IBM Flash System 810 Ru
•
0 gostou•816 visualizações

independent review of IBM Flash System 810 (with IBM SVC)

Recomendados
Recomendados
Mais conteúdo relacionado
Mais procurados
Mais procurados (19)
Destaque
Destaque (10)
Semelhante a IBM Flash System 810 Ru
Semelhante a IBM Flash System 810 Ru (20)
Mais de Oleg Korol
Mais de Oleg Korol (14)
Último
Último (9)
IBM Flash System 810 Ru
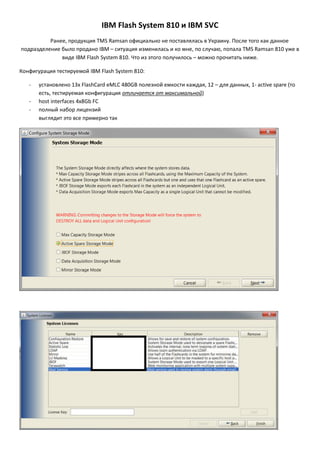
- 1. IBM FlashSystem 810 и IBM SVC Ранее, продукция TMS Ramsan официально не поставлялась в Украину. После того как данное подразделение было продано IBM – ситуация изменилась и ко мне, по случаю, попала TMS Ramsan 810 уже в виде IBM FlashSystem 810. Что из этого получилось – можно прочитать ниже. Конфигурация тестируемой IBM FlashSystem 810: - установлено 13х FlashCard eMLC 480GB полезной емкости каждая, 12 – для данных, 1- active spare (то есть, тестируемая конфигурация отличается от максимальной) host interfaces 4x8Gb FC полный набор лицензий выглядит это все примерно так
- 2. - В SPC-1 на момент написания данного обзора нет результатов IBM FlashSystem 810. А официальный результат схожей (но уже полностью отказоустойчивой) IBM FlashSystem 820 в SPC-1– ~195K iops при Average Response Time 1,29 ms. Проведем ряд тестов для определения реально достижимых показателей производительности на IBM FlashSystem 810 в данной конфигурации. А также повторим их для ситуации, когда IBM FlashSystem 810 виртуализирована посредством IBM SVC, чтобы определить – не будет ли SVC в такой ситуации узким местом? В тестовом ландшафте часть емкости IBM FlashSystem 810 была отдана напрямую (через SAN) хосту, а другая часть была презентована хосту через отдельный pool SVC (единственная io-группа, 2-ноды CG8). Хост представлял собой dLPAR на IBM Power Systems 9117-MMB с AIX 6.1 TL08 SP3 (в данный релиз включена поддержка IBM FlashSystem 810 и для него не требуется установка дополнительных ODM ). И с SVC и напрямую с FlashSystem 810 хосту было презентовано по 16хLU, которые на хосте были собраны в страйп посредством AIX LVM. Для размещения данных была использована файловая система JFS2 с inline log и опциями монтирования noatime, cio. Каждая из файловых систем (размером по 2ТБ) была заполнена данными на >80%. На IBM SVC все 16xLU были thin (IBM FlashSystem 810 не обладает подобной технологией).
- 3. Первый тест проведем для многопоточной нагрузки вида - 100% Random, соотношения Read/Write= 80/20, варьируя размер блока (diagram 1,2). Используя подключение IBM FlashSystem 810 к хосту через SAN (без IBM SVC). для блоков 64KB/128KB была достигнута максимальна пропускная способность, ограниченная 4х8Gbit FC интерфейсов. относительно низкие показатели производительности при размере блока 512B и 2KB, обусловлены размером используемого блока на уровне файловой системы JFS2 (4KB) diagram 1 - IBM FlashSystem 810 100% Random, Read/Write= 80/20 250000 200000 IOPS 150000 100000 50000 0 FlashSystem 810 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB 54303 54347 225278 191741 167754 89818 51661 25010 diagram 2 - IBM FlashSystem 810 average latency 25 ms 20 15 10 5 0 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB FlashSystem 810, write 512B 0.1 2KB 0.1 4KB 0.1 8KB 0.1 16KB 0.1 32KB 0.2 64KB 0.3 128KB 0.4 FlashSystem 810, read 0.2 0.2 0.3 0.5 0.8 1.5 3.5 8.2
- 4. Повторим тест для многопоточной нагрузки вида - 100% Random, соотношения Read/Write= 80/20, варьируя размер блока, но презентуя IBM FlashSystem 810 к хосту через IBM SVC (diagram 3,4). Как видно на диаграмме – ряд цифр меньше, чем в предыдущем тесте. Причина была более чем очевидна – во время теста фиксировалась максимальная загрузка CPU на обеих нодах SVC. Одновременно с уменьшением кол-ва iops ухудшилось время отклика. diagram 3 - IBM FlashSystem 810 over IBM SVC 100% Random, Read/Write= 80/20 250000 200000 IOPS 150000 100000 50000 0 SVC+FlashSystem 810 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB 44444 44423 153889 135541 111212 68236 36558 18193 diagram 4 - IBM FlashSystem 810 over IBM SVC average latency 25 ms 20 15 10 5 0 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB SVC+FlashSystem 810, write 512B 0.1 2KB 0.1 4KB 0.5 8KB 0.5 16KB 0.5 32KB 0.4 64KB 0.5 128KB 0.6 SVC+FlashSystem 810, read 0.3 0.3 1.1 1.2 1.8 4 10 20
- 5. Еще раз повторим тест. Оставив характер нагрузки неизменным - 100% Random, соотношения Read/Write= 80/20. Но теперь выключим кеширование на SVC для соответствующих volumes (Cache Mode Disabled ). Как видно на диаграмме ниже (diagram 5,6) – это позволило улучшить немного результат в iops, но ухудшило время отклика на больших блоках. И снова ограничивающим фактором была загрузка CPU на нодах SVC. diagram 5 - IBM FlashSystem 810 over IBM SVC 100% Random, Read/Write= 80/20 250000 200000 iops 150000 100000 50000 0 SVC (Cache disabled)+FlashSystem 810 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB 45552 46684 191483 169890 133663 79913 40926 18821 diagram 6 - IBM FlashSystem 810 over IBM SVC average latency 25 ms 20 15 10 5 0 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB SVC (Cache disabled)+FlashSystem 810, write 0.1 0.1 0.2 0.2 0.2 0.5 1.2 2.2 SVC (Cache disabled)+FlashSystem 810, read 0.3 0.3 0.6 1 1.5 3.1 9 25
- 6. Сведем ранее полученные данные вместе на (diagram 7,8). diagram 7 - iops 250000 200000 150000 100000 50000 0 512B 2KB 4KB SVC+FlashSystem 810 8KB 16KB 32KB 64KB SVC (Cache disabled)+FlashSystem 810 128KB FlashSystem 810 diagram 8 - average R/W latency, ms 25 20 15 10 5 0 512B 2KB 4KB 8KB 16KB 32KB 64KB 128KB FlashSystem 810, write SVC (Cache disabled)+FlashSystem 810, write SVC+FlashSystem 810, write FlashSystem 810, read SVC (Cache disabled)+FlashSystem 810, read SVC+FlashSystem 810, read
- 7. Зависимость в предыдущих тестах CPU load на SVC от нагрузки в iops отражена ниже на diagram 9. diagram 9 - 100% Random, Read/Write= 80/20, block size=8KB SVC (Cache disabled)+FlashSystem 810 200 150 100 50 19 37 48 59 75 76 80 80 80 80 80 SVC CPU load % K IOPS 0 8 10 12 14 16 18 20 22 the number of concurrent streams -> 24 26 28
- 8. Результаты: Как было продемонстрировано выше, производительность одной IBM FlashSystem 810 даже не в полной конфигурации превосходит производительность двухнодовой IBM SVC. (тем не менее связка IBM SVC+ IBM FlashSystem,все равно быстрее чем, например, IBM Storwize V7000 с SSD). Стоит отметить, что для IBM SVC доступен ряд апгрейдов, в частности – добавление второго CPU и еще одной 4-портовой FC HBA. В ряде IBM RedBooks, при совместном использовании IBM FlashSystem и IBM SVC, есть рекомендация - апгрейдить ноды IBM SVC путем установки второй FC HBA. Но при этом нет рекомендации добавить второй процессор. Почему? Ведь выше было наглядно продемонстрированно, что для такой связки узким местом является именно CPU на нодах SVC. Причина достаточно банальна – текущий код/firmware SVC может использовать дополнительный CPU только (и исключительно) для Real-time Compression, т.к. для общих вычислений поддерживается не более 4хCPU Core. Вопросы? Олег Король it-expert@ukr.net http://ua.linkedin.com/pub/oleg-korol/26/920/716