmesi için şeffaflık büyük veri sistemlerinin olmazsa olmaz gereksinimidir • Kişisel sağlık bilgileri mahrem bilgilerdir. Ancak hastalıkların tanımlanmasında, nedenlerinin araştırılmasında, teşhis ve tedavisinde bu bilgilerin belli bir detayda toplanıp büyük veri analizi işlemlerine tabi tutulması elzemdir.
- 27. TÜBİTAK Riskler • Paradokslar • Birey Paradoksu • Bireye özgü servislerin geliştirilebilmesi ve verilebilmesi için bireye özgü birçok bilgi verilmek zorunda kalınır. • Güç Paradoksu • Büyük veriyi yönetme, yönlendirme ve işleme gücü büyük veriden en çok yararlanan geniş kitlelerin elinde değildir
- 28. TÜBİTAK Riskler • Önleyici öngörü problemleri • Önlenecek tehlikenin yeterince tanımlanmaması • Tehlikelerin çeşitliliği, karmaşıklığı (virüs, spam, ..) • Kara listenin eksik yada fazla öğeler içermesi • Nötr/nesnel sınıflandırma yanılsaması • Sınıflandırmalar, nesnel kurallar ve karar verme mekanizmalarına göre değil, sınıflandırma yapan tarafın önceliklerine göre yapıldığı için, kişisel bilgileriniz taraflı sınıflandırmaların malzemesi olabilir (ör. firmaların reklamlarına göre olduğunuzdan farklı gruplarda gösterilmeniz – ürünü inceleyenlerin ürünü alanlar grubunda gösterilemsi)
- 29. TÜBİTAK Çözüm Yöntemleri • Problem 1: Büyük Veri platformunun güvenilir olduğu varsayımı • Analizlerin bireylerle ilgili çok fazla bilgiyi ifşa etmediğinden nasıl emin olunacak ? • Genel sorguların doğruluğunu maksimize ederken sorgu için kullanılan bireysel bilgilerin tanımlanmasının minimize edilmesi (Differential Privacy) • Mahremiyet Korumalı Veri Madenciliği teknikleri kullanılmalı (Privacy Preserving Data Mining)
- 30. TÜBİTAK Çözüm Yöntemleri • Problem 2: Büyük Veri platformunu uygun bilgi normlarına uymaya zorlayacak ve bu normlara uygunluğunu denetleyecek biçimde nasıl tasarlanabilir ? • Uçtan uca şifreleme, • Korumalı multi-part hesaplama, • Trusted cells
- 38. TÜBİTAK İsimlendirme • İsimlendirme sistem tasarımında hayati öneme sahiptir • Birçok farklı alanda farklı isimlendirme standartları vardır
- 42. TÜBİTAK İsimlendirme Örnekler Key constraint Name space: key attribute values (Öğrenci ID’lerinin alabileceği değerler , 1000-9999 gibi) Universe of values: tuples in a table (Mevcut öğrencilerin ID’leri) Name mapping algorithm: Index (Öğrenci ID’ler öğrenci nesnesine haritalar) Context: A given table (Bilgisayar Mühendisliği öğrencileri)
- 43. TÜBİTAK İsimlendirme Örnekler Sequence Id Name space: sequence of integers Universe of values: tuples in a relation Name mapping algorithm: Index Context: A given table
- 44. TÜBİTAK İsimlendirme Örnekler DNS • DNS, 256 karaktere kadar büyüyebilen host isimlerini IP’ye çevirmek için kullanılan bir sistemdir. • Host ismi, tümüyle tanımlanmış isim (full qualified name) olarak da bilinir ve hem bilgisayarın ismini hem de bilgisayarın bulunduğu Internet domainini gösterir (atakan.aydin.edu.tr) • DNS , verilen bir makina adından IP adresini çözerek Internet üzerinde host isimleri ile haberleşmelerine olanak tanır
- 45. TÜBİTAK İsimlendirme Örnekler DNS’in yapısı • DNS sistemi isim sunucuları ve çözümleyicilerinden oluşur. • İsim sunucuları olarak düzenlenen bilgisayarlar host isimlerine karşılık gelen IP adresi bilgilerini tutarlar. • Çözümleyiciler ise DNS istemcilerdir. • DNS istemcilerde, DNS sunucu yada sunucuların adresleri bulunur. • Bir DNS istemci bir bilgisayarın ismine karşılık IP adresini bulmak istediği zaman isim sunucuya başvurur. • İsim sunucu, yani DNS sunucu da eğer kendi veritabanında öyle bir isim varsa, bu isme karşılık gelen IP adresini istemciye gönderir.
- 47. TÜBİTAK İsim Haritalandırma Algoritmaları • Fiziksel Kimlikleyiciler (Identifiers) • İsim değerin lokasyonunu içerir • Memory adresleri gibi • Mantıksal Kimlikleyiciler (Identifiers) • Table Lookup • Page Table yada DB indeksi gibi
- 49. TÜBİTAK Kimlikleyiciler (Identifiers) • Büyüklük • Karakter sayısı • Her karakterin tipi • Teklik • Sequence + concurrency control • partitionning • locking • Random/time stamped sequence + collision detection
- 51. TÜBİTAK Ontoloji • Soru: Bir arama motoru çalıştırıyorsunuz, birden fazla anlama gelen kelimelerle ilgili nasıl bir arama yapmanız gerekiyor ? (bug – tahta kurusu mu, yoksa program hatası mı?)
- 52. TÜBİTAK Ontoloji • Cevap: • Anlamsal denk varlıkların gruplandırılması Örnek: Wordnet
- 53. TÜBİTAK Analmsal Ağ (Semantic Web) • Amaç belirli bir problem uzayındaki kavramları, terimleri ve bağlantıları formal bir biçimde ifade etmek ve böylelikle makineler tarafından kullanılabilmesini/işlenmesini sağlamaktır. • Tüm anlamsal web uygulamalarının temelinde ontoloji kullanımı bulunmaktadır. • Ontoloji, herhangi bir alana ait kavramsal modelin, açık ve biçimsel tanımıdır. • Kavramsallaştırma biçimseldir, dolayısı ile bilgisayar tarafından anlaşılabilir. • İkincisi ise, ontoloji herhangi bir ilgi alanı için tasarlanır.
- 54. TÜBİTAK Analmsal Ağ (Semantic Web) • Ontolojiler kavramlar (sınıflar), ilişkiler (nitelikler), olgular ve aksiyomlardan oluşur. • Öğrenci -> Sınıf • Ders Alır -> İlişki • Matematik -> Olgu • «Öğrenci sınıfı , insan sınıfının bir alt sınıfıdır» -> Aksiyom
- 55. TÜBİTAK Analmsal Ağ (Semantic Web) Anlamsal ağ araçları XML yapılandırılmış dokümanlar için yüzeysel sözdizim kuralları sağlar. Fakat dokümanın anlamı ile ilgili anlamsal kısıt yüklemez. XML Şema, XML dokümanlarının yapı ve içerik elemanlarını düzenlemeye yarayan bir dildir. RDF nesnelere (resources) ve bu nesnelerin nasıl ilişkili olduğuna işaret eden bir veri modelidir. RDF temelli model XML sözdiziminde ifade edilebilir. OWL, ontolojileri tanımlamak ve çeşitlemek için kullanılan bir dildir SPARQL, Sematik Ağ veri kaynakları için bir protokol ve sorgulama dilidir.
- 56. TÜBİTAK Ontoloji
- 57. TÜBİTAK Veri Kalitesi • Büyü Veri Yönetimi boyunca devam eden süreç: – Veri katliesi değerlendirilir – Veri temizlenir • Ne zaman: – Bir veri kaynağı büyük veri kaynağına entegre edilirken – Veri analizine hazırlanılırken • Büyük veri kaynağının hangi kısmı seçilmeli ?
- 58. TÜBİTAK Veri Kalitesinin Boyutları • Accuracy: Doğru mu yanlış mı ? • Completeness: Tam mı? • Consistency: Tutarlı mı ? • Timeliness: Ne kadar güncel? • Believability: Ne kadar güvenilir? • Interpretability: Anlaşılır mı? Problemler: ① Veri kalitesi hatalarını tanımlamak ② Veri kalitesini artırmak
- 59. TÜBİTAK Hata Kaynakları • Veri giriş hataları: – İnsandan kaynaklanan yazım hatası – Arayüz tutarlılık kontrolünü bypass etmek için gelişi güzel veri girişi • Doğum günü olarak 11/11/11 tarihini girmek gibi • Ölçüm hataları: – Sensör hataları, konfigürasyon hataları • Hesaplama hataları: – Özet/toplam işlemlerindeki hesaplama hataları • Veri entegrasyon hataları: – Veri kaybı, kaynakların birleştirilmesi sırasındaki hatalar
- 60. TÜBİTAK Veri Kalitesini artırma • Daha iyi arayüz – Veri girişi • Yanlış anlamaya yada anlamamaya mahal vermeyecek şekilde veri girişinin sağlanması – Veriyi görselleştirme • Keşfe dayalı veri analizi • Veri profilleme • Organizasyonel Prensipler – Kalite yönetimiQuality management – Verinin bilimsel olarak üretilmesi ve çoğaltılması • Otomatik denetleme/temizleme – Eksik veri, gürültülü veri, tutarsız veri – Veri kaynağının takibi
- 61. TÜBİTAK Veri Temizleme • Kuantitatif Veri – Problemler: (i) «Outlier» verinin tanımı ve tespiti (ii) Birim çevirme hatalarının tespiti • Eksik Veri • Outlier/Anomaliler • Kategorik Veri – Problem: Farklı kategorileri homojen bir isim uzayına haritalama – Posta addresi Problemi: (i) Tekrarların tutarlı/tam olduğundan emin olma, (ii) Tekrarları ayıklama • Eksik Veri • Yazım Hataları • Yanlış sınıflandırma • Belirleyiciler – Problem: Belirleyicilerin ayrık nesneleri için tekrar kullanılma kısıt ve prosedülerinin tanımlanması • Referential integrity
- 62. TÜBİTAK ① Eksik Veri • Yapısal veri içinde İyi tanımlanmış desenler: – Ör.., csv dosyasındaki “,,” : • 234,,”some text” • Yarı-yapısal veri içindeki eksik özellik belirleyicileri: – e.g., anahtar değer çiftlerinde bir özelliğin anahtarının olmaması gibi
- 63. TÜBİTAK ② Eksik Veri • Veri nesnesini tamamen yoksay • Eksik değeri doldur – Kategorik veriler için • Genel sabit atayarak : ör., “unknown” – Kuantitatif veriler • Bütün verilerin Mean değeri alınarak atama yapma • Aynı veri nesnesi sınıfındaki verilerin ortalaması alınarak değer atama • Karar ağacı veya Bayesian formüllerle veri türetip eksik veriye değer atama
- 64. TÜBİTAK Karar Ağacı Eğitim veri seti Eksik verili satırlar: (40, ,) (25, M,)(26,,)
- 66. TÜBİTAK Veri Kalitesi • Accuracy: Outlier detection: Statistics / Machine Learning • Completeness: Pattern matching • Consistency: Referential integrity • Timeliness: Outlier detection (güncelleme için baseline vererek) • Believability: Quality Management • Interpretability: Natural language processing
- 67. TÜBİTAK Veri Temizleme • Ana iş: – Eksik veri, Outlier/Anomali denetimi • 2 yaklaşım var: – İstatistik: • Mean – Makine Öğrenme: • Karar Ağacı, Bayesian Network, Neural network, ...
- 68. TÜBİTAK Görselleştirme • Veri setinin içeriğini inceleme/denetleme – Düzensizlikleri bulma (veri temizleme için) – Desen arama
- 69. TÜBİTAK Görsel Çözümleyiciler Bilgi yoğunluğu ekran büyüklüğüne bağlıdır: – Mobil cihazlar < Desktop < Büyük ekranlar Prensipler: – Dinamik arayüzler: Overview, zoom & filter, details-on-demand
- 72. TÜBİTAK Çoklu Değişken Spotfire / Tableau
- 73. TÜBİTAK Çoklu Değişken • World Bank Climate Variability Tool
- 75. TÜBİTAK Spatio-Temporal Energy Consumption at Berkeley
- 77. TÜBİTAK Tree
- 79. TÜBİTAK Temel Prensipler • Bir veri setini nasıl karakterize edeceğiz? – Veri setindeki eleman sayısı – Boyutlar (özellik adları , tipleri) – Örnekler – Özetler: • Her boyut için: Farklı değer sayısı, eksik değer sayısı, dağılım, istatistikler, ör. : – Merkezi eğilimler: mean / median / mode » Dağılıma bağlı olarak symetric / skewed / bimodal
- 81. TÜBİTAK İstatiksel Görselleştirme • Tek değişkenli veri – İstatiksel dağılım tek bir değişken üzerine inşa edilir • Boxplot: median, min/max/quantiles • violin plot: boxplot + probability density • Çok değişkenli veri – Volume rendering – Plot-Windows – Parallel coordinates – Spider plot
- 82. TÜBİTAK Örnekler © Philippe Bonnet 2014 Her grafik için bir tanımlama yapılıyor: 1. Ne tip bir grafik olacak? 2. Kategorik/Kuantitatif veri nasıl gösterilecek? 3. Grafik bütün veriyi mi işaretliyor olacak yoksa istatistiksel bir temsilini mi? 0.1 1 10 100 100 200 300 400 500 IO number Responsetime(ms) rt Avg(rt) Avg(rt) o-o-b 0.1 1 10 100 100 200 300 400 500 IO number Responsetime(ms) rt Avg(rt) Avg(rt) o-o-b
- 83. TÜBİTAK Siz bir Analistsiniz • Veri keşfi aşamasına geldiniz • Şimdi input veri içinde madencilik yapacaksınız: – output: Descriptive (patterns) / Predictive (model) – method: Supervised / Un-supervised • Soruları tanımlamalı/cevaplamalısınız: – Regression: nesneler arasında ilişkiyi tanımlar – Clustering: birbirine benzer nesne gruplarını bulur – Classification: bir nesnenin hangi gruba ait olduğunu bulur
- 84. TÜBİTAK Örnekler • Farklı yaşlardaki müşterilerin satın alma davranışları nasıldır ? – Müşteri satın alma hareketlerinin toplandığı geniş bir kümeden satın alma hareketlerinin tarihçelerine erişebilmelisiniz • Daha gerçekçi: Hangi aileler ısı pompası kullanıyor – 1 saatlik zaman birimi seviyesinde son bir kaç yılın elektrik tüketimine (hane bazlı) erişebilmelisiniz
- 85. TÜBİTAK Boyut Sorunu • Problem: Düşük değerde çok fazla yüksek değerde çok az veri olması – Nesnelerinizin d tane özelliği olduğunu farz edin – Nesneleriniz d-boyutlu uzayda noktalar şeklinde temsil edilebilir – Özellikler dolayısıyla boyut olarak görülebilir – Boyut arttıkça uzayın hacmi artar ve nesneler dağınık ve seyrek hal alırlar • İstatistiksel belirginlik sağlama zorlaşır • Benzerliklerin tespiti zorlaşır • Çözüm: Özellik seçimi – Bir analiz görevinde, boyut indirgemesi için uygun özelliklerin bir alt kümesi seçilmelidir © Philippe Bonnet 2014
- 86. TÜBİTAK Özellik Seçimi (Feature Selection) • Verilen bir veri seti için tanımlanan bir analiz görevinde: – Bütün özelliklere bir skor verin – Bunları yüksek skorludan itibaren belirlenen skor eşiğine kadar topla • Özellik Skorlama – Information Gain (Entropy)
- 87. TÜBİTAK Boyut İndirgeme • Principal Component Analysis (PCA): • Shape-Based Feature extraction (Image Processing) – Thresholding – Edge detection • Belirsiz(Gizli) değişkenler – Çok sayıfa değişkenin az sayıda gizli (direkt olarak ölçülemeyen) değişkenle ilişkilendirimesi için geliştirilen modeller – Türetilen gizli değişkenler: factor analysis, hidden markov model
- 88. TÜBİTAK Algoritmalar • Input: Veri Seti • Output: – Cluster’lar – Karar Ağaçları – Matematiksel Modeller – Kural Kümeleri • Algoritma Tipleri – Regression, clustering, classification – Association rules – Sequence analysis
- 89. TÜBİTAK Görev ve Algoritmalar • Kategorik özellikleri öngörme – Decision tree, Neural network, Bayes network, Clustering algorithm • Kuantitatif özellikleri öngörme – Linear regression, Time series algorithms • Serileri öngörme – Sequence clustering • Ortak item grupları – Decision tree, Association rules • Benzer item grupları – Clustering, Sequence clustering
- 90. TÜBİTAK Referans Algoritma #1 – k means • Kümelem algoritması: – Başlangıç: k (herhangi bir) noktayı k kümenin centroid’i olarak al – Yakınsayıncaya kadar yineler • step 1: her noktayı en yakın centroid’in kümesine ata (euclidian) • step 2: her küme için step 1’deki atamalara göre bir centroid hesapla
- 91. TÜBİTAK Veri Ambarı Nedir? • Organizasyonun işlemsel veri tabanından ayrı olarak düşünülen bir karar destek veri tabanıdır. • “Veri ambarı özneye dayalı, bütünleşmiş, zaman dilimli ve yöneticinin karar verme işleminde yardımcı olacak biçimde toplanmış olan değişmeyen veriler topluluğudur. ” —W. H. Inmon
- 92. TÜBİTAK Data Warehouse—Özneye Dayalı • Bir veri ambarı, tüketici, tedarikçi firma, ürün ve satış gibi önemli özneler etrafında kurulur. • Veri ambarı bir organizasyonun her güne ait işleri ve hareket işleme faaliyetleri üzerinde yoğunlaşmak yerine karar verecek kimseler için veriye ait modelleme ve analiz üzerinde yoğunlaşır. • Veri ambarları karar destek sürecinde faydalı olmayan veriyi dışarıda tutarak basit ve öz bir bakış sağlar.
- 93. TÜBİTAK Data Warehouse—Tümleşik • Bir veri ambarı genellikle ilişkisel veri tabanları, dosyalar ve çevrim içi işlem kayıtları gibi çeşitli farklı türde (heterojen) dosyaları bütünleştirerek oluşturulur. • Veri temizleme ve veri tümleme teknikleri, isimlendirmede, nitelik ölçütlerinde ve benzeri konularda tutarlılığı garantilemek için uygulanır.
- 94. TÜBİTAK Data Warehouse—Zaman Dilimli • Veriler tarihi bir bakış açısından bilgi sağlamak için depolanır(örn: 5-10 yıllık geçmiş içerisinden).
- 95. TÜBİTAK Data Warehouse—Değişmeyen • Veri ambarı hareket işlemeyi (transaction processing), geri almayı (recovery), ve rastlantısal kontrol (concurrency control) mekanizmalarını gerektirmez. • Veriye erişim için çoğunlukla sadece iki işlem gerektirir: – verinin ilk yüklemesi – verinin erişimi
- 96. TÜBİTAK Özetle • Veri ambarı – stratejik kararları verme konusunda bir kurumun ihtiyacı olan bilgiyi depolayan – karar destek veri modelinin fiziksel bir sunumu gibi çalışan, – anlamsal olarak tutarlı bir veri deposudur. • Veri ambarı aynı zamanda yapısal ve/veya planlanmamış (ad hoc) sorgular, analitik raporlar ve karar vermeyi desteklemek için çeşitli farklı türde kaynaklardan veriyi bütünleştirerek oluşturulan bir mimari olarak da görülür.
- 97. TÜBİTAK Veri Ambarları ve İşlemsel Veritabanı Sİstemleri Arasındaki Farklar • Çevrim içi işlemsel veri tabanları sistemlerinin önemli bir görevi, çevrim içi işlemeyi ve sorgulamayı gerçekleştirmektir. – Bu sistemlere çevrim içi hareket işleme sistemleri (on- line transaction processing OLTP) denir. – Bu sistemler bir organizasyona ait alım, envanter, imal- yapım, bankacılık, ücret bordrosu, kayıt ve hesaplama gibi bir organizasyona ait günlük işlemlerin çoğunu karşılamaktadır. • Öte yandan veri ambarı sistemleri kullanıcılara veya bilgi çalışanlarına, veri analizi ve karar verme rolü içerisinde hizmet eder. – Böyle sistemler, farklı kullanıcıların çeşitli ihtiyaçlarına yer vermek amacıyla veriyi değişik formatlarda gösterebilir ve organize edebilir. – Bu sistemler, çevrim içi analitik işleme sistemleri (on-line analytical processing OLAP) olarak bilinirler.
- 98. TÜBİTAK OLTP ve OLAP • Kullanıcılar ve sistem yönelimi: – OLTP sistemi müşteri merkezlidir: • Bilgi teknolojisi uzmanları, satıcılar ve müşteriler tarafından işlemsel bilgi ve sorgulama için kullanılır. – OLAP sistemi pazar merkezlidir: • Analistleri, uzmanları ve yöneticileri içine alan bilgi çalışanları tarafından veri analizi için kullanılır. • Veri İçerikleri: – OLTP sistemi, tipik olarak karar vermede kolayca kullanılmak için fazla detaylı olan güncel veriyi yönetir. – Bir OLAP sistemi, büyük miktarlarda tarihi veriyi yönetir, özetleme ve toplamada kolaylıklar sağlar ve öğe boyutunda farklı seviyelerindeki bilgiyi saklar ve yönetir. Bu özellikler veriyi karar vermede kullanabilmek için daha kolay bir hale getirir. • Veritabanı Tasarımı: – OLTP sistemi genelde varlık-bağıntı (entity-relationship ER) veri modelini ve uygulama merkezli veritabanı tasarımını seçer. – OLAP sistemi,tipik olarak ya yıldız yada kar tanesi modelini ve özne merkezli bir veri tabanı tasarımını tercih eder.
- 99. TÜBİTAK OLTP ve OLAP • İnceleme: – OLTP sistemi bir kurum veya bölüm içerisindeki bir güncel veriye, tarihi veriyi veya farklı organizasyonlardaki veriyi kapsamadan, temel olarak odaklanır. – OLAP sistemi genellikle bir veritabanı şemasının çoklu versiyonlarını tararken, bir organizasyonun evrimsel sürecine bağlı olarak, aynı zamanda pek çok veri deposundan bilgi tümleme sonucunda kaynağı farklı organizasyonlardan başlayan bilgiyle ilgilenir. Büyük hacimlerinden dolayı, OLAP verileri çoklu saklama ortamlarında depolanır. • Erişim Desenleri: – OLTP sisteminin erişim desenleri temel olarak kısa, basit(atomik) işlem bilgilerden oluşur. Böyle bir sistem uyumluluk kontrolü ve kurtarma mekanizmaları gerektirir. – Bununla birlikte, OLAP sistemlere erişim, pek çoğunun karmaşık sorgu olabilecek olmasına karşın çoğunlukla salt okunur işlemler (çoğu veri ambarının güncel bilgi yerine tarihi bilgiyi depolaması nedeniyle) şeklindedir.
- 100. TÜBİTAK OLTP vs. OLAP OLTP OLAP users clerk, IT professional knowledge worker function day to day operations decision support DB design application-oriented subject-oriented data current, up-to-date detailed, flat relational isolated historical, summarized, multidimensional integrated, consolidated usage repetitive ad-hoc access read/write index/hash on prim. key lots of scans unit of work short, simple transaction complex query # records accessed tens millions #users thousands hundreds DB size 100MB-GB 100GB-TB metric transaction throughput query throughput, response
- 101. TÜBİTAK Neden Ayrı Bir Veri Ambarı Gerekli? • DBMS: erişim yöntemleri, birinci anahtarı kullanarak indeksleme, özel kayıtları araştırma ve sorguları optimize etme gibi bilinen görev ve iş yüklerinden hareketle tasarlanır ve ayarlanır. • Öte yandan veri ambarı sorguları sıklıkla karmaşıktır. Özetlenmiş seviyelerdeki verilerin büyük gruplarının hesaplanması ile ilgilenir, ve özel veri organizasyonu, erişim ve çok boyutlu incelemeye dayanan sunum yöntemleri gerektirebilir. • OLAP sorgusu sıklıkla, kümeleme ve özetleme için veri kayıtlarına salt okunur erişime ihtiyaç duyar. • İşlemsel veritabanlarının veri ambarlarından ayrılması işlemi, bu iki sistem içerisindeki farklı yapılar, içerikler ve veri kullanımları üzerine kurulmuştur. • Karar destek için tarihi bilgi gerekli iken, işlemsel veritabanları tipik olarak tarihi veriye bakmaz. Bu bağlamda, işlemsel veritabanlarındaki veri çok olmasına rağmen, karar verme için gereken tamlıktan uzaktır. • Karar destek, heterojen kaynaklardan gelen verinin birleştirilmesine(kümeleme ve özetleme gibi) ve sonuç olarak yüksek kalitede, temiz ve tümleşik veriye ihtiyaç duyar. • Karşıt olarak, işlemsel veritabanları sadece hareketler gibi analizden önce birleştirilmeye ihtiyacı olan ,detaylı ham veri içerirler.
- 102. TÜBİTAK Tablodan Veri Küplerine Doğru • “Veri küpü nedir?” – Veri küpü verinin çoklu boyutta modellenmesini ve incelenmesini sağlar. – Boyutlar ve bilgiler ile tanımlanır. • boyutlar, organizasyonun kayıtlarını tutmak istediği perspektifler veya varlıklar ile ilgilidir. • Örnek olarak mağazanın zaman, adet, şube ve yer ile ilgili satış kayıtlarını tutmak için bir satış veri ambarı kurabilir. • Bu boyutlar mağazaya, aylık satışların adedi, şubeleri ve parçaların satıldığı yerler gibi kayıtların izinin tutulmasına imkan verir. • Her boyut, boyut tablosu denen, boyutu daha detaylı anlatan bir ilgili tabloya sahip olabilir. • Örnek olarak, bir parça için boyut tablosu parça adı, marka ve tip niteliklerini içerebilir. Boyut tabloları kullanıcılar veya uzmanlar tarafından belirtilebilir veya veri dağıtımları temel alınarak otomatik olarak yaratılabilir ve uyarlanabilir.
- 103. TÜBİTAK Cube time,item time,item,location time, item, location, supplier all time item location supplier time,location time,supplier item,location item,supplier location,supplier time,item,supplier time,location,supplier item,location,supplier 0-D(apex) cuboid 1-D cuboids 2-D cuboids 3-D cuboids 4-D(base) cuboid
- 105. TÜBİTAK
- 106. TÜBİTAK
- 107. TÜBİTAK
- 108. TÜBİTAK
- 109. TÜBİTAK Veri Ambarı Modelleri • Veri ambarı için en popüler veri modeli, çok boyutlu modeldir. • Çok boyutlu veri modeli – yıldız şema, – kar tanesi şema – olgu takımyıldızı
- 110. TÜBİTAK Yıldız Şema • En çok bilinen modelleme örneği • İçerisinde veri ambarının içerdiği en önemli veri kısmını gereksiz fazlalık olmadan içinde bulunduran büyük bir merkezi tablo (olgu tablosu) • her biri bir boyut için olmak üzere küçük yardımcı tablolar kümesi (boyut tabloları) bulunduran yıldız şemadır. • Şema çizgesi, merkezi olgu tablosunun etrafında merkezden çıkan bir desen içerisinde gösterilen boyut tabloları ile, yıldız yapısına benzer.
- 111. TÜBİTAK Örnek Yıldız Şema time_key day day_of_the_week month quarter year time location_key street city state_or_province country location Sales Fact Table time_key item_key branch_key location_key units_sold dollars_sold avg_sales Measures item_key item_name brand type supplier_type item branch_key branch_name branch_type branch
- 112. TÜBİTAK Kar Tanesi Şema • Kar tanesi şema, bazı boyut tablolarının normalize edildiği, bundan dolayı verinin ek tablolara doğru ileri bölündüğü, yıldız şema modelinin değişik bir biçimidir. • Sonuç şema çizgesi kar tanesine yakın bir şekil oluşturur. • Kar tanesi ve yıldız şema modelleri arasındaki önemli fark kar tanesi modelinde boyut tablolarının gereksiz fazlalıkları azaltmak için normalize edilmiş formda saklanabilir olmasıdır. • Böyle bir tabloyu yönetmek kolay ve kayıt yerinden tasarruf etmeyi sağlar çünkü büyük bir boyut tablosu, boyutsal yapı olarak sütunlar içerdiğinde devasa hale gelebilir. • Bunun yanında yerden kazanç sağlama, olgu tablosunun tipik büyüklüğü ile karşılaştırıldığında önemsizdir. • Dahası kar tanesi yapısı, bir sorguyu işletmek için daha çok katılım gerekli olacağından, tarama-gözden geçirme performansının etkinliğini de düşürebilir. • Sonuç olarak, sistem performansı ters biçimde etkilenebilir. Bundan dolayı, veri ambarı tasarımında kar tanesi şema, yıldız şema kadar popüler değildir.
- 113. TÜBİTAK Örnek Kartanesİ Şema time_key day day_of_the_week month quarter year time location_key street city_key location Sales Fact Table time_key item_key branch_key location_key units_sold dollars_sold avg_sales Measures item_key item_name brand type supplier_key item branch_key branch_name branch_type branch supplier_key supplier_type supplier city_key city state_or_province country city
- 114. TÜBİTAK Olgu Takımyıldızı Şema • Karmaşık uygulamalar boyut tablolarını paylaşmak için çoklu olgu tabloları gerektirebilir. • Bu çeşit bir şema yıldızların toplamı olarak görülebilir ve bundan dolayı adına galaksi şema veya olgu takımyıldızı denir.
- 115. TÜBİTAK Örnek TakımyIldızı Şema 26 time_key day day_of_the_week month quarter year time location_key street city province_or_state country location Sales Fact Table time_key item_key branch_key location_key units_sold dollars_sold avg_sales Measures item_key item_name brand type supplier_type item branch_key branch_name branch_type branch Shipping Fact Table time_key item_key shipper_key from_location to_location dollars_cost units_shipped shipper_key shipper_name location_key shipper_type shipper
- 116. TÜBİTAK A Concept Hierarchy: Dimension (location) all Europe North_America MexicoCanadaSpainGermany Vancouver M. WindL. Chan ... ...... ... ... ... all region office country TorontoFrankfurtcity
- 117. TÜBİTAK A Sample Data Cube Total annual sales of TV in U.S.A.Date Country sum sum TV VCR PC 1Qtr 2Qtr 3Qtr 4Qtr U.S.A Canada Mexico sum
- 118. TÜBİTAK Veri Küpü oluşturma-örnek • Market satış verileri • Zaman-reyon satış verisi
- 119. TÜBİTAK • Yönetici zaman-ürün boyutuna şube boyutunu ekleyerek sonuçları görmek istiyor.
- 120. TÜBİTAK
- 121. TÜBİTAK Verİ küpünü oluşturan küboidler
- 122. TÜBİTAK Tipik OLAP Operasyonları • Roll-up: Bu operasyon (bazı satıcılar tarafından drill-up operasyonu olarak da adlandırılır.) ya bir boyut için kavram hiyerarşisinin tepesine tırmanarak, yada boyut azaltımı ile bir veri küpünde kümeleme işlemi gerçekleştirir. • Roll up işlemi boyut azaltımı ile birlikte yapıldığında verilen küpten bir veya daha çok boyut silinir. Örnek olarak sadece yer ve zaman boyutları bulunan bir satışlar veri küpü düşünelim. Roll up işleminin zaman boyutunu sildiğini farz edelim, bu durumda toplam satışlar yer ve zamana göre kümelenmek yerine, sadece yere göre kümelenecektir.
- 123. TÜBİTAK Roll-Up
- 124. TÜBİTAK Tipik OLAP Operasyonları • Drill-down : Roll-up işleminin tersidir. • Az detaylı veriden daha detaylı veriye doğru yönlendirme sağlar. • Drill down işlemi, ya bir boyut için kavram hiyerarşisinde aşağı doğru inerek ya da ek boyutlar tanıtarak gerçekleştirilebilir. • Örn. Sonuç veri küpü, toplam satışları çeyreklere ait özetler halinde vermek yerine, aylık detaylar ile birlikte vermektedir. • Drill down işlemi eldeki veriye daha fazla detay eklediği için, bir küp yapısına yeni boyutlar da ekleyerek oluşturulabilir.
- 125. TÜBİTAK Drill-down
- 126. TÜBİTAK Tipik OLAP Operasyonları • Slice işlemi verilmiş olan küpte, bir alt küp ile sonuçlanan, bir boyut üzerinde seçme gerçekleştirmesidir. – Şekilde zaman boyutu için time=”Q1” kriterini kullanarak merkezi küpten satış verilerinin seçildiği bir slice işlemi görünmekedir. • Dice işlemi ise iki veya daha fazla boyut üzerinde seçim işlemi gerçekleştirerek bir alt küp tanımlar. – Şekil şu üç boyutu ilgilendiren seçim kriterine: (location= ”Toronto” or “Vancouver”) and(time= ”Q1” or”Q2”) and( item= ”home entertainment” or “computer”) dayanarak merkezi küpte yapılan dice işlemini göstermektedir.
- 127. TÜBİTAK Slice
- 128. TÜBİTAK Dice
- 129. TÜBİTAK Tipik OLAP Operasyonları • Pivot(rotate-döndürme): Pivot işlemi, veriye ait alternatif bir görünüm sağlamak amacıyla veri eksenlerini döndüren görsellikle ilgili bir işlemdir. • Şekil parça ve yer eksenlerinin 2 boyutlu olarak yer değiştirdiği bir döndürme işlemini göstermektedir.
- 130. TÜBİTAK Pivot
- 131. TÜBİTAK Küp (Cube) • Verinin hızlı bir şekilde analizine izin veren veri yapısıdır. • Yıldız modeli için verilen örnek bir küp üzerinde aşağıdaki gibi saklanabilir: prodId storeId date amt p1 c1 1 12 p2 c1 1 11 p1 c3 1 50 p2 c2 1 8 p1 c1 2 44 p1 c2 2 4 day 2 c1 c2 c3 p1 44 4 p2 c1 c2 c3 p1 12 50 p2 11 8 day 1 Çok boyutlu (3D) küp :Gerçek tablosu :
- 132. TÜBİTAK Küp İşlemleri day 2 c1 c2 c3 p1 44 4 p2 c1 c2 c3 p1 12 50 p2 11 8 day 1 c1 c2 c3 p1 56 4 50 p2 11 8 c1 c2 c3 sum 67 12 50 sum p1 110 p2 19 129 . . . drill-down rollup Örnek: Toplam Hesaplama sale(c1,*,*) sale(*,*,*) sale(c2,p2,*)
- 133. TÜBİTAK Data Warehouse: A Multi-Tiered Architecture Data Warehouse Extract Transform Load Refresh OLAP Engine Analysis Query Reports Data mining Monitor & Integrator Metadata Data Sources Front-End Tools Serve Data Marts Operational DBs Other sources Data Storage OLAP Server
- 134. TÜBİTAK Veri Ambarı Modelleri • Mimarın bakış açısına göre, üç veri ambarı modeli vardır. Kurumsal veri ambarı, veri pazarı (data mart) ve sanal veri ambarı. • Kurumsal veri ambarı: Bir kurumsal veri ambarı, özneler hakkındaki tüm bilgiyi, organizasyonun tamamını tarayarak toplar. Şirketsel- genişlikte genelde bir veya daha fazla operasyonel sistemden veya dış bilgi sağlayıcılardan ve alanı içerisinde çapraz fonksiyonel olan, veri tümlemeyi sağlar. Tipik olarak özetlenmiş veriyi içerdiği gibi detaylı veriyi de içerir. • Data mart: Data mart, kullanıcıların özel bir grubuna ait değerli, kurumsal genişlikteki verinin bir alt kümesini içerir. Alan özel seçilmiş olan öznelerle sınırlandırılmıştır. Örneğin bir pazarlama data mart ı öznelerini müşteri, parça ve satışlar olarak sınırlandırabilir. Data mart lar içerisinde yer alan veriler özetlenmiş olma eğilimindedir. • Sanal veri ambarı: Sanal veri ambarı, operasyonel veri tabanları üzerinden incelemelerin bir kümesidir. Etkili bir sorgu işleme için sadece bazı muhtemel özet incelemeleri gerçekleştirilebilir. Sanal veri ambarını oluşturmak kolaydır ama operasyonel veritabanı sunucularında çok fazla kapasite gerektirir.
- 135. TÜBİTAK Büyük Veri ve Yüksek Hacim Veri Kümeleri: – Yüksek eleman sayıları (ör., loglar, ölçümler, resimler) • Historik zaman serileri (ör., son 10 yıldaki telefon görüşmeleri) – Yüksek boyutluluk (ör., follow, likes) • Geniş popülasyonu içeren sosyal grafikler (community network) • Büyük bilgi alanları (ör., uydu resimleri, videolar) Yapılmak istenenler: – (Anlamsal) Arama – Temizleme/Ayrıştırma/Entegrasyon – Veri inceleme (hesaplamalar, istatistikler, görselleştirmeler) – Mining/Learning – OLAP – Streaming
- 136. TÜBİTAK Yüksek Hacimli Veriyi İşleme • High throughput(Yüksek işlem kapasitesi) ve low latency (Düşük bekleme/gecikme zamanı) • Tek çözüm var: PARTITIONING
- 137. TÜBİTAK Dağıtık Mimari Distributed Shared Nothing. On premise or in the cloud: (PaaS, SaaS – ör., AWS (Amazon Web Services or Pivotal)
- 138. TÜBİTAK Bölümleyerek(Partitionned) İşleme 1. Partitioning – Bölümler + veri dağılımı tanımlama 2. Kaynak Yönetimi – Her node + cluster file system üzerinde OS desteği 3. Job scheduling – Bölümler üzerinde çalışacak programların dağıtımı ve takvimlenmesi 4. Failure handling / Recovery – Handling node/network failure 5. Programlama modeli – Search/exploration/cleaning/ integration/learning/mining/OLAP desteği
- 139. TÜBİTAK Bölümleme (Partitioning) Veriyi bölümlemenin 3 yolu: 1. Round Robin 2. Hash partitioning 3. Range partitioning Hedef: • Hızlı bölümleme • Dengesiz sayıda veri dağıtımını minimize etme • Etkin scan/point/range sorgu desteği Fast Skew Scan Point Range Round Robin - + + - - Hash + - + + - Range ~ - + ~ +
- 140. TÜBİTAK Kaynak Yönetimi • Processing abstraction – Her node işleme için • Single vs. multi-threaded • With our without HW acceleration (GPU) • Communication abstraction – Within a rack – Across racks – Across data centers • Storage abstraction – Tek bir adres uzayı (Single address space) • Bölümlemeden programcının haberi olmaz Vs. – Çoklu adres uzayı (Multiple address space) • Bölümleme bizzat programcı tarafından yapılır • Cluster Management – Resource allocation (RAM/Disk/CPU/Network) – Kaynak kullanım kontrolü (Admission control)
- 141. TÜBİTAK İş Takvimleme (Job scheduling) • Cluster içindeki çoklu node için execution senkronize edilir – Bir batch işlemi en yavaş node kendi bölümünü işledikten sonra tamamlanır – İşlemin node’lardan birinin fail etmesi durumunda tekrar başlatılması gerekir • Bütün batch / yada tek bir node üstündeki tek bir job • Job’lar aynı/yada farklı node’larda tekrar başlatılır • Batch processing vs. interactive sessions • Mimari: – Master – slave (simple, single-point-of-failure) • Separates control (master) and data (slaves) planes Vs. – Peer-to-peer (robust, complex) • Kontrol node kümesi üzerinde distributed/arbitrated olmalıdır
- 142. TÜBİTAK Failure Handling – Google verisi: • 2009: DRAM – 8% of DIMMS affected by errors • 2007: Disk drives – Yıllık hata oranı: Bir yıl için 1.7 %, 3 yıldan daha eskiler için 8.6% • Hatalar istisna değil kuraldır – Hata tipleri: • Maintenance, HW, SW, poor job scheduling, overload
- 143. TÜBİTAK Failure Handling • Hata toleransını yükseltme: – Redundancy • Veri merkezlerinde HW redundancy. Hatayı indirgiyebilir ama tamamen elimine edemez • Replication – Bölümlerin (Partition) rack’ler/data center’lar arasında replike edilmesi » availability ve performans bağlamıda olumlu etkisi olur (job performed on several replicas in parallel, completes when fastest is done) » Consistency problemleri doğurabilir – Replication model: master-slave (single-point-of-failure) vs. peer-to- peer (arbitration-sıkı denetleme kotrol gerektirir) – Fast replay • Bir node üstündeki hata hızlı bir biçimde tespit edilebilirse ve hangi job’ların bundan etkilendiği belirlenebilirse bu durumda bu job’ların aynı (eğer geçiciyse) yada farklı (eğer kalıcı hataysa) bir node üstünde yeniden çalıştırılması mümkün olabilir – Bunun için hataları denetleyen (job fail etmişse kolay asılı kalmışsa zor bir problem) ve etkisini sınırlandıran (yazılımla olabilir) bir altyapıya gerek var
- 144. TÜBİTAK Replica Tutarlılığı • Problem: Düşünün ki bir data item replike edildi. İdealde, bütün replika gözlemcileri bir güncelleme icra edildiğinde bunun etkisini görmesi gerekir. Pratikte bütün replikalara güncellemenin yansıması zaman alır ve bu arada farklı replika gözlemcileri tutarsız okuma yapabilirler.
- 145. TÜBİTAK Replica Tutarlılığı • CAP teoremi – Geniş ölçekli bölümleme sistemlerinin aşağıda 3 özelliği belirtilmiştir: • Availability • Single-copy Consistency • Tolerance to network partition (e.g., across data centers) – Bu 3 özellikten aynı anda yanlızca 2’si garanti edilebilir
- 146. TÜBİTAK Replica Tutarlılığı (Consistency) • Atomic (yada external) consistency: Bir güncellemeden bütün prosesler anında etkilenir. Tutarsızlık yoktur ancak bir replikanın okunması gecikebilir. • Strong consistency: Bütün güncellemeler bütün prosesler tarafından aynı sırada görülür. Dolayısıyla da bir güncellemenin etkisi bütün gözlemciler tarafından da görülebilir. Tutarsızlık yoktur. • Weak consistency: Gözlemciler replikalar arasında tutarsızlıklar görebilir – Eventual consistency: Weak consistency’nin bir formudur. Failure olamayan bir anda, btün replikalara en son güncelleme yansıtılır.
- 147. TÜBİTAK Programlama Modeli • Veri Paralel Algoritmalar Sum of integers
- 148. TÜBİTAK Programlama Modeli • Veriakış Paradigması: Paralel Veritabanı Sistemleri (Paylaşımsız kümeler mantığı) • Programcılara SQL soyutlama sağlanıyor. Sistem bölümlemeyle otomatik olarak kendi ilgileniyor. Operations are: - Algebraic (take 1 or several partition as input and produce an output which is re-partitioned across nodes) - Scalar (takes one partition as input and produces a scalar)
- 149. TÜBİTAK Programlama Modeli • Map-Reduce: Jeff Dean ve Sanjay Ghemawat tarafından Google’da geliştirildi (mid 00s). Bir Veriakış formudur. Fonksiyonel programlamanın türevi olan 2 operasyondan oluşur: – Tekil cebirsel operasyon map, ve – Skalar operasyon reduce
- 150. TÜBİTAK Nedir MapReduce ? • MapReduce, Google tarafından geliştirilmiş, birbirine bağlı ve birlikte çalışan bilgisayar grubunun (computer cluster) büyük veri kümeleri üzerinde dağıtılmış programlamayı destekleyen bir yazılım kütüphanesidir. • Yazılım kütüphanesinde, genellikle fonksiyonel programlamada kullanılan haritalama (map) ve azaltma (reduce) fonksiyonlarından esinlenilse de, bu fonksiyonların MapReduce’deki amaçları orijinal biçimleriyle aynı değildir. • MapReduce kütüphanesi C++, C#, Erlang, Java, Ocaml, Python, Ruby, F#, R ve diğer programlama dilleri ile yazılmıştır.
- 151. TÜBİTAK Nedir MapReduce ? Çok sayıda veriyi işleyerek başka verileri türetmek, çok zahmetli bir iş olabilir, fakat bu işlem MapReduce ile çok daha kısa zamanda daha performanslı şekilde yapılabilir. MapReduce, • Otomatik Paralellik ve Dağıtım • Hata Toleransı • I/O Zamanlama • Durum ve İzleme gibi özellikler sağlar.
- 152. TÜBİTAK Genel Bakış MapReduce, çok sayıda bilgisayar kullanarak dağıtılabilir problemlerin belli çeşitlerinde geniş datasetleri işlemek için bir yazılım kütüphanesidir. Hesaplamalı işleme yapılandırılmamış bir dosya sistemi ya da bir yapısal veritabanı içinde depolanan veriler üzerinde oluşabilir.
- 153. TÜBİTAK Genel Bakış Map Adımı • Ana düğüm girişi alır, daha küçük alt problemlere ayırır ve bunları çalışan düğümlere dağıtır. Çalışan düğüm bunu tekrar sırayla yapabilir, bu da çok seviyeli ağaç yapısına yol açar. Çalışan düğüm küçük problemleri işler, ve cevapları tekrar ana düğüme verir. Reduce Adımı • Ardından ana düğüm alt problemlerin tümünden cevapları alır ve onları bazı yollarla birleştirerek cevabı elde eder.
- 154. TÜBİTAK
- 155. TÜBİTAK Map Fonksiyonu MapReduce ‘un Map ve Reduce fonksiyonlarının ikisi de, (key, value) çiftinde yapılandırılmış verilere göre tanımlanmıştır. Map veri alanında bir türle verinin bir çiftini alır, farklı alanda bir liste çifti döndürür. • Map(k1,v1) -> list(k2,v2) Map fonksiyonu giriş dataset’indeki her maddeyi paralel olarak uygular. Bu her çağrı için (k2,v2) çiftinin bir listesini üretir. Ardından MapReduce tüm liste ve gruptan aynı anahtar ile çiftleri birleştirir, böylece farklı üretilen anahtarların her biri için bir grup oluşturulur.
- 156. TÜBİTAK Reduce Fonksiyonu Reduce fonksiyonu da her grubu paralel olarak uygular, aynı alandaki değerlerin bir yığınını sırayla üretir. • Reduce(k2, list (v2)) -> list(v3) Her Reduce çağrısına bir v3 değeri, ya da boş değer üretir, yine de bir çağrı birden fazla değerin dönmesine izin verir. Böylece MapReduce değerleri içeren bir listeden (key, value) çiftleri listesi dönüştürür.
- 157. TÜBİTAK Map ve Reduce • map(String input_key, String input_value): // input_key: document name // input_value: document contents for each word w in input_value: EmitIntermediate(w, "1"); • reduce(String output_key, Iterator intermediate_values): // output_key: a word // output_values: a list of counts int result = 0; for each v in intermediate_values: result += ParseInt(v); Emit(AsString(result));
- 158. TÜBİTAK MapReduce Örnek : İçerisinde meyve adı ve satın alınan fiyat bilgisi bulunan veriler düşünelim, ve bu verilerin işlenmesi, o meyveye ait toplam harcama bilgisi isteniyor. MapReduce ile bu basit ve hızlı şekilde yapılabilir. Verilerimiz aşağıdaki şekilde olsun : • armut 10 • portakal 3 • incir 9 • armut 9 • armut 10 • incir 3 • mandalina 2 • erik 29
- 159. TÜBİTAK MapReduce Anahtar değerleri meyve isimleri olacak, ve 2 adet MapReduce düğümümüz var ise bu veriler 2 parçaya bölünür ve MapReduce’a verilir. • armut 10 • portakal 3 • incir 9 • armut 9 • ------ • armut 10 • incir 3 • mandalina 2 • incir 29
- 160. TÜBİTAK MapReduce Her düğüm, kendi içinde Map fonksiyonunu çalıştırırken, benzer anahtar değerlerini aynı toplama yazacaktır. • Bölüm 1) armut = 19, portakal = 3, incir = 9. • Bolum 2) armut 10, incir = 32, mandalina = 2. Böylece Map işlemi bitmiştir, indirgeme (Reduce) işlemine geçilecektir.
- 161. TÜBİTAK Reduce kısmında her bölümdeki anahtarlar kendi aralarında toplanır ve sonuç elde edilir. • armut = 29 • portakal = 3 • incir = 41 • mandalina = 2 Veriler MapReduce ile kolayca işlenmiştir.
- 162. TÜBİTAK Hız • Tipi veritabanı mimarisinde – Veri saklanır – Yüksek hacimli veritabanı güncellemesi olur (OLTP) • Streaming veritabanı – Veri saklanmaz – One pass processing • Batch processing sistemler yüksek hız için uygun değildir – Yüksek hızlı veride Scheduling yapılamaz
- 163. TÜBİTAK OLTP Performans Kriterleri • Transactions – ACID(Atomicity, Consistency, Isolation, Durability) özelliklerini locking ve logging’le birlikte taşıması. • Locking – Kilitli veri yapılarının Atomic tutarlılığı sağlaması – Multiple-writers on cache line • Multiple cores, across socket/sites – Risk for Lock Bouncing • Logging – Synchronous writes at commit time • Sequential writes to log file – Checkpointing • Batches of random writes to data files
- 164. TÜBİTAK Yeni Mimariler • Remove logging – Provide availability through replication in a share-nothing cluster • Remove locking/latching – Consider single-site/one-shot transactions – single-thread processing on each site • Main-memory databases – No logging – Simple form of checkpointing’ – Partitioning across cluster nodes • Examples: H-store (MIT), VoltDB, EMC Pivoltal GemFire
- 165. TÜBİTAK
- 166. TÜBİTAK Streaming Databases Data Q Result Set DBMS Q DATA Result Set DBMS Traditional DBMS Architecture Streaming DBMS Architecture
- 167. TÜBİTAK Streams • A stream is an infinite sequence of tuples – Time x Schema – Regular vs. irregular values in the time dimension – E.g., time series from sensors, financial quotes • Producer-consumer model – Algebraic operations that take streams as input and generate an output stream – Mapped onto a clustered architecture where a stream might be partitioned (c) Philippe Bonnet 2014
- 168. TÜBİTAK Stream Database Processing • One pass algebraic operations on the data – Windowed processing • Failure-handling: In case of crash, window state should be recovered – Approximations needed to deal with global values (e.g., frequency, aggregates) • Algebraic operations at wire-speed – Ibex : FPGA-based storage engine – Processing financial information at hardware speed using FPGA devices (patent)