State of the Art Informatics for Research Reproducibility, Reliability, and Reuse: Or How I Learned to Stop Worrying and Love Data Management
•Transferir como PPTX, PDF•
4 gostaram•2,424 visualizações

In March, I had the pleasure of being the inaugural speaker in a new lecture series (http://library.wustl.edu/research-data-testing/dss_speaker/dss_altman.html) initiated by the Libraries at the Washington University in St. Louis Libraries -- dedicated to the topics of data reproducibility, citation, sharing, privacy, and management. In the presentation embedded below, I provide an overview of the major categories of new initiatives to promote research reproducibility, reliability, and reuse and related state of the art in informatics methods for managing data.

Recomendados
Recomendados
Mais conteúdo relacionado
Mais procurados
Mais procurados (20)
Destaque
Destaque (7)
Semelhante a State of the Art Informatics for Research Reproducibility, Reliability, and Reuse: Or How I Learned to Stop Worrying and Love Data Management
Semelhante a State of the Art Informatics for Research Reproducibility, Reliability, and Reuse: Or How I Learned to Stop Worrying and Love Data Management (20)
Mais de Micah Altman
Mais de Micah Altman (20)
Último
Último (20)
State of the Art Informatics for Research Reproducibility, Reliability, and Reuse: Or How I Learned to Stop Worrying and Love Data Management
- 1. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse Managing Research Information
- 2. Managing Research Information Prepared for Data Speaker Series Washington University in St Louis March 2014 State of the Art Informatics for Research Reproducibility, Reliability, and Reuse: Or How I Learned to Stop Worrying and Love Data Management Dr. Micah Altman <escience@mit.edu> Director of Research, MIT Libraries Non-Resident Senior Fellow, Brookings Institution
- 3. DISCLAIMER These opinions are my own, they are not the opinions of MIT, Brookings, any of the project funders, nor (with the exception of co-authored previously published work) my collaborators Secondary disclaimer: “It’s tough to make predictions, especially about the future!” -- Attributed to Woody Allen, Yogi Berra, Niels Bohr, Vint Cerf, Winston Churchill, Confucius, Disreali [sic], Freeman Dyson, Cecil B. Demille, Albert Einstein, Enrico Fermi, Edgar R. Fiedler, Bob Fourer, Sam Goldwyn, Allan Lamport, Groucho Marx, Dan Quayle, George Bernard Shaw, Casey Stengel, Will Rogers, M. Taub, Mark Twain, Kerr L. White, etc. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse
- 4. Collaborators & Co-Conspirators • Michael P. McDonald, GMU • National Digital Stewardship Alliance, Coordination Committee • Data Citation Synthesis Group • CO-Data Task Group on Data Citation • Data-PASS Steering Committee • Privacy Tools for Research Data Project • OCLC Research • Research Support Thanks to the the NSF, NIH, IMLS, Sloan Foundation, the Joyce Foundation, the Judy Ford Watson Center for Public Policy, Amazon Corporation State of the Art Informatics for Research Reproducibility, Reliability, and Reuse
- 5. Related Work • M. Altman, and M.P. McDonald. (2014) “Public Participation GIS : The Case of Redistricting.” Proceedings of the 47th Annual Hawaii International Conference on System Sciences. Computer Society Press (IEEE). • Novak K, Altman M, Broch E, Carroll JM, Clemins PJ, Fournier D, Laevart C, Reamer A, Meyer EA, Plewes T. Communicating Science and Engineering Data in the Information Age. National Academies Press; 2011. • Micah Altman, Simon Jackman (2011) Nineteen Ways of Looking at Statistical Software, 1-12. In Journal Of Statistical Software 42 (2). • Micah Altman, Jonathan Crabtree (2011) Using the SafeArchive System : TRAC-Based Auditing of LOCKSS, 165-170. In Archiving 2011. • Micah Altman, Jeff Gill, Michael McDonald (2003) Numerical issues in statistical computing for the social scientist. In John Wiley & Sons. • Altman, M., & Crabtree, J. 2011. Using the SafeArchive System : TRAC-Based Auditing of LOCKSS. Archiving 2011 (pp. 165–170). Society for Imaging Science and Technology. • M. Altman, Adams, M., Crabtree, J., Donakowski, D., Maynard, M., Pienta, A., & Young, C. 2009. "Digital preservation through archival collaboration: The Data Preservation Alliance for the Social Sciences." The American Archivist. 72(1): 169-182 • Data Synthesis Task Group. 2014. Joint Principles for Data Citation. • CODATA Data Citation Task Group, 2013. Out of Cite, Out of Mind: The Current State of Practice, Policy and Technology for Data Citation. Data Science Journal [Internet]. 2013;12:1–75. • NDSA, 2013. National Agenda for Digital Stewardship, Library of Congress. Reprints available from: informatics.mit.eduState of the Art Informatics for Research Reproducibility, Reliability, and Reuse
- 6. This Talk * What’s the problem? * * Improving research reproducibility, reliability, and reuse * * State of the Practice * State of the Art Informatics for Research Reproducibility, Reliability, and Reuse
- 7. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse What’s the problem? (more and less)
- 8. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse MORE INFORMATION
- 9. Some General Trends in Scholarship Shifting Evidence Base High Performance Collaboration (here comes everybody…) Lots More Data Publish, then Filter More Learners 9 More Open
- 10. Next big thing? … More Everything Mobile Forms of publication Contribution & attribution Cloud Open Publications Interdisciplinary Personal data Mashups Students Readers Funders Crowds Everything/Everybody 10 Maximizing the Impact of Research through Research Data Management
- 11. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse LESS TRUST IN RESEARCH
- 12. What Science Requires Helping Journals Manage Data “Citations to unpublished data and personal communications cannot be used to support claims in a published paper” “All data necessary to understand, assess, and extend the conclusions of the manuscript must be available to any reader of Science.”
- 13. Increased Retractions, Allegations of Fraud Maximizing the Impact of Research through Research Data Management 13
- 14. The File Drawer Problem Maximizing the Impact of Research through Research Data Management Daniel Schectman’s Lab Notebook Providing Initial Evidence of Quasi Crystals • Null results are less likely to be published published results as a whole are biased toward positive findings • Outliers are routinely discarded unexpected patterns of evidence across studies remain hidden 14
- 15. Compliance with Journal Policies is Low Maximizing the Impact of Research through Research Data Management Compliance is low even in best examples of journals Checking compliance manually is tedious 15
- 16. Erosion of Evidence Base Maximizing the Impact of Research through Research Data Management Examples Intentionally Discarded: “Destroyed, in accord with [nonexistent] APA 5-year post-publication rule.” Unintentional Hardware Problems “Some data were collected, but the data file was lost in a technical malfunction.” Acts of Nature The data from the studies were on punched cards that were destroyed in a flood in the department in the early 80s.” Discarded or Lost in a Move “As I retired …. Unfortunately, I simply didn’t have the room to store these data sets at my house.” Obsolescence “Speech recordings stored on a LISP Machine…, an experimental computer which is long obsolete.” Simply Lost “For all I know, they are on a [University] server, but it has been literally years and years since the research was done, and my files are long gone.” Research by: • Researchers lack archiving capability • Incentives for preserving evidence base are weak • Availability declines with age [Pienta 2006; Hedstrom et al 2008; Vines et al. 2014] 16
- 17. Computational Black Boxes (Or how not to compute a standard deviation) State of the Art Informatics for Research Reproducibility, Reliability, and Reuse [Joppa et al. 2013]
- 18. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse Ok, but what’s the worst thing that could happen to me?
- 19. The Baltimore (Imanishi-Kari) Case • In 1986, Postdoc accuses collaborator of Nobelist David Baltimore of fraud • Accusations are dropped, but NIH picks up investigation, • Member of congress, U.S. Secret Service, U.S. Attorney become involved • After a decade of investigations, reports, lawyers and media – all charges dismissed. • Much ink has been shed both in defense and criticism – Kevles [2000] conducted a historical examination, and convincing analysis… the verdict BAD DATA MANAGEMENT* State of the Art Informatics for Research Reproducibility, Reliability, and Reuse * See Marc Hauser’s wikipedia bio for a more recent example
- 20. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse Or maybe your grad student moves to china? (And all the variables in your dataset are named SAM_1..N) http://www.youtube.com/watch?v=N2zK3sAtr-4
- 21. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse State of the Art
- 22. Core Requirements for Community Information Infrastructure Maximizing the Impact of Research through Research Data Management • Stakeholder incentives – recognition; citation; payment; compliance; services • Dissemination – access to metadata; documentation; data • Access control – authentication; authorization; rights management • Provenance – chain of control; verification of metadata, bits, semantic content • Persistence – bits; semantic content; use • Legal protection & compliance – rights management; consent; record keeping; auditing • Usability for… – discovery; deposit; curation; administration; annotation; collaboration • Economic model – Valuation models; cost models; business models • Trust model See: King 2007; ICSU 2004; NSB 2005; Schneier 2011 22
- 23. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse Replication Data Publishing
- 24. FigShare • Closed source • No charge • Archives data • Supports DOI’s, ORCIDS • Preserved in CLOCKSS Emerging Data Citation Practices Dataverse Network • Open Source System • Hubs run at Harvard other universities • Archives data • Generates persistent identifiers (handles, DOI’s forthcoming) • Generates resolvable citations • Versioned • Harvard Library Dataverse now part of DataCite, Data-PASS preservation network ICPSR Replication Archive • Traditional disciplinary data archive • Minimal cataloging and storage for free • Fully curated open-data model for deposit fee • Fully Curated membership model
- 25. Emerging Developments Emerging Data Citation Practices Open Journal Data Publication • Open source integration of PKP-OJS and Dataverse Network • Uses SWORD • Integrated data submission/citation/publi cation workflow for OJS open journals Journal Developments • NISO Recommendations on Supplementary Materials • Sloan/ICPSR Data Citation Project • Data-PASS Journal Outreach • New journal types: – Registered Replication journals – Null results journals – Data journals/data papers Data Dryad • Integrated data deposit with specific journals • CCO – Open data
- 26. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse Data Publication
- 27. General Data Sharing FigShare • Closed source • No charge • Archives data • Supports DOI’s, ORCIDS • Preserved in CLOCKSS Emerging Data Citation Practices Dataverse Network • Open Source System • Hubs run at Harvard other universities • Archives data • Generates persistent identifiers (handles, DOI’s forthcoming) • Generates resolvable citations • Versioned • Harvard Library Dataverse now part of DataCite, Data-PASS preservation network Scientific Data Journal • Scientific data publishing journal • Published “data papers” • Nature publishing group • Also see JOVE for video-as- publication CKAN • Open source • DIY Hosting – you host • Based on Drupal
- 28. Helping Journals Manage Data The Dataverse Network ® -- A Computer Assisted Approach to Data Publication
- 29. Helping Journals Manage Data
- 30. Helping Journals Manage Data
- 31. Helping Journals Manage Data
- 32. Helping Journals Manage Data
- 33. Helping Journals Manage Data
- 34. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse Data Citation
- 35. Current Infrastructure Emerging Data Citation Practices Data Citation Index • Commercial Service (Thomson Reuters) • Indexes many large repositories (e.g. Data-PASS) • Beginning to extract citations from TR publications Dataverse Network • Open Source System • Hubs run at Harvard other universities • Archives data • Generates persistent identifiers (handles, DOI’s forthcoming) • Generates resolvable citations • Versioned • Harvard Library Dataverse now part of DataCite, Data-PASS preservation network DataCite • DOI registry service (DOI provider) • Data DOI metadata indexing service (parallel to CrossRef) • Not-for-profit membership Organization • Collaborating with ORCID-EU to embed ORCIDs
- 36. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse MORE
- 37. Code Replication Emerging Data Citation Practices Researcher Identifier Integrated Publication Workflows Registered Replications & Trials Registered Replication Reports (The Tip of the Iceberg)
- 38. Exercise Caution when Using a New “Black Box”* • Amazon Glacier claims a design reliability of 99.999999999% • Sounds good… – Longer odds than winning Powerball OR – Getting struck by a lightning, three times OR – (Possibly) eventually finding alien civilization Approaches to Preservation Storage Technologies 38 *Or using an old black box in a new context
- 39. Clarifying Requirements • What are the units of reliability? - Collection? Object? Bit? • What is the natural unit of risk? • Is value of information uniform across units? • How many of these do you have? Approaches to Preservation Storage Technologies 39
- 40. Hidden Assumptions• What does “99.999999999” mean? – What are the units of reliability? - Collection? Object? Bit? – What is the natural unit of risk? – Is value of information uniform across units? – How many of these do you have? • Reliability estimates appear entirely theoretical – (MTBF + Independence)* enough replicas -> as many 9’s as you like… – No details for estimate provided – No historical reliability statistics provided – No service reliability auditing provided • Empirical Issues – Storage manufacture hardware MTBF (mean time between failures) does not match observed error rates in real environments… – Failures across hardware replicas are observed to correlated • Unmodeled failure modes – software failure (e.g. a bug in the AWS software for its control backplane might result in permanent loss that would go undetected for a substantial time_ – legal threats (leading to account lock-out — such as this, deletion, or content removal); – institutional threats (such as a change in Amazon’s business model) – Process threats (someone hits the delete button by mistake; forgets to pay the bill; or AWS rejects the payment) • Business risks… – Amazon SLA’s do not incorporate or reflect “design” reliability claims – No claim to reliability in SLA’s – Sole recover for breach limited to refund of fees for periods the service was unavailable – No right to audit logs, or other evidence of reliability Approaches to Preservation Storage Technologies 40
- 41. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse State of the Practice “In theory, theory and practice are the same – in practice, they differ.”
- 42. Climate vs Weather • Climate is what you should expect -- weather is what you get. • Climate for reproducibility and data management seems favorable… prepare for shifts in the weather. Maximizing the Impact of Research through Research Data Management 42
- 43. Softwar e Best Practice Preserve d Digital Content Storage Provisionin g Pure Market Approaches Cannot Produce Optimal Levels of Knowledge 43 Research Program for Information Science Excludable Rivalrous Source: © Hugh Macleod, Gapingvoid Art gapingvoid.com Willing Researc h Subject s
- 44. What are the goals of data management? • Operational Values – Orchestrate data for efficient and reliable use within a designated research project – Control disclosure – Compliance with contracts, regulations, law, and institutional policy – Ensure short term and long term dissemination • Use-value predicted future value of the information asset – Value to research group – Value to institution – Value to discipline – Value to science & scholarship (e.g. through interdisciplinary discovery and access, scientific reproducibility, reducing publication & related bias) – Value to public (wide reuse, public understanding, participative science, and transparency in public policy) – Minimize disclosive harms (e.g. breaches of confidentiality,taking of intellectual property) – to subject populations, intellectual rights holders, general public Maximizing the Impact of Research through Research Data Management 44
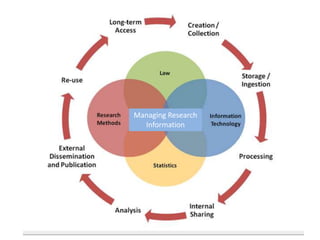
- 46. Creation/C ollection Storage/ Ingest Processing Internal Sharing Analysis External dissemination/ publication Re-use Long- term access Stakeholders Scholarly Publishers Researchers Data Archives/ Publisher Research Sponsors Data Sources/Su bjects Consumers Service/Infras tructure Providers Research Organizations Needs for Data Management & Citation 46 Modeling
- 47. Legal Constraints Contract Intellectual Property Access Rights Confidentiality Copyright Fair Use DMCA Database Rights Moral Rights Intellectual Attribution Trade Secret Patent Trademark Common Rule 45 CFR 26 HIPAA FERPA EU Privacy Directive Privacy Torts (Invasion, Defamation) Rights of Publicity Sensitive but Unclassified Potentially Harmful (Archeological Sites, Endangered Species, Animal Testing, …) Classified FOIA CIPSEA State Privacy Laws EAR State FOI Laws Journal Replication Requirements Funder Open Access Contract License Click-Wrap TOU ITAR Export Restrictions
- 48. Data Management Core Norms Maximizing the Impact of Research through Research Data Management 48 • Information stewardship – View information as potentially durable assets – Manage durable assets for long-term sustainable use • Awareness of information lifecycle – Information organization & architecture (Metadata, identification, provenance, data structure & format) – Processes • Awareness beyond disciplinary boundaries – Inter-disciplinary discovery – Multi-disciplinary access • Justify Trust – Trust but verify – Demonstrate trustworthiness
- 49. Data Management: Operational Aspects • Orchestrate data for current use – Quality Assurance – Storage, backup, replication, and versioning – Data Formats – Data Organization – Budget – Metadata and documentation • Control disclosure – Access and Sharing – Intellectual Property Rights – Legal Requirements – Security • Compliance with contracts, regulations, law, and policy – Access and Sharing – Adherence – Responsibility – Ethics and privacy – Security • Selection: – Data description – Data value – Relation to collection – Relation to evidence base – Budget • Ensure short term and long term dissemination – Data description – Institutional Archiving Commitments – Audience – Access and Sharing – Data Formats – Data Organization – Metadata and documentation – Budget Needs for Data Management & Citation 49 Planning
- 50. DMP Operational Details • Sharing – Plans for depositing in an existing public database – Access procedures – Embargo periods – Access charges – Timeframe for access – Technical access methods – Restrictions on access • Long term access (Preservation) – Requirements for data destruction, if applicable – Procedures for long term preservation – Institution responsible for long-term costs of data preservation – Succession plans for data should archiving entity go out of existence • Formats – Generation and dissemination formats and procedural justification – Storage format and archival justification – Format documentation • Metadata and documentation – Internal and External Identifiers and Citations – Metadata to be provided – Metadata standards used – Planned documentation and supporting materials – Quality assurance procedures for metadata and documentation • Data Organization – File organization – Naming conventions • Storage, backup, replication, and versioning – Facilities – Methods – Procedures – Frequency – Replication – Version management – Recovery guarantees • Security – Procedural controls – Technical Controls – Confidentiality concerns – Access control rules – Restrictions on use • Budget – Cost of preparing data and documentation – Cost of storage and backup – Cost of permanent archiving and access • Intellectual Property Rights – Entities who hold property rights – Types of IP rights in data – Protections provided – Dispute resolution process • Legal Requirements – Provider requirements and plans to meet them – Institutional requirements and plans to meet them • Responsibility – Individual or project team role responsible for data management – Qualifications, certifications, and licenses of responsible parties • Ethics and privacy – Informed consent – Protection of privacy – Data use agreements – Other ethical issues • Adherence – When will adherence to data management plan be checked or demonstrated – Who is responsible for managing data in the project – Who is responsible for checking adherence to data management plan – Auditing procedures and framework • Value of information assets – Project use value – Institutional audience and uses – Public audience and uses – Relation to institutional collection – Relation to disciplinary evidence base – Cost of re-creating data Needs for Data Management & Citation 50
- 51. Many Tools, Few Comprehensive Solutions • Many scientific tools are embedded in needs, perspectives, and practices of specific disciplines • We must identify gaps across lifecycle stages and actors • Identify common requirements across disciplines and stakeholders Needs for Data Management & Citation 51 “Poor carpenters blame their tools” –Some Proverb “If all you have is a hammer, everything looks like a nail” – Another Proverb “Ultimately, some people need holes – but no one needs a drill. ” – Yet Another Proverb
- 52. plus ça change, plus c'est la même folie* • Budget constraints • Invisibility of infrastructure • Organizational biases • Cognitive biases • Inter- and intra- organizational trust • Discount rates and limited time-horizons • Deadlines • Challenging in matching skillsets & problems • Legacy systems & requirements • Personalities • Bureaucracy • Politics Maximizing the Impact of Research through Research Data Management 52 * Translation: The more things change, the more they stay insane.
- 53. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse The best time to plant a tree was 20 years ago… The second-best time is today.
- 54. Jump Start – Create A Dataverse • Create a dataverse hosted by the Harvard Dataverse Network: http://thedata.harvard.edu/dvn/faces/login/CreatorReq uestInfoPage.xhtml • Free, permanent storage, dissemination, backed by Harvard’s endowment… State of the Art Informatics for Research Reproducibility, Reliability, and Reuse
- 55. Jump Start – LibGuides • Help researchers get credit for their work – Data citation http://www.force11.org/node/4769 – Researcher identifiers http://orcid.org – Metrics http://libraries.mit.edu/scholarly/publishing/imp act-factors/ State of the Art Informatics for Research Reproducibility, Reliability, and Reuse
- 56. Jump Start – Link to DMPTOOL • Try DMPTOOL https://dmp.cdlib.org/ • Instant guidance for data-management plans • A potential jumping off point for service and evaluation State of the Art Informatics for Research Reproducibility, Reliability, and Reuse
- 57. Additional References • Crosas, M. (2011). “The Dataverse Network: An Open-Source Application for Sharing, Discovering and Preserving Data.” D-Lib Magazine 17 (1–2). • D. Foray, 2006, The Economics of Knowledge, MIT Press • C. Hess & E. Ostrom 2007, Understanding Knowledge as a Commons • W. Lougee, 2002. Diffuse Libraries: Emergent Roles for the Research Library in the Digital Age • G. King. 2007. An Introduction to the Dataverse Network as an Infrastructure for Data Sharing. Sociological Methods and Research 36: 173–99 • Haak, Laurel L., et al. "ORCID: a system to uniquely identify researchers." Learned Publishing 25.4 (2012). • Hahnel, M. (2013) "Referencing: The reuse factor." Nature 502.7471: 298. • Hedstrom, M., Niu, J. Marz, K. (2008). “Incentives for Data Producers to Create “Archive/Ready” Data: Implications for Archives and Records Management”, Proceedings of the Society of American Archivists Research Forum. Retrieved from http://files.archivists.org/conference/2008/researchforum/M-HedstromJ-Niu-SAA-ResearchPaper- 2008.pdf • International Council For Science (ICSU) 2004. ICSU Report of the CSPR Assessment Panel on Scientific Data and Information. Report. • Joppa, Lucas N., et al. "Troubling trends in scientific software use." Science 340.6134 (2013): 814- 815. • Kevles, Daniel J. The Baltimore case: A trial of politics, science, and character. WW Norton & Company, 2000. • Pienta, A., LEADS Database Identifies At-Risk Legacy Studies, ICPSR Bulletin 27(1) 2006 • D. S.H. Rosenthal, Thomas S. Robertson, Tom Lipkis, Vicky Reich, Seth Morabito. “Requirements for Digital Preservation Systems: A Bottom-Up Approach”, D-Lib Magazine, vol. 11, no. 11, November 2005 • B. Schneier, 2012. Liars and Outliers, John Wiley & Sons • University Leadership Council, 2011, Redefining the Academic Library: Managing the Migration to Digital Information Services • Vines, T. H.; Albert, A. Y.K.; Andrew, R. L.; D barre, F.; Bock, D.G..; Franklin, M. T.; Gilbert, K. J.; Moore, J-S.; Renaut, S; Rennison, D. J. (2014). “The Availability of Research Data Declines Rapidly with Article Age” Current Biology 24 (1): 94 – 97. • Vision, T. J. (2010). "Open data and the social contract of scientific publishing."BioScience 60, (5) : 330-331. State of the Art Informatics for Research Reproducibility, Reliability, and Reuse
- 58. Additional Links • ORCID: Orcid.org • Ipython: ipython.org • Run My Code runmycode.org • Research Compendia researchcompendia.org/ • Vistrails vistrails.org • Research Replication Reports http://www.psychologicalscience.org/index.php/replication • Journal of Visual Experiments jove.com • Dataverse Network thedata.org • Data Cite datacite.org • Thomson Reuters Data Citation Index wokinfo.com/products_tools/multidisciplinary/dci/ • Data dryad datadryad.org • Knitr yihui.name/knitr/ • CKAN ckan.org • Figshare figshare.com State of the Art Informatics for Research Reproducibility, Reliability, and Reuse
Notas do Editor
- This work by Micah Altman (http://redistricting.info) is licensed under the Creative Commons Attribution-Share Alike 3.0 United States License. To view a copy of this license, visit http://creativecommons.org/licenses/by-sa/3.0/us/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA.
- Scholarly publishers, research funders, universities, and the media, are increasingly scrutinizing research outputs. Of major concern is the integrity, reliability, and extensibility of the evidence on which published findings are based. A flood of new funder mandates, journal policies, university efforts, and professional society initiatives aim to make this data verifiable, reliable, and reusable: If "data is the new oil", we need data management to prevent 'fires', ensure 'high-octane', and enable 'recycling'. In March, I had the pleasure of being the inaugural speaker in a new lecture series (http://library.wustl.edu/research-data-testing/dss_speaker/dss_altman.html) initiated by the Libraries at the Washington University in St. Louis Libraries -- dedicated to the topics of data reproducibility, citation, sharing, privacy, and management. In the presentation embedded below, I provide an overview of the major categories of new initiatives to promote research reproducibility, reliability, and reuse and related state of the art in informatics methods for managing data. [EMBED PRESENTATION ]This blog post provides some wider background for the presentation, and a recap of its recommendations. The approaches can be roughly divided into three categories. The first approach focuses on tools for reproducible computation ranging from “statistical documents” (incorporating Knuth’s [1992] concept of literate programming) to workflow systems and reproducible computing environments [for example, Buckheit & Donoho 1995; Schwab et al. 2000; Leisch & Rossini 2003; Deelman & Gils 2006; Gentleman & Temple-Lang 2007] With few exceptions [notably, Freire, et al. 2006] this focuses primarily on “simple replication” or “reproduction” –replicating exactly a precise set of result from an exact copy of original data made at the time of research. Current leading examples of tools that support reproducible computation include:Ipython: ipython.orgKnitryihui.name/knitr/Research Compendia researchcompendia.orgRun My Code runmycode.orgVistrailsvistrails.orgThe second approach focuses on data sharing methods and tools [see for example, Altman et al 2001; King 2007; Anderson et al., 2007; Crosas 2011]. This approaches more generally on helping researchers to share -- both for replication and for broader reuse – including secondary uses and use in teaching. Increasingly work in this area [e.g. Gutmann 2009; Altman-King 2007] focuses on issues of enabling long-term and interdisciplinary access to data – this requires that the researchers’ tacit knowledge about data formats, measurement, structure and provenance be more explicitly documented. Also see for example the CRAN reproducible research task view: ; and the Reproducible Research tools page: http://reproducibleresearch.net/index.php/RR_links#ToolsCurrent leading examples of informatics tools that support data sharing include:CKAN ckan.orgData dryad datadryad.orgDataverse Network thedata.orgFigsharefigshare.comThe third approach focuses on the norms, practices and licensing associated with data sharing archiving and replication and the related incentives embedded in scholarly communication [Pienta 2007; Hamermesh 2007; Altman & King 2007; King 2007; Hedstrom et al. 2008; McCullough 2009; Stodden 2009]. This approach seeks to create the necessary conditions to enable data sharing and reuse, and to examine and align citations around citation, data sharing, and peer review to encourage replicability and reusability.Current leading examples of informatics tools that support richer citation, evaluation, open science, and review include:Data Cite datacite.orgData dryad datadryad.orgDataverse Network thedata.orgDMPTOOL dmp.cdlib.org/Figsharefigshare.comJournal of Visual Experiments jove.comORCID: Orcid.orgResearch Replication Reports http://www.psychologicalscience.org/index.php/replicationThomson Reuters Data Citation Index wokinfo.com/products_tools/multidisciplinary/dci/Many Tools, Few SolutionsIn this area, there are many useful tools, but few solutions that offer a complete solution – even for a specialized community of practice. All three approaches are useful, and here are several general observations to be made about them. First, tools for replicable research such as VisTrails, MyExperiment, Wings, and StatDocs are characterized by their use of a specific and controlled defined software framework and their ability to facilitate near automatic replication. The complexity of these tools, and their small user and maintenance base means that we cannot rely on them to exist and function in five-ten years – they cannot ensure long term access. Because they focus only on results and not on capturing practices, descriptive metadata and documentation, they allow exact replication without providing the contextual information necessary for broader reuse. Finally these tools are heterogeneous across subdisciplines, and largely incompatible, they do not as yet offer a broadly scalable solution.Second, tools and practices for data management have the potential to broadly increase data sharing and the impact of related publications However, although these tools are becoming easier to use, they still require an extra effort for the researcher. Moreover, since additional effort often comes near (or past) the conclusion of the main research project (and only after acceptance of an article and preparation for final publication) it is perceived as a burden, and often honored in the breach. Third, incentives for replication have been weak in many disciplines – and journals are a key factor. The reluctance of journal editors to publish articles either confirming or non-confirming replications work authors’ incentives to create replicable work. Lack of formal provenance and attribution practices for data also weakens accountability, raises barriers to conducting replication and reuse, reduces incentive to disseminate data for reuse, and increases the ambiguity of replication studies, making them difficult to study. Furthermore, new forms of evidence complicate replication and reuse. In most scientific disciplines, the amount of data potentially available for research is increasing non-linearly. In addition, changes in technology and society are greatly affecting the types and quantities of potential data available for scientific analysis, especially in the social sciences. This presents substantial challenges to the future replicability and reusability of research. Traditional data archives currently consist almost entirely of numeric tabular data from noncommercial sources. New forms of data differ from tabular data in size, format, structure, and complexity. Left in its original form, this sort of data is difficult or for scholars outside of the project that generated it to interpret and use. This is a barrier to integrative and interdisciplinary research, but also a significant obstacle to providing long-term access, which becomes practically impossible as the tacit knowledge necessary to interpret the data is forgotten. To enable broad use and to secure long term access requires more than simply storing the individual bits of information – it requires establishing and disseminating good data management practices. [Altman & King 2007] How research libraries can jump-start the process.Many research libraries should consider at least three steps:First, create a dataverse hosted by the Harvard Dataverse Network (http://thedata.harvard.edu/dvn/faces/login/CreatorRequestInfoPage.xhtml ). This provides free, permanent storage, dissemination, with bit-level preservation insured by Harvard’s endowment. The dataverse can be branded, curated, and controlled by the library – so it enables libraries to maintain relationship with their patrons, and provide curation services, with minimal effort. (And since DVN is open-source, a library can always move from the hosted service to one they run themselves.Second, link to DMPTool (https://dmp.cdlib.org/) from your libraries website. And consider joining DMPTool as an institution – especially if you use Shibboleth (Internet2) to authorize your users. You’ll be in good company -- according to a recent ARL survey 75% of ARL libraries are now at least linking to DMPTool. Increasing researchers use of DMPtool provides early opportunities for conversation with libraries around data, enables libraries to offer service at a time when it is salient to the researcher , and provides a information which can be used to track and evaluate data management planning needs. Third, design a libguide to help researchers get more credit for their work. This is a subject of intense interest, and the library can provide information about trends and tools in the area that researchers (especially junior researchers) of which researchers may not be aware. Some possible topics to include: Data citation(e.g. the http://www.force11.org/node/4769 ); researcher identifiers (e.g., http://orcid.org ); and impact metrics (http://libraries.mit.edu/scholarly/publishing/impact) .ReferencesAltman, M., L. Andreev, M. Diggory, M. Krot, G. King, D. Kiskis, A. Sone, S. Verba, A Digital Library for the Dissemination and Replication of Quantitative Social Science Research, Social Science Computer Review 19(4):458-71. 2001.Altman, M. and G. King. "A Proposed Standard for the Scholarly Citation of Quantitative Data", D-Lib Magazine 13(3/4). 2007.Anderson, R. W. H. Greene, B. D. McCullough and H. D. Vinod. "The Role of Data/Code Archives in the Future of Economic Research,” Journal of Economic Methodology. 2007.Buckheit, J. and D.L. Donoho,Wavelan and Reproducible Research, in A. Antoniadis (ed.) Wavelets and Statistics, Springer-Verlag. 1995.Crosas, M., The Dataverse Network®: An Open-Source Application for Sharing, Discovering and Preserving Data, D-lib Magazine 17(1/2). 2011.D.S. Hamermesh, “Viewpoint: Replication in Economics,” Canadian Journal of Economics. 2007.Deelman, E. Y. Gil, (Eds.). Final Report on Workshop on the Challenges of Scientific Workflows. 2006. <http://vtcpc.isi.edu/wiki/images/b/bf/NSFWorkflow-Final.pdf>Freire, J., C. T. Silva, S. P. Callahan, E. Santos, C. E. Scheidegger, and H. T. Vo. Managing rapidly-evolving scientific workflows. In International Provenance and Annotation Workshop (IPAW), LNCS 4145, 10-18, 2006.Gentleman R., R. Temple Lang. Statistical Analyses and Reproducible Research, Journal of Computational and Graphical Statistics 16(1): 1-23. 2007.Gutmann M., M. Abrahamson, M. Adams, M. Altman, C. Arms, K. Bollen, M. Carlson, J. Crabtree, D. Donakowski, G. King, J. Lyle, M. Maynard, A. Pienta, R. Rockwell, L. Timms-Ferrara, C. Young, "From Preserving the Past to Preserving the Future: The Data-PASS Project and the challenges of preserving digital social science data", Library Trends 57(3):315-337. 2009.Hedstrom, Margaret, JinfangNiu, Kaye Marz,. “Incentives for Data Producers to Create “Archive/Ready” Data: Implications for Archives and Records Management”, Proceedings of the Society of American Archivists Research Forum. 2008.King, G. “An Introduction to the Dataverse Network as an Infrastructure for Data Sharing.” Sociological Methods and Research, 32(2), 173–199. 2007.Knuth, D.E., Literate Programming, CLSI Lecture Notes 27. Center for the Study of Language and Information. Stanford, Ca. 1992.Leisch F., and A.J. Rossini, Reproducible Statistical Research, Chance 16(2): 46-50. 2003.McCullough, B.D., Open Access Economics Journals and the Market for Reproducible Economic Research, Economic Analysis & Policy 39(1). 2009. Pienta, A., LEADS Database Identifies At-Risk Legacy Studies, ICPSR Bulletin 27(1) 2006.Schwab, M., M. Karrenbach, and J. Claerbout, Making Scientific Computations Reproducible, Computing in Science and Engineering 2: 61-67. 2000.Stodden, V.The Legal Framework for Reproducible Scientific Research: Licensing and Copyright, Computing in Science and Engineering 11(1):35-40. 2009.
- 5 Minutes
- 5 Minutes
- LHC produces a PB every 2 weeks, Sloan Galaxy zoo has hundreds of thousands of “authors”, 50K people attend a class from the University of michigan, and to understand public opinion instead of surveying 100’s of people per month we can analyze 10ooo tweets per second.
- 5 Minutes
- 5 Minutes
- 5 Minutes
- 5 Minutes
- 5 Minutes
- 5 Minutes
- 5 Minutes
- 5 Minutes
- 5 Minutes
- Most of the different stakeholders have stronger relationships/stakes with research at different stages. But researchers and research institutions are in the middle – they have a strong stake in most stagesResearchers are more directly concerned with collection, processing, analysis, dissemination. Organizations have a higher stake in internal sharing, re-use, long-term access.
- 5 Minutes