Intorduction to the cbo optimizer
•Transferir como DOCX, PDF•
0 gostou•398 visualizações

Intorduction to the cbo optimizer

Recomendados
Mais conteúdo relacionado
Destaque
Semelhante a Intorduction to the cbo optimizer
Semelhante a Intorduction to the cbo optimizer (20)
Mais de Zhaoyang Wang
Mais de Zhaoyang Wang (17)
Intorduction to the cbo optimizer
- 1. Intorduction to the CBO Optimizer 1.结构化查询语言的类型: 1.DML(Data Manipulation Language):INSERT, UPDATE, DELETE, MERGE, SELECT; 2.DDL(Data Definition Language):CREATE, DROP, ALTER, RENAME, TRUNCATE, GRANT, REVOKE, AUDIT, NOAUDIT, COMMENT; 3.ESS(Environmental Sustainability Statement):DECLARE, CONNECT, OPEN, CLOSE, DESCRIBLE, WHENEVER, PREPARE, EXECUTE, FETCH; 4.TCS(Transactoin Control Statement):COMMIT, ROLLBACK, SAVEPOINT, SET TRANSACTION; 5.SystemCS(System Control Statement):ALTER SYSTEM; 6.SessionCS(Session Control Statement):ALTER SESSSION, SET ROLE; 2.SQL 语句的实现过程:相同的 SQL 语句可以使用相同的执行计 划; 3.Cursor
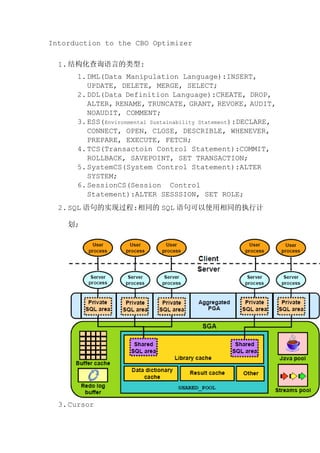
- 2. 1.PL/SQL中的cursor:记录行的rowid,用来表示结果集; 2.sql解析过程中的cursor:是SHARED POOL中的内存块; 4.SQL 语句的处理过程: 1.Create a cursor: 1.Cursor 是 private SQL area 的句柄或者名称; 2.其中包含了语句执行的信息; 3.Cursor 的结构与它包含 SQL 语句是互相独立的; 2.Parse the statement: 1.SQL 语句通过用户进程发送到 Oracle 实例; 2.在 PGA 中检查语法和语义,然后检查权限,分配 private SQL area,然后检查是否已经在 Library Cache 中存在,如果没有的话,会把 sql 放入到 Shared SQL area 中,产生硬解析; 3.如果 SQL 的执行计划已经存在的话可以被重用; 3.Describe query results: 1.提供了 SELECT 后面的要查找的列的信息,与动态执 行 SQL 有关; 2.9i 时使用 DBMS_SQL 包,之后使用 EXECUTE IMMEDIATE 来动态执行 SQL; 4.Define query output:定义要查找的列的位置,大小, 数据类型信息; 5.Bind variables: 1.开启内存地址来保存数据的值; 2.允许共享 sql;
- 3. 6.Parallelize the statement: 1.可以并行的语句:SELECT, INSERT, UPDATE, MERGE, DELETE, CREATE, ALTER; 2.11g 中自动判断是否需要并行; 7.Execute the statement:执行 SQL 语句,产生想要的 结果; 8.Fetch rows of a query:以表格的形式返回数据; 9.Close the cursor:关闭游标,PGA 中指向 cursor 的 指针关闭,但是内存区域还是被占用,之后可以被覆盖; 10. 使用 DBMS_SQL 包可以看到完整的 SQL 执行的过程; 5.SQL 语句解析的过 程; 6.需要优化器的理由:它可以选择一种资源消耗最小的方式;
- 4. 7.硬解析的操作步 骤: 8.Transformer 1.优化器首先会把语句分成一个一个的查询块,然后进行转 换; 2.虽然进行了转换操作以提高效率,但是在内存中保存的还 是原来的 SQL 语句; 3.OR 转换为 UNION ALL 操 作;
- 5. 4.IN 转换为内连接操作 (11g); 5.IN 改写为 exists; 6.NOT IN 改写为外连接+IS NULL,11g 中自动转换,10g 中需要修改; 7.IN 改写为外连接+IS NOT NULL; 8.视图合并:查询的时候直接查询视图中的基表,非常适合于 视图的记录数很大,查询视图的记录数小的情 况; 9.视图不合并:查询时把制图当成基表,这样效率比较 低.CBO 会自动合并第一层的视图,所以不要使用嵌套视 图; 10. Predicate Pushing:把条件推到最查询的最低 端;
- 6. 11. 条件的传递性:employees 的 department_id 列没有 索引,department表department_id列是主键,转换过 之后就会先走主键扫 描; 9.Cost-Based Optimizer 1.由 Estimator 和 Plan Generator 组成; 2.Estimator 决定执行计划的成本消耗的建议; 1.它是基于概率论的,理论依据是数据是均匀分布的; 2.它的基础数据是定期收集并存放在数据字典的统计 信息; 3.Plan Generator: 1.产生各种不同的执行计划; 2.使用 Estimator 计算各个执行计划的成本;
- 7. 3.基于成本选择最好的优化建议; 4.生成最优的执行计划; 4.OPTIMIZER_MODE 的两个参数:ALL_ROWS, FIRST_ROWS_n: 1.FIRST_ROWS_n: 1.CBO 优先考虑将结果集中的前 N 条记录以最快 的速度返回,而其它的结果集并不需要同时返 回; 2.可以使用在 BBS 的分页上:SELECT /*+ first_rows(10) */ FROM tbname; 3.这种执行计划对于SQL整体的执行时间不是最 快的,但是在返回前 N 条记录的处理上绝对是 最快的; 4.使用的排序字段必须有索引,否则 CBO 会忽略 FIRST_ROWS(n),而使用 ALL_ROWS; 2.ALL_ROWS: 1.CBO 考虑最快的速度返回所有的结果集,和 FIRST_ROWS_n 相反; 2.在 OLAP 系统中使用较多,总体效率高; 10. Estimator 1.Selectivity:选择度; 1.Selectivity is the estimated proportion of a row set retrieved by a particular predicate or combination of predicates; 选择度是由一个特定的谓词或者组合谓词检索行集 的估计比例;
- 8. 2.计算公式:Selectivity=满足条件的记录数/总记 录数; 3.它的取值在 0.0-1.0 之间: 1.High Selectivity:得到大比例的记录数; 2.Low Selectivity:得到小比例的记录数; 4.如何获得 Selectivity: 1.如果没有统计信息则采用动态采样(Dynamic Sampling); 2.如果没有直方图信息则采用行分布; 5.存放统计信息的视图: 1.dba_tables; 2.dba_tab_statistics(NUM_ROWS, BLOCKS, AVG_ROW_LEN); 3.dba_tab_col_statistics(NUM_DISTIN CT, DENSITY, HIGH/LOW_VALUE); 2.Cardinality:基数; 1.通过执行计划期望能检索出来的记录数; 2.计算公式:Cardinality=Selectivity*总记录 数; 3.对于 join, filters 和 sort 的成本是重要的指 标; 3.举例:SELECT * FROM hr.employees WHERE job_id = 'SH_CLERK';
- 9. 1.employees 表的 job_id 列的取值个数 为:19; 2.employees 表中的记录 数:107; 3.Selectivity=1/19=0.0526315789473684,即 DENSITY 的值; 4.Cardinality=(1/19)*107=5.63,向上取整为 6; 4.Cost: 1.Cost 是执行特定的语句所花费的标准 I/Os 数量的 最优评估; 2.Cost 的单位是一个标准块的随机读取:1 cost unit = 1 SRds(Standardized Random Reads);
- 10. 3.执行计划中Cost(%CPU):一次IO读取一个 IO 块需 要的时间; 4.Cost 的值由三部分组 成; 11. 控制优化器的初始化参数: 1.CURSOR_SHARING:SIMILAR|EXACT(default)|FORC E,控制可以共享 Cursor 的 SQL 语句类型; 2.DB_FILE_MULTIBLOCK_READ_COUNT:它是一个可以在 表扫描时最小化 IO 的参数,指定了在顺序扫描时一次 IO 操作可以读取的最大的块数;(在 OLTP 系统中一般指定 4-16,在 DW 系统中可以尽量设置的大一点); 3.PGA_AGGREGATE_TARGET:PGA 自动管理时指定 server processes 可以使用的 PGA 内存的总和; 4.STAR_TRANSFORMATION_ENABLED:参数设置为 TRUE 时使用 CBO 可以使用位图索引的特性,不过貌似现在这个 参数不重要; 5.RESULT_CACHE_MODE:MANUAL,FORCE,11g 6.RESULT_CACHE_MAX_SIZE:11g; 7.RESULT_CACHE_MAX_RESULT:11g; 8.RESULT_CACHE_REMOTE_EXPIRATION:11g;
- 11. 9.OPTIMIZER_INDEX_CACHING:在 Buffer Cache 中缓 存索引的比例,默认为 0; 10. OPTIMIZER_INDEX_COST_ADJ:索引扫描/全表扫描 的成本,默认为 100%,即索引扫描成本等于全表扫描成本; 优先会选择全表扫描;比较悲观的配置; 11. OPTIMIZER_FEATURES_ENABLE:希望启用哪个版本 的 CBO; 12. OPTIMIZER_MODE:ALL_ROWS|FIRST_ROWS|FIRST _ROWS_n 1.默认是 all_rows:资源消耗比较小; 2.first_rows_n:n 的取值为 1|10|100|1000,速 度优先,但是消耗很大的资源; 13. OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES; 14. OPTIMIZER_USE_SQL_PLAN_BASELINES; 15. OPTIMIZER_DYNAMIC_SAMPLING:动态采样的特 性,10g 后默认为 2; 16. OPTIMIZER_USE_INVISIBLE_INDEXES; 17. OPTIMIZER_USE_PENDING_STATISTICS; 12. OPTIMIZER_INDEX_COST_ADJ 参数设置的例子:
- 12. 1.首先创建表,索引,并收集统计信 息; 2.打开执行计划,执行查询语句,默认的值为 100%,即索引扫 描成本等于全表扫描成本,则执行计划走全表扫 描; 3.修改参数值为 50,即索引扫描成本是全表扫描成本的 1/2, 查看执行计
- 13. 划; 13. Selectivity 值的例子: 1.因为 CBO 是基于数据均匀的概率分布的,所以它估计的 Selectivity 是一个理论值; 2.创建一个 1200 条记录的表,里面的值分布是 1-12,代表 1-12 月出生的
- 14. 人; 3.如果要查找某个月份出生的人,那么在不明白任何情况下, 每个月份出生的人的概率都是 1/12,即有 100 个人,CBO 也是这么思考问题 的; 4.实际值往往跟理论值不相符,但是数据量越大,越接 近;
- 15. 14. 10053 事件测试: 1.开启 10053 事件,并执行一条 sql 语 句; 2.查看当前的 session_id 和 process_id 来确定生成的 内容是放在哪个 udump 文件 中; 3.查看 udump 文件,里面包含了一些缩写的含义和当前生效 的优化参数的 值; 4.关闭 10053 事 件;
- 16. -- Estimator 例子的脚本; SELECT * FROM hr.employees WHERE job_id = 'SH_CLERK'; SELECT COUNT(DISTINCT job_id) FROM hr.employees; SELECT owner, table_name, column_name, num_distinct, density FROM dba_tab_col_statistics WHERE owner = 'HR' AND table_name = 'EMPLOYEES' AND column_name = 'JOB_ID'; SELECT owner, table_name, num_rows, blocks, avg_row_len FROM dba_tab_statistics WHERE owner = 'HR' AND table_name = 'EMPLOYEES'; -- OPTIMIZER_INDEX_COST_ADJ 参数的例子; CREATE TABLE t1 AS SELECT MOD(ROWNUM, 200) n1, MOD(ROWNUM, 200) n2 FROM dba_objects WHERE ROWNUM <= 3000; CREATE INDEX t_i1 ON t1(n1); EXEC dbms_stats.gather_table_stats(USER, 't1', CASCADE=>TRUE); SET autotrace traceonly exp; SELECT * FROM t1 WHERE n1 = 50; ALTER SESSION SET optimizer_index_cost_adj = 50; SELECT * FROM t1 WHERE n1 = 50; -- Selectivity 的例子; CREATE TABLE t2(ID, month_id) AS SELECT ROWNUM, trunc(dbms_random.value(1, 13)) FROM dba_objects WHERE ROWNUM <= 1200; EXEC dbms_stats.gather_table_stats(USER, 't2', CASCADE => TRUE); SET autotrace traceonly exp;
- 17. SELECT * FROM t2 WHERE month_id = 5; SELECT COUNT(*) FROM t2 WHERE month_id = 5; -- 10053 时间测试例子; ALTER SYSTEM/SESSION SET EVENTS '10053 trace name context forever, level 8'; SELECT * FROM employees WHERE employee_id = 100; ALTER SYSTEM/SESSION SET EVENTS '10053 trace name context off'; SELECT s.sid, p.spid FROM v$session s INNER JOIN v$process p ON s.paddr = p.addr AND s.sid = (SELECT sid FROM v$mystat WHERE ROWNUM = 1);