Pronk like you mean it
•
1 gostou•2,324 visualizações

Slides from my invited talk at IFL 2011 (the Symposium On Implementation And Application Of Functional Languages) in Lawrence, Kansas.
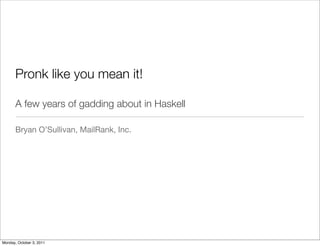
![pronk |prô ng k; prä ng k|
verb [ intrans. ]
(of a springbok or other antelope) leap in the air with an arched back and
stiff legs, typically as a form of display or when threatened.
ORIGIN late 19th cent.: from Afrikaans, literally ‘show off,’ from Dutch
pronken ‘to strut.’
Monday, October 3, 2011](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recomendados
Mais conteúdo relacionado
Destaque
Destaque (19)
Semelhante a Pronk like you mean it
Semelhante a Pronk like you mean it (20)
Mais de Bryan O'Sullivan
Mais de Bryan O'Sullivan (9)
Último
Último (20)
Pronk like you mean it
- 1. Pronk like you mean it! A few years of gadding about in Haskell Bryan O’Sullivan, MailRank, Inc. Monday, October 3, 2011
- 2. pronk |prô ng k; prä ng k| verb [ intrans. ] (of a springbok or other antelope) leap in the air with an arched back and stiff legs, typically as a form of display or when threatened. ORIGIN late 19th cent.: from Afrikaans, literally ‘show off,’ from Dutch pronken ‘to strut.’ Monday, October 3, 2011
- 3. Pronking as it is practiced in the wild. Monday, October 3, 2011
- 4. “Someone ought to do something!” • I re-entered the Haskell world in the mid-2000s • At the time, I noticed the lack of “the kind of book I want to read” • After several months of concentrated wishful thinking... still no book! • So... I found some collaborators and wrote the book I wished I had: • Real World Haskell, http://realworldhaskell.org/ Monday, October 3, 2011
- 5. 2.5 years of free online access • Nearing a million visits, and still growing! book.realworldhaskell.org Mar 31, 2009 - Sep 30, 2011 Visitors Overview Comparing to: Site Visitors 6,000 6,000 3,000 3,000 0 0 Mar 31 - Apr 4 Aug 30 - Sep 5 Jan 31 - Feb 6 Jul 4 - Jul 10 Dec 5 - Dec 11 May 8 - May 14 299,443 people visited this site 940,409 Visits 299,443 Absolute Unique Visitors 1,981,816 Pageviews 2.11 Average Pageviews 00:02:27 Time on Site Monday, October 3, 2011
- 6. Reader involvement is a big win • We didn’t pioneer comments from readers • But we were the first to do it well 100 75 50 25 0 2009-W13 2009-W24 2009-W35 2009-W46 2010-W05 2010-W16 2010-W27 2010-W38 2010-W49 2011-W07 2011-W18 2011-W29 2011-W40 realworldhaskell.org comments per week Monday, October 3, 2011
- 7. Burnout • “Real World Haskell” was a huge effort • 1,328 commits by 3 people over 15 months • Tons of online comments to read • By the end, I was exhausted • I barely touched a computer for several months Monday, October 3, 2011
- 8. From burnout to fusion • Once I recovered from the RWH burnout effect, I felt a keen irony • Haskell was still not especially “real world” for lots of uses • The most glaring hole (to me): no modern text handling • Coutts and Stewart’s bytestring library was wonderful, but binary-only • They’d since moved on from primitive, fragile fusion to stream fusion Monday, October 3, 2011
- 9. Stream fusion and text • Harper’s MSc thesis took stream fusion and applied it to text processing • I took his MSc work and turned it into the standard Haskell text library • http://hackage.haskell.org/package/text • Now distributed as part of the Haskell platform Monday, October 3, 2011
- 10. From thesis to bedrock • Harper’s MSc tarball: • 1,699 LOC • No tests (and yes, numerous bugs) • Today: • 9,532 LOC • 330 QuickCheck tests, coverage above 90% • Only 3 bugs ever reported “in the wild” Monday, October 3, 2011
- 11. When text isn’t enough • The text API is a small superset of the Haskell list/string API (+10%) • It’s missing a lot of important real-world functionality • So I wrote another package, text-icu, to fill the gaps • Based on idiomatic FFI wrappers around the venerable ICU library Monday, October 3, 2011
- 12. What’s in text-icu? • Unicode normalization (è vs. `+e) • Collation: in some locales, lexicographic ordering differs from simple numeric ordering of code points • Character set support: Big5, Shift-JIS, KOI-8, etc. • Perl-compatible regular expressions (and more besides) Monday, October 3, 2011
- 13. Two data types for different use cases Strict Lazy • An entire string is a single chunk • A string is a list of 64KB chunks • Good for small strings, whole- • Good for single-pass streaming document manipulation • Chunk boundaries are a prolific source of bugs • Nearly twice as much code to maintain Monday, October 3, 2011
- 14. Was this enough? • 6 months into the project, the API was nearing completion • I wanted to start benchmarking, to see whether the code was “good” • Looked on Hackage for a decent benchmarking library • Found nothing :-( Monday, October 3, 2011
- 15. What’s in a benchmarking tool? • A typical benchmarking harness: • Run a function a few times (often configurable) • Print a few statistics (min, max, mean) Monday, October 3, 2011
- 16. Pitfalls for the unwary • Supposing your benchmark harness does something like this: 1.Record the start time 2.Run the thingumbob 3.Record the end time • Looks fine, right? • So... what can go wrong? Monday, October 3, 2011
- 17. Clock resolution and cost • On my Mac, getPOSIXTime has a resolution of 2.15μs (±80ns) • Suppose we can tolerate a 1% error ‣ We cannot naïvely measure anything that runs in less than 200μs • On my system, a call to getPOSIXTime costs 60.5ns ‣ Failure to account for this introduces a further 5% of inaccuracy in the limit Monday, October 3, 2011
- 18. Advice for the 1990s • Longstanding benchmarking advice: • Run on a “quiet” system • This is no longer remotely achievable, so ... forget it? Monday, October 3, 2011
- 19. The impossibility of silence • All modern CPUs vary their performance in response to demand • Contention from input devices, networking gear, that web browser you forgot to quit, you name it • Virtualization introduces interference from invisible co-tenants Monday, October 3, 2011
- 20. That O’Sullivan seems awfully gloomy • Does this mean we should abandon the ideal of a quiet system? • No, but understand that there’s only so much you’ll achieve • What is now very important is to • Measure the perturbation Monday, October 3, 2011
- 21. (Re)introducing the criterion library • The library I wrote to benchmark the text package • Can measure pure functions (strict and lazy) and IO actions • Automates much of the pain of benchmarking • “How many samples do I need for a good result?” • “Can I trust my numbers?” • “What’s the shape of my distribution?” Monday, October 3, 2011
- 22. Sampling safely • We measure clock resolution and cost, then compute the number of samples needed to provide a low measurement error • Samples are corrected for clock cost • A warmup run sets code and data up for reproducible measurements • We can force the garbage collector to run between samples for more stable measurements • We measure wall clock time, not “CPU time consumed by this process” • This lets us handle I/O-bound, networked, and multi-process code Monday, October 3, 2011
- 23. Outliers and the inflated mean • Suppose you launch Call of Duty 3 while benchmarking • This will eat a lot of CPU and memory, and intermittently slow down the benchmarked code • Slower code will show up as outliers (spikes) in time measurements • Enough outliers, and the sample statistics will be inflated, perhaps drastically Monday, October 3, 2011
- 24. Reporting dodgy measurements • Our goal is to identify outliers, but only when they have a significant effect • Outliers that don’t inflate our measurements are not really a problem • We use the boxplot technique to categorize outliers • We report outliers that are perturbing our measurements, along with the extent of the problem (mild, moderate or severe) Monday, October 3, 2011
- 25. Trustworthy numbers • It’s exceptionally rare for measurements of performance to resemble an idealized statistical distribution • The bootstrap is a resampling method for estimating parameters of a statistical sample without knowledge of the underlying distribution • Following Boyer, we use the bootstrap to give confidence intervals on our measurements of the mean and standard deviation Monday, October 3, 2011
- 26. What do measurements look like? • Some sample output from a criterion benchmark of the Builder type: • mean: 4.855 ms (lb 4.846 ms, ub 4.870 ms) • std dev: 57.9 μs (lb 39.6 μs, ub 93.5 μs) • Builder is a type we provide to support efficient concatenation of many strings (for formatting, rendering, and such) Monday, October 3, 2011
- 27. Resampling revisited • The bootstrap requires repeated pseudo-random resampling with replacement • Resampling: given a number of measurements, choose a subset at random • Replacement: okay to choose the same measurement more than once in a single resample • Since we resample a collection of measurements many times, PRNG performance becomes a bottleneck Monday, October 3, 2011
- 28. Fast pseudo-random number generation • The venerable random package is not very fast • So I wrote an implementation of Marsaglia’s MWC8222 algorithm • mwc-random is up to 60x faster than random • mwc-random: 19.96ns per 64-bit Int (about 50,000,000 per second) • random: 1227.51ns per 64-bit Int Monday, October 3, 2011
- 29. Truth in advertising • The benchmark for understanding performance measurements is the histogram • “Do I have a unimodal distribution?” • “What are those outliers doing!?” • Histograms are finicky beasts • Choose a good bin size by hand, or else the data will mislead • I know of no good tools for quickly and efficiently fiddling with histograms Monday, October 3, 2011
- 30. Is there something better we can do? • Kernel density estimation is a convolution-based method that gives histogram-like output without the need for hand-tuning • KDEs provide a non-parametric way to estimate the probability density function of a sample • We convolve over a range of points from the sample vector • The size of the convolution window is called the bandwidth Monday, October 3, 2011
- 31. What does a KDE look like? Monday, October 3, 2011
- 32. No hand tuning? • There are long-established methods for automatic choice of bandwidth that will give a quality KDE • Unfortunately, the best known methods smooth multimodal samples too aggressively • But wait, didn’t we just see a KDE with 3+ modes (peaks)? • Soon to come: an implementation of Raykar & Duraiswami’s Fast optimal bandwidth selection for kernel density estimation • Much more robust in the face of non-unimodal empirical distributions; doesn’t oversmooth Monday, October 3, 2011
- 33. For want of a nail • To answer the question of “is the text library fast?”, I built... • ...a benchmarking package, which needed... • ...a statistics library, which needed... • ...a PRNG • After disappearing down that long tunnel, was the library fast? • Not especially - at first Monday, October 3, 2011
- 34. Stream fusion - how did it work out? • Didn’t perform well until SimonPJ rewrote the GHC inliner for 7.0 • Performance is now pretty good • But the model seems to force too much heap allocation • Hand-written code still beats stream fusion • One fair-sized win comes with reusability • We can often share code between the two text representations • The programming model is somewhat awkward Monday, October 3, 2011
- 35. General-purpose statistics wrangling • Since I needed to write other statistical code while working on criterion, I ended up developing the statistics package • Provides a bunch of useful capabilities: • Working with widely used discrete and continuous probability distributions • Computing with sample data: quantile & KDE estimation, bootstrap methods, significance testing, autocorrelation analysis, ... • Random variate generation under several different distributions • Common statistical tests for significant differences between samples Monday, October 3, 2011
- 36. Numerical pitfalls • There are plenty of traps for the unwary in a statistics library • Catastrophic cancellation of small values • Ballooning error margins outside a small range • PRNGs that exhibit unexpected autocorrelation • Example: the popular ziggurat algorithm for normally distributed Double values has subtle autocorrelation problems Monday, October 3, 2011
- 37. What does criterion focus on? • Ease of use: writing and running a benchmark must be as easy as possible • Automation: figure out good run times and sample sizes that lead to quality results without human intervention • Understanding: KDE gives an at-a-glance view of performance without manual histogram tweaking • Trust: criterion inspects its own measurements, and warns you if they’re dubious Monday, October 3, 2011
- 38. What has criterion made possible? • In just a few projects of mine: • At least 28 commits to the text library since Sep 2009 consist of speed improvements measured with criterion • 10 commits to statistics and mwc-random yield measured performance improvements (i.e. using criterion to help speed itself!) • Most importantly to me, the text library now smokes both bytestring and built-in lists at almost everything :-) Monday, October 3, 2011
- 39. Putting the “real” into “real world” • In December of 2010, I started a small company in San Francisco, MailRank • We use machine learning techniques to help people deal with email overload • “Show me my email that matters.” • We put our money where my mouth is: • Our cloud services are written in Haskell Monday, October 3, 2011
- 40. Haskell in the real world • The Haskell community is very lucky to have a fantastic central repository of code in the form of Hackage • It’s a bit of a victim of its own success by now, mind • For commercial users, our community’s widespread use of BSD licensing is very reassuring • Our core library alone depends on 25 open source Haskell libraries • Of these, we developed and open sourced about a dozen Monday, October 3, 2011
- 41. Third party libraries I love • The Snap team’s snap web framework: fast and elegant • The yesod web framework deserves a shout-out for its awesomeness too • Snoyman’s http-enumerator: a HTTP client done right • Tibell’s unordered-containers: blazingly fast hash maps • Van der Jeugt and Meier’s blaze-builder: fast network buffer construction • Hinze and Paterson’s fingertee: the Swiss army knife of purely functional data structures Monday, October 3, 2011
- 42. A few other libraries I’ve written • attoparsec: incremental parsing of bytestrings • aeson: handling of JSON data • mysql-simple: a pleasant client library for MySQL • configurator: app configuration for the harried ops engineer • I tend to focus on ease of use and good performance • By open sourcing, I get a stream of improvements and bug reports Monday, October 3, 2011
- 43. Performance: the inliner • The performance of modern Haskell code is a marvel • But we have become reliant on inlining to achieve much of this • e.g. stream fusion depends critically on inlining • Widespread inlining is troubling • Makes reading Core (to grok performance) vastly harder • Slows GHC down enormously - building just a few fusion-heavy packages can take 20+ minutes Monday, October 3, 2011
- 44. Achieving good performance isn’t always easy • e.g. my attoparsec parsing library is CPS-heavy and GHC generates worse code for it than I’d like... but I don’t know why • Core is not a very friendly language to read, but it’s gotten scary lately with so many type annotations — we need -ddump-hacker-core • Outside of a smallish core of people, lazy and strict evaluation, and their respective advantages and pitfalls, are not well understood • We’ve all seen code splattered with panicky uses of seq and strictness annotations Monday, October 3, 2011
- 45. “Well-typed programs can’t be blamed”? Uh huh? • Let me misappropriate Wadler’s nice turn of phrase • I often can’t figure out where to blame my well-typed program because all I see upon a fatal error is this: *** Exception: Prelude.head: empty list • This is a disaster for debugging Monday, October 3, 2011
- 46. Our biggest weakness • The fact that it’s almost impossible to get automated assistance to debug a Haskell program, after 20 years of effort, remains painful • No post-mortem crash dump analysis • No equivalent to a stack trace, to tell us “this is the context in which we were executing when the Bad Thing happened” • This is truly a grievous problem; it’s the only thing that keeps me awake at night when I think about deploying production Haskell code Monday, October 3, 2011
- 47. What’s worked well for MailRank? • Number of service crashes in 2+ months of closed beta: zero • The server component accepts a pummeling under load without breaking a sweat • Our batch number crunching code is fast and cheap • Builds and deployments are easy thanks to Cabal, native codegen, and static linking Monday, October 3, 2011
- 48. A little bit about education • In spite of recent curriculum changes, FP in general is still getting short shrift for teaching • David Mazières and I have started using Haskell as a language for teaching systems programming at Stanford (tradionally not an FP place) • Instead of teaching just Haskell, we’re teaching both Haskell and systems • As far as I can tell, our emphases on practicality and performance are unique Monday, October 3, 2011
- 49. There’s demand for this stuff! • We’re targeting upper division undergrads and grad students • So far, our class is standing room only • We have several outsiders auditing the class • If you’re in a position to teach this stuff, and to do so with a practical focus, now’s a good time to be doing it! Monday, October 3, 2011
- 50. What’s next? • I’m taking the analytics from criterion and applying them to HTTP load testing • Existing tools (apachebench, httperf) are limited • Difficult to use • Limited SSL support • Little statistical oomph • Thanks to GHC’s scalable I/O manager and http-enumerator, the equivalent in Haskell is easy Monday, October 3, 2011
- 51. Work in progress • My HTTP load tester is named “pronk” • github.com/mailrank/pronk • It’s still under development, but already pretty good • Because it’s open source, I’m already getting bug reports on the unreleased code! Monday, October 3, 2011
- 52. Thank you! Monday, October 3, 2011